


Unlocking Growth: Essential Principles of Scalable Architecture Design
Platform Category: Data Platform Architecture
Core Technology/Architecture: Horizontal Scaling, Decoupling Compute and Storage, Asynchronous Communication
Key Data Governance Feature: Centralized Data Catalog
Primary AI/ML Integration: Elastic Compute for Model Training and Inference
Main Competitors/Alternatives: Vertical Scaling / Monolithic Architecture
Scalable Architecture Design is the bedrock for any modern system aiming to endure and thrive amidst ever-increasing user demand and data volumes. It’s not merely about reactive fixes but a proactive strategic approach to system development that ensures agility, resilience, and cost-efficiency. This article delves into the fundamental principles and practical considerations that underpin effective scalable architecture, providing a comprehensive guide for architects and engineers navigating the complexities of high-growth environments.
Introduction: The Imperative of Scalable Architecture Design
In today’s fast-paced digital landscape, applications and data platforms are under constant pressure to perform, expand, and adapt. From e-commerce giants handling Black Friday surges to AI models processing petabytes of data, the ability of a system to grow gracefully without compromising performance or stability is paramount. This is where robust Scalable Architecture Design becomes indispensable. It’s the art and science of engineering systems that can efficiently handle increased load, data, or functionality without requiring a complete overhaul. For World2Data.com, understanding and implementing these principles is crucial for building data platforms that can serve future AI/ML demands, ensure data quality, and provide seamless access to insights. This deep dive will explore the architectural pillars that enable true scalability, ensuring that systems are not just operational today, but future-proof for tomorrow’s challenges.
Core Breakdown: Deconstructing Scalable Architecture Principles
Effective Scalable Architecture Design is built upon several foundational principles, each contributing to a system’s ability to handle growth gracefully. These principles address various layers of the architecture, from infrastructure to application logic and data management.
Embracing Horizontal Versus Vertical Scaling
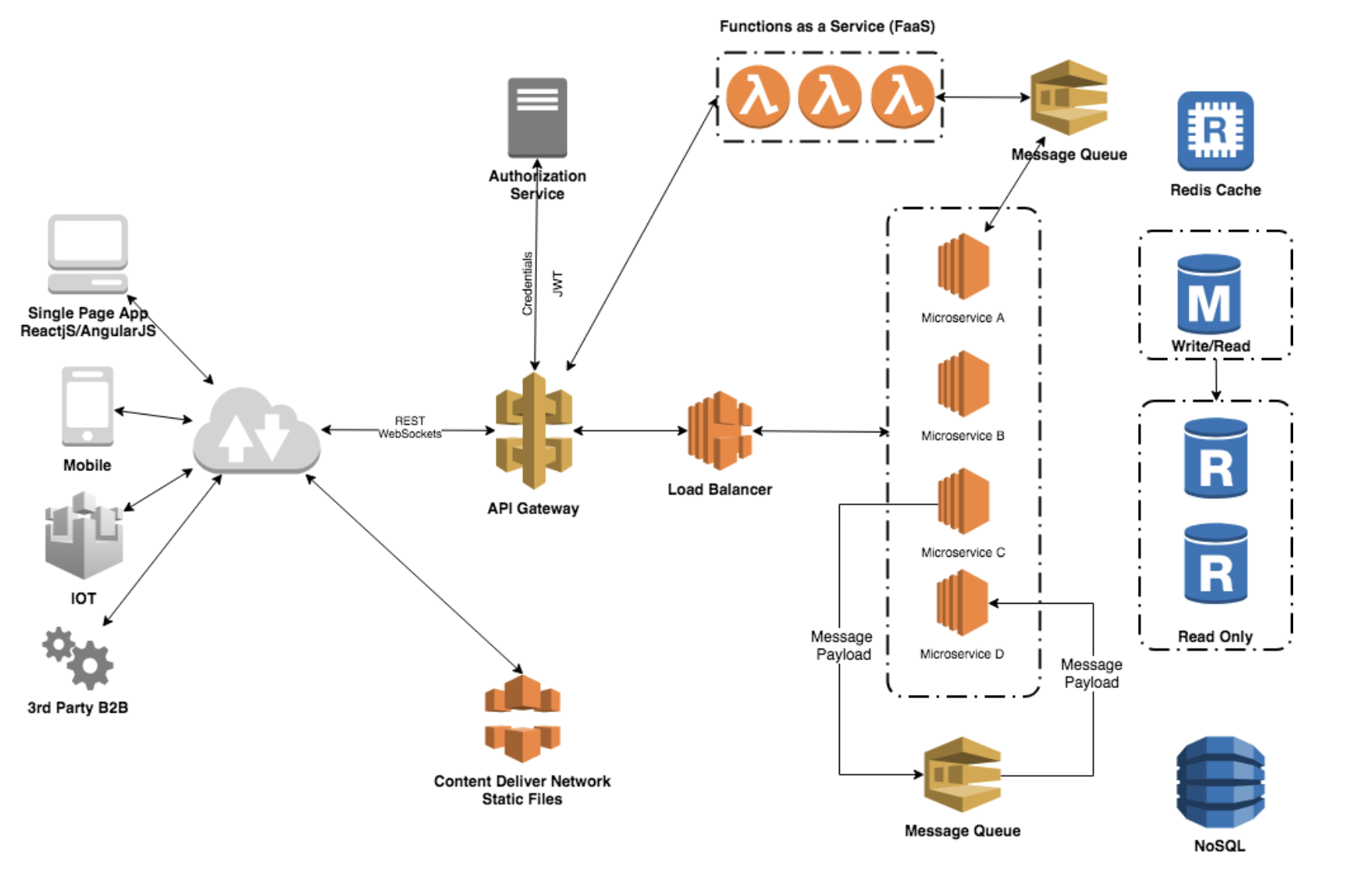
Scaling strategies are crucial for handling growth effectively. The choice between horizontal and vertical scaling significantly impacts a system’s resilience, cost, and ultimate capacity. Horizontal scaling involves adding more machines or instances to your resource pool, distributing the load across multiple, often commodity, servers. This approach inherently leads to higher resilience and better fault tolerance; if one server fails, others can pick up the slack, maintaining service continuity. It’s often more cost-effective in the long run as it leverages distributed computing rather than expensive, high-end hardware. Conversely, vertical scaling means upgrading existing machines with more powerful components—more RAM, faster CPUs, larger storage. While simpler to implement initially, vertical scaling eventually hits hardware ceilings and can become prohibitively expensive for significant growth, often leading to single points of failure. For a true Scalable Architecture Design, horizontal scaling is almost always the preferred strategy, offering virtually limitless potential for expansion.
Promoting Statelessness and Decoupling Compute and Storage
A cornerstone of truly scalable systems is statelessness. In a stateless architecture, each request from a client to a server contains all the information needed to understand the request, and the server does not store any session-specific data from previous requests. Eliminating session affinity means that any server can handle any request, simplifying load balancing significantly and preventing single points of failure tied to specific server states. This principle extends to decoupling compute and storage, a critical aspect of modern data platform architecture. By separating the processing layer from the data persistence layer, each component can scale independently. Compute resources can be added or removed based on processing demand (e.g., for model training or inference in AI/ML workloads), while storage can expand separately as data volumes grow. This architectural choice enhances flexibility, optimizes resource utilization, and significantly improves resilience against failures.
Microservices architecture and loose coupling further enhance this by breaking down monolithic applications into independent, smaller services that can be scaled, updated, and deployed independently. Each microservice typically manages its own data and operates without tight dependencies on others, minimizing the blast radius of failures and increasing overall system agility and development velocity.
Implementing Data Partitioning and Replication
Data management presents unique scaling challenges that must be addressed upfront in any Scalable Architecture Design. Leveraging sharding for database performance distributes data across multiple database servers, preventing a single server from becoming a bottleneck. This technique dramatically improves read and write speeds by parallelizing data access. For instance, customer data might be sharded by geographic region or customer ID, ensuring that individual database servers handle only a subset of the total data, allowing for horizontal scalability of the data layer itself. Beyond performance, ensuring redundancy for high availability through data replication across different geographical locations or data centers protects against data loss and service interruptions. Replication guarantees continuous operation even if some components or entire data centers fail, providing robust disaster recovery capabilities and enhancing data durability. A centralized data catalog becomes crucial here for managing distributed data, ensuring discoverability, and maintaining data governance across these partitioned and replicated datasets.
Optimizing with Asynchronous Communication
Asynchronous communication models significantly improve scalability and responsiveness, especially in distributed systems. Utilizing message queues for responsiveness allows different parts of a system to communicate without direct, real-time dependencies. Tasks can be placed into a queue and processed by workers in the background, without blocking the main application flow or requiring the sending service to wait for a response. This pattern is fundamental for handling peak loads, smoothing out spikes in traffic, and preventing bottlenecks. For example, processing image uploads or sending email notifications can be offloaded to message queues. Designing event-driven architectures builds upon this, where services react to events (e.g., “user registered,” “order placed”) rather than direct requests. This creates a more flexible, loosely coupled, and resilient system that can handle unpredictable loads efficiently and adapt to changing business logic without extensive re-engineering.
The Role of Monitoring and Automation
Continuous monitoring and automation are indispensable for maintaining a scalable architecture. Proactive system health checks, performance metrics, and alerts allow teams to identify and address potential issues before they impact users. This real-time visibility is critical for performance tuning, capacity planning, and ensuring optimal resource utilization. For instance, monitoring CPU usage, memory consumption, network latency, and database query times can reveal bottlenecks that need scaling. Furthermore, auto-scaling and infrastructure as code (IaC) principles enable systems to automatically adjust resources based on demand, eliminating manual intervention. IaC tools like Terraform or CloudFormation allow infrastructure to be provisioned and managed via code, ensuring consistency and reproducibility. Auto-scaling groups in cloud environments automatically add or remove instances based on predefined metrics, ensuring that the system always has the right amount of compute power, which is key for a truly dynamic and responsive environment, especially for elastic compute required for AI/ML model training and inference.
Challenges and Barriers to Adoption
While the benefits of Scalable Architecture Design are clear, several challenges can impede its successful adoption and implementation. One significant barrier is the inherent complexity of distributed systems. Managing multiple services, databases, and communication channels requires sophisticated tooling for monitoring, logging, and tracing. Debugging issues across microservices can be far more challenging than in a monolithic application. Data consistency across distributed databases, especially with sharding and replication, introduces complexities around eventual consistency and transaction management. Maintaining data integrity and ensuring that all parts of the system see a consistent view of the data can be a non-trivial engineering feat. Furthermore, the operational overhead associated with a highly distributed and scalable system can be substantial. Teams need robust MLOps practices, advanced deployment pipelines, and a deep understanding of cloud-native technologies. Security also becomes a multi-faceted concern, requiring granular access controls and secure communication between numerous services. Finally, migrating from an existing monolithic or vertically scaled system to a horizontally scalable, decoupled architecture is a significant undertaking, often requiring a “strangler pattern” approach to incrementally refactor components.
Business Value and ROI of Scalable Architecture Design
Investing in thoughtful Scalable Architecture Design yields significant business value and a compelling return on investment (ROI). Firstly, it ensures business continuity and high availability. By designing systems that can withstand failures and scale under load, businesses can avoid costly downtime, reputational damage, and lost revenue. For World2Data.com, this translates to uninterrupted data access and reliable AI model serving. Secondly, scalability enables faster innovation and time-to-market. Decoupled services allow development teams to work independently, deploy features more frequently, and experiment rapidly without impacting the entire system. This agility is critical for staying competitive and responding to market changes. Thirdly, it optimizes operational costs. Horizontal scaling on commodity hardware and auto-scaling capabilities mean resources are consumed only when needed, reducing infrastructure expenses compared to over-provisioning for peak capacity. For AI/ML workloads, elastic compute ensures that expensive GPU resources are only active during training or critical inference periods. Lastly, a scalable architecture enhances customer experience. Users benefit from consistent performance, fast response times, and an always-available service, leading to increased satisfaction and loyalty. High data quality for AI, enabled by robust data platforms, directly translates to more accurate models and better business outcomes.
Comparative Insight: Scalable Architecture vs. Traditional Monolithic Systems
The contrast between modern Scalable Architecture Design and traditional monolithic systems highlights the paradigm shift in software development. A monolithic application is typically built as a single, indivisible unit. All components—user interface, business logic, data access layer—are tightly coupled and run within a single process. While simpler to develop and deploy in the early stages of a project, monoliths quickly encounter limitations as they grow. Scaling a monolithic application often means vertically scaling the entire application, which is expensive and eventually hits physical hardware limits. A single bug or failure in one component can bring down the entire system. Furthermore, technology stack choices are locked in, making it difficult to adopt new languages or frameworks for specific functionalities. Updates and deployments become risky and time-consuming, requiring the entire application to be re-tested and redeployed even for minor changes.
In stark contrast, a scalable architecture, particularly one employing microservices, is characterized by its distributed, loosely coupled nature. Services are independent, communicate asynchronously, and can be scaled, deployed, and updated individually. This allows for horizontal scaling, where compute and storage can be decoupled and scaled independently, offering far greater flexibility and cost-efficiency. Fault isolation is a key benefit: a failure in one service typically does not cascade to the entire system. Teams can choose the best technology stack for each service, fostering innovation and leveraging specialized tools. For a Data Platform Architecture, this distinction is even more pronounced. A monolithic data warehouse might struggle with diverse data types, real-time ingestion, and elastic compute for complex AI/ML tasks. A scalable data platform, built on principles of decoupling, distributed storage (like data lakes), and elastic compute, can handle these challenges with ease, supporting everything from batch processing to real-time analytics and advanced machine learning workloads.

World2Data Verdict: Embracing Evolutionary Scalability
For organizations like World2Data, the verdict is clear: embracing a future-proof Scalable Architecture Design is not optional, but an absolute necessity. The principles of horizontal scaling, statelessness, decoupled compute and storage, asynchronous communication, and robust monitoring are the foundational elements for building resilient, performant, and cost-effective data platforms ready for the age of AI. We recommend an evolutionary approach to scalability. Start with a minimum viable architecture, but design with these core principles in mind from day one. Continuously monitor performance, identify bottlenecks, and incrementally refactor components to be more scalable. Future predictions indicate a continued convergence of data platforms with AI/ML operations, demanding architectures that are inherently elastic, highly available, and capable of managing massive, diverse datasets. Proactive adoption of these scalable design principles will ensure that data platforms remain agile, adaptable, and a competitive advantage in a data-driven world.

{kind=link}