


Redis in Real-Time Data Processing: Unlocking Immediate Insights with Redis Real-Time Data
Platform Category: In-Memory Data Store / Message Broker
Core Technology/Architecture: In-Memory Key-Value Store, Open Source
Key Data Governance Feature: Role-Based Access Control (ACLs)
Primary AI/ML Integration: Built-in model serving (RedisAI)
Main Competitors/Alternatives: Apache Kafka, RabbitMQ, Memcached, Amazon ElastiCache
Redis in Real-Time Data Processing transforms how organizations manage and extract value from dynamic information. The relentless need for immediate insights from vast datasets, often referred to as Redis Real-Time Data, drives businesses to adopt high-performance solutions capable of handling data velocity and volume with unparalleled efficiency. By providing sub-millisecond response times, Redis enables applications to react instantly to events, fueling a new generation of data-driven services and operational intelligence.
The Critical Demand for Real-Time Insights and Redis’s Role
In today’s hyper-connected digital landscape, the ability to process, analyze, and react to data in real-time is no longer a luxury but a strategic imperative. From e-commerce platforms personalizing user experiences on the fly to financial institutions detecting fraud in milliseconds, immediate data access dictates competitive advantage. This demand fuels the adoption of solutions like Redis, which excels in delivering Redis Real-Time Data for instantaneous business agility.
Achieving instant business agility hinges on processing data as it arrives, enabling instantaneous decision-making across diverse operations. This might involve updating inventory counts the moment a sale occurs, tracking user behavior for immediate content recommendations, or monitoring IoT sensor data for predictive maintenance. Gaining a competitive edge through speed means businesses can respond swiftly to market shifts, customer needs, or emerging threats, making instantaneous data processing a strategic necessity.
Redis stands out as a foundational technology in this pursuit. Its core design principles are centered around speed and efficiency, making it an ideal choice for scenarios where data latency is unacceptable. As we delve deeper, we will explore the architectural prowess of Redis, its versatile applications, and how it addresses the complex challenges of real-time data environments, solidifying its position as a cornerstone for modern data platforms.
Core Breakdown: Redis’s Architecture and Power for Real-Time Data Processing
Redis’s prominence in real-time data processing stems from its unique architectural design and a rich set of features that cater specifically to high-velocity data needs. Its in-memory nature combined with efficient data structures provides a robust foundation for building responsive and scalable applications.
Redis’s Architectural Advantages for Speed
At its heart, Redis leverages an in-memory architecture for unrivaled speed. Storing data directly in RAM minimizes disk I/O, ensuring that most operations execute with exceptionally low, microsecond latency. This fundamental design choice eliminates the bottlenecks associated with disk-based storage, making Redis incredibly fast for both reads and writes.
Beyond memory, Redis offers a versatile collection of data structures, each optimized for specific use cases and high throughput. These include:
- Strings: Basic key-value pairs, often used for caching and simple counters.
- Hashes: Ideal for storing objects with multiple fields, like user profiles.
- Lists: Ordered collections, perfect for message queues, timelines, and recent item lists.
- Sets: Unordered collections of unique strings, useful for tracking unique visitors or relationships.
- Sorted Sets: Sets where each member is associated with a score, enabling leaderboards, ranking, and time-series data.
- Streams: An append-only log data structure, supporting powerful consumer group processing for real-time event sequences.
- Geospatial Indexes: For storing and querying location data efficiently.
These specialized data structures allow developers to model real-world problems efficiently, maximizing performance without the overhead of complex database queries.
Redis as a Low-Latency Feature Store for AI/ML
In the realm of Artificial Intelligence and Machine Learning, Redis has emerged as a critical component, particularly as a low-latency feature store. Machine learning models, especially those requiring real-time inference, depend on immediate access to up-to-date features. Redis excels here by:
- Serving Real-time Features: It can store pre-computed or live-computed features, delivering them to models with sub-millisecond latency during inference. This is crucial for personalization, fraud detection, and recommendation engines.
- Online Feature Engineering: Complex features derived from streaming data can be computed and stored in Redis, ready for consumption by models.
- Minimizing Training-Serving Skew: By using the same Redis instance for both feature generation (or caching) during model training and serving during inference, organizations can reduce discrepancies that lead to model performance degradation.
While Redis does not directly perform data labeling, it can significantly enhance the data labeling workflow by storing metadata, managing queues of data awaiting labeling, or providing a temporary, high-speed repository for human-in-the-loop feedback mechanisms.
Optimizing Application Performance Through Caching
As an efficient caching layer, Redis significantly boosts application responsiveness and reduces the load on primary databases. By storing frequently accessed data, database offloading and scalability are vastly improved. This translates directly to enhancing user experience with fast content delivery, managing user sessions, and accelerating dynamic content rendering, ensuring fluid performance even during peak traffic.
Real-Time Stream Processing with Redis
Redis offers robust features for stream processing, forming the backbone of event-driven architectures. Its Pub/Sub messaging facilitates instant, low-latency communication between distributed components, crucial for microservices and real-time event notification systems. Furthermore, Redis Streams provide an advanced, persistent, log-like data structure, enabling powerful consumer group processing. This allows multiple consumers to reliably consume and react to real-time event sequences, ensuring no data is missed and processing can be scaled horizontally.
Challenges and Barriers to Adoption for Redis Real-Time Data
Despite its immense advantages, implementing Redis for Redis Real-Time Data processing comes with its own set of challenges:
- Memory Management and Cost: As an in-memory database, RAM is more expensive than disk storage. Scaling Redis to manage massive datasets requires careful memory planning and can incur significant hardware costs.
- Data Size Limitations: While Redis Enterprise offers options for larger datasets, a single open-source Redis instance traditionally limits the dataset size to the available RAM. Effective sharding (Redis Cluster) is necessary for larger scale.
- Operational Complexity: Deploying, managing, and scaling Redis for high availability and fault tolerance (e.g., setting up master-replica configurations, Sentinel for automatic failover, or Redis Cluster) adds operational complexity.
- Persistence Overhead: While primarily in-memory, Redis offers persistence options (RDB snapshots, AOF log). These mechanisms, while crucial for data durability, can introduce I/O overhead and latency if not configured optimally.
- Data Governance and Security: Implementing robust role-based access control (ACLs), data encryption, and auditing for real-time data streams requires careful configuration and integration within an existing data governance framework.
Addressing these challenges requires a clear understanding of Redis’s capabilities and limitations, along with a well-defined architectural strategy.
Business Value and ROI of Leveraging Redis
The return on investment (ROI) from adopting Redis for real-time data processing is substantial:
- Faster Model Deployment: By providing a low-latency feature store, Redis accelerates the deployment of real-time AI/ML models, bringing new intelligent services to market quicker.
- Enhanced User Experience: Caching frequently accessed data and enabling real-time personalization leads to snappier applications and highly relevant content, improving user engagement and satisfaction.
- Reduced Operational Costs: Offloading primary databases from heavy read loads can reduce infrastructure costs for traditional relational databases, extending their lifespan and improving their performance.
- Enabling New Real-Time Applications: Redis empowers organizations to build entirely new classes of applications that rely on immediate data, such as live analytics dashboards, real-time fraud detection, gaming leaderboards, and IoT data ingestion.
- Improved Data Quality for AI: By ensuring features are served consistently and quickly, Redis contributes to higher quality inputs for AI models, leading to more accurate predictions and better model performance.
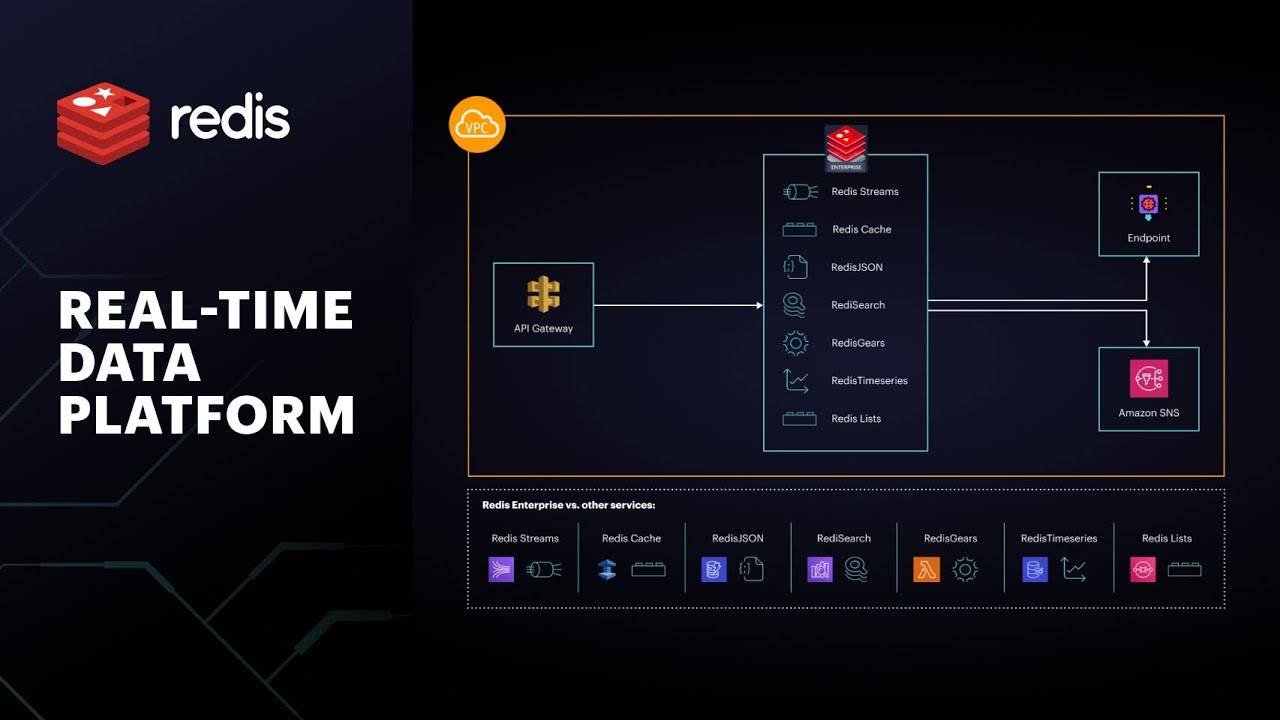
Comparative Insight: Redis vs. Traditional Data Lakes and Data Warehouses
While Redis excels in the real-time domain, it’s essential to understand its role in comparison to traditional data storage solutions like data lakes and data warehouses. These technologies are often complementary rather than mutually exclusive, each serving distinct purposes within a holistic data architecture.
Speed and Latency
- Redis: Operates in milliseconds or even microseconds. Its in-memory nature and optimized data structures are designed for immediate access and high-throughput, low-latency operations. This makes it ideal for operational data stores, caching, and serving real-time features.
- Data Lakes/Warehouses: Typically operate in seconds to minutes, or even hours for complex batch queries. They are optimized for large-scale analytical processing, complex joins, and historical data analysis, not for instantaneous transactions or immediate reactions.
Use Cases
- Redis: Best for real-time analytics, transactional caching, session management, real-time dashboards, stream processing, leaderboards, messaging, and operational data serving (e.g., feature stores for ML inference).
- Data Lakes/Warehouses: Designed for business intelligence (BI), historical reporting, complex analytical queries, data science exploration on massive datasets, regulatory compliance, and long-term data archival.
Data Volume and Cost
- Redis: Excellent for handling high volumes of requests on relatively smaller “hot” datasets that fit in memory (or across a cluster). Memory is more expensive per GB than disk.
- Data Lakes/Warehouses: Capable of storing petabytes to exabytes of data economically on disk-based storage. Cost-effective for massive historical datasets where immediate access isn’t paramount.
Data Structure and Schema
- Redis: Offers flexible, schema-less key-value storage with rich data types. Ideal for semi-structured or unstructured data where quick retrieval based on a key is needed.
- Data Warehouses: Typically highly structured with a predefined schema (schema-on-write), optimized for relational queries.
- Data Lakes: Store data in its raw format with no predefined schema (schema-on-read), supporting a wide variety of data types including structured, semi-structured, and unstructured data.
In practice, modern data architectures often integrate Redis with data lakes and warehouses. For example, a data lake might store all raw historical data, a data warehouse could contain aggregated and transformed data for BI, and Redis would serve as a high-speed layer for caching frequently accessed data, enabling real-time analytics on a subset of the data, or acting as a feature store for real-time ML inference. This synergistic approach allows organizations to leverage the strengths of each technology, achieving both immediate operational insights and comprehensive historical analysis from Redis Real-Time Data.
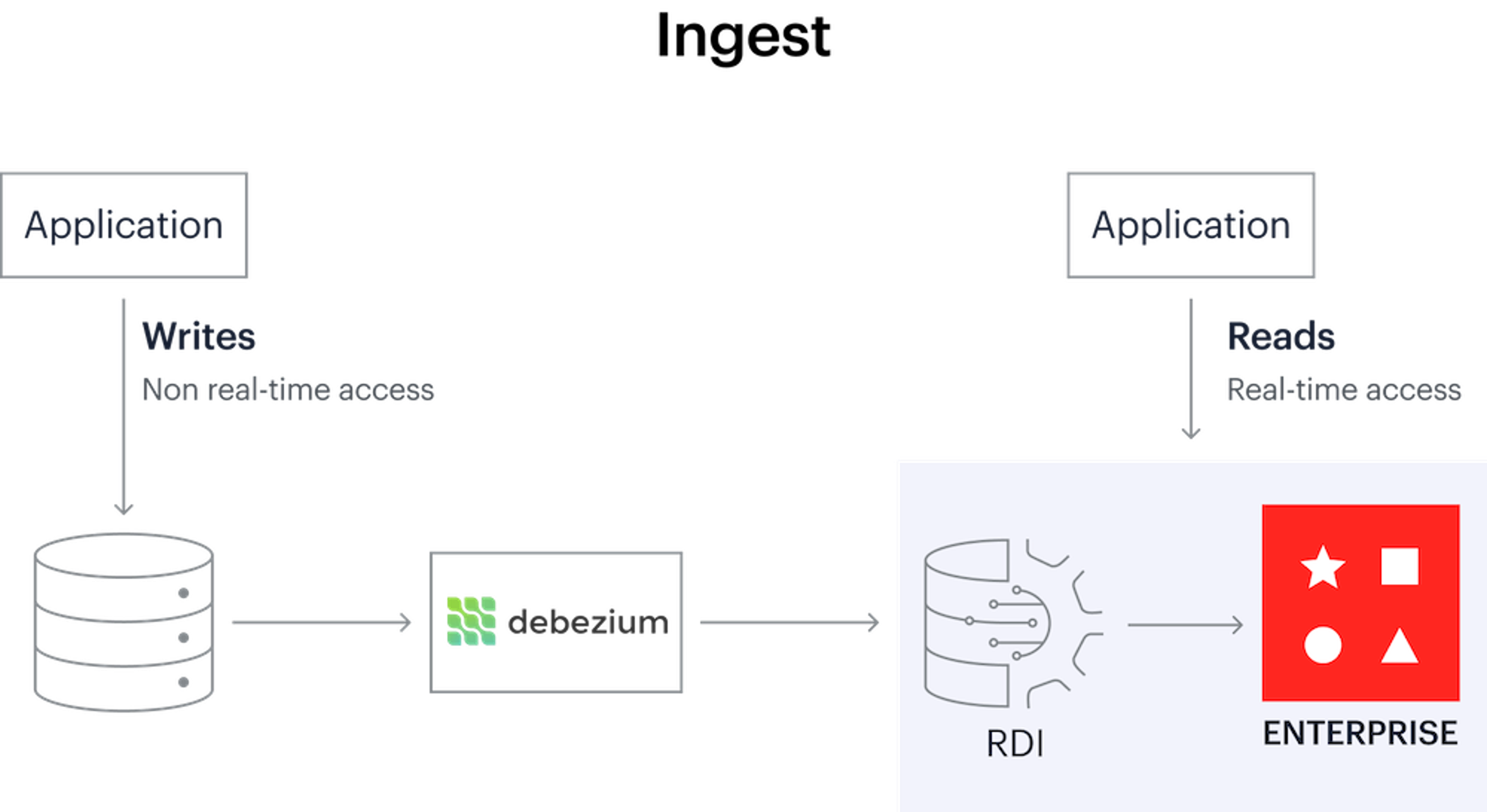
World2Data Verdict: The Indispensable Role of Redis in Modern Data Architectures
Redis has unequivocally cemented its position as an indispensable component in modern data architectures, particularly for any organization striving for true real-time capabilities. Its unparalleled speed, versatile data structures, and robust feature set for caching, messaging, and stream processing make it the go-to solution for transforming raw data into actionable insights at lightning speed. From powering instantaneous analytics dashboards and personalizing user experiences to serving critical features for AI/ML models, Redis empowers businesses to operate with a new level of agility and responsiveness.
Organizations looking to truly leverage Redis Real-Time Data for competitive advantage should not only integrate Redis but also invest in developing robust MLOps practices around feature stores, ensuring data quality, and implementing comprehensive data governance for real-time data streams. The future will see an even deeper convergence of Redis with edge computing, serverless architectures, and advanced AI frameworks, pushing the boundaries of what’s possible with immediate data. World2Data anticipates that Redis will continue to evolve, offering even more specialized modules and cloud-native integrations, making real-time data processing more accessible and powerful for enterprises across all sectors.

{kind=link}