


Ensuring Resilience: A Deep Dive into Fault Tolerance in Big Data Systems
Fault Tolerance in Big Data Systems is paramount for any organization navigating the complexities of massive datasets. Achieving robust Big Data Fault Tolerance is not merely a technical add-on but a foundational requirement to ensure uninterrupted operations and reliable data processing. In environments where data volumes scale to petabytes, the probability of hardware failure or network issues significantly increases, making resilient system design non-negotiable. This article delves into the core mechanisms, challenges, and business value of building fault-tolerant big data architectures, offering insights into securing your data infrastructure against inevitable disruptions.
The Indispensable Role of Big Data Fault Tolerance
In the era of ubiquitous data, the reliability of data processing and storage systems directly correlates with an organization’s operational continuity and decision-making capabilities. For World2Data.com, understanding and implementing robust Big Data Fault Tolerance is not just a technical specification; it’s a strategic imperative. As Platform Category: Big Data Processing Frameworks and Distributed Storage Systems become the backbone of modern enterprises, the potential for system failures, whether due to hardware malfunctions, software bugs, or network outages, looms large. A single point of failure can cascade into widespread data loss, prolonged downtime, and significant financial repercussions. Therefore, designing systems with an inherent ability to withstand and recover from such failures without human intervention is crucial.
The objective of this deep dive is to dissect the fundamental principles and architectural components that contribute to fault tolerance in big data environments. We will explore how systems gracefully degrade, recover, and continue processing even when individual components fail, thereby maintaining high availability and data integrity. This resilience is what separates leading data platforms from those prone to catastrophic interruptions, ensuring that critical analytics, machine learning workloads, and business operations proceed uninterrupted. The very essence of Big Data Fault Tolerance lies in creating an ecosystem where failures are anticipated, contained, and automatically remediated, transforming potential disasters into minor, manageable events.
Core Breakdown: Architectural Pillars of Big Data Fault Tolerance
The construction of a fault-tolerant big data system relies on several sophisticated Core Technologies and Architectures designed to ensure continuous operation and data consistency even in the face of partial system failures. These mechanisms are often interwoven, forming a multi-layered defense against various types of disruptions. The primary strategies revolve around redundancy, state preservation, and intelligent task management.
Data Replication and Distributed Storage
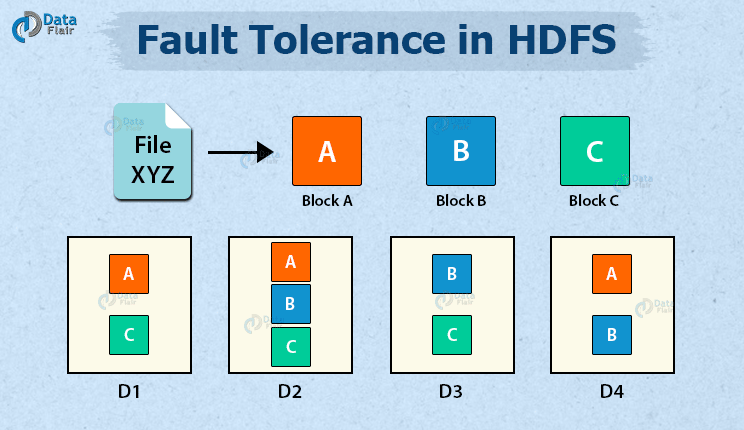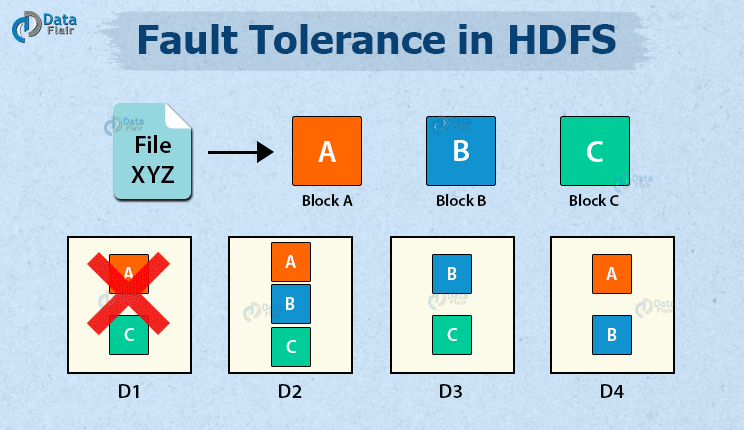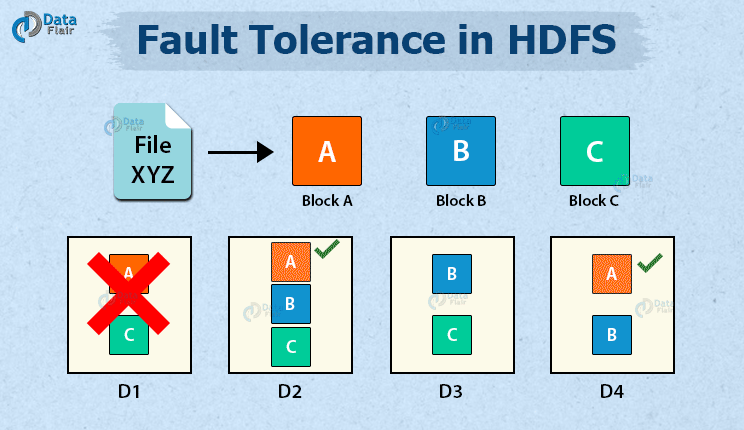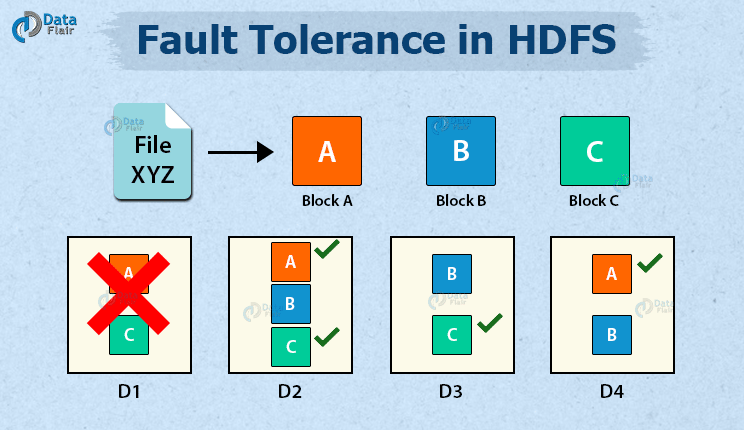
At the heart of many Big Data Fault Tolerance strategies, particularly in Distributed Storage Systems like HDFS (Hadoop Distributed File System), is data replication. This involves storing multiple copies of data blocks across different nodes within a cluster. When a DataNode fails, copies of its data are still available on other nodes, allowing processing to continue seamlessly and preventing data loss. HDFS, for instance, typically replicates each data block three times by default. This redundancy ensures high availability and durability. When a DataNode goes down, the NameNode detects the failure and initiates the replication of the affected data blocks to other healthy nodes, restoring the desired replication factor. This automated recovery process is a prime example of Automated Data Backup and Recovery, a Key Data Governance Feature in these systems.
Checkpointing and Logging
For Big Data Processing Frameworks that handle stateful computations or long-running jobs, checkpointing is a critical fault tolerance mechanism. Technologies like Apache Spark Streaming, Apache Flink, and distributed databases utilize checkpointing to periodically save the state of a computation or data to a persistent, fault-tolerant storage system (often HDFS or cloud storage). In the event of a worker node failure, the system can simply reload the last saved checkpoint and resume computation from that point, rather than restarting the entire job from scratch. This significantly reduces recovery time and prevents re-processing extensive amounts of data. This mechanism is particularly vital for Primary AI/ML Integration, where checkpointing for long-running model training jobs ensures that hours or days of computation are not lost due to transient failures, allowing models to pick up training from their last stable state.
Task Re-computation (Lineage)
Another powerful technique, exemplified by frameworks like Apache Spark’s Resilient Distributed Datasets (RDDs) and their evolution into DataFrames/Datasets, is task re-computation based on data lineage. An RDD or DataFrame maintains a lineage graph, which is essentially a record of all transformations applied to it from its initial creation. If a partition of an RDD or a block of a DataFrame on a failed node is lost, Spark can reconstruct that lost portion by re-applying the transformations recorded in its lineage to the original input data. This “re-computation” provides fault tolerance without the overhead of replicating intermediate data, making it very efficient for certain types of workloads. It’s a reactive approach where computations are rebuilt only when needed, minimizing storage requirements compared to full data replication, offering a clever balance between resilience and resource efficiency.
Challenges and Barriers to Achieving Robust Fault Tolerance
While the mechanisms for Big Data Fault Tolerance are sophisticated, their implementation and maintenance are not without significant challenges:
- Complexity at Scale: Managing fault tolerance across petabytes of data and thousands of nodes introduces immense complexity. Configuring replication factors, checkpoint intervals, and recovery policies optimally for diverse workloads is a continuous challenge. The sheer number of components increases the probability of intermittent failures, demanding robust automation.
- Consistency vs. Availability Trade-offs: The CAP theorem (Consistency, Availability, Partition Tolerance) dictates that a distributed system can only guarantee two of these three properties simultaneously. Designing fault-tolerant systems often involves careful trade-offs, where maintaining strong consistency might impact availability during network partitions, or vice-versa, forcing architects to make critical decisions based on business requirements.
- Data Drift and Schema Evolution: While not directly a fault tolerance mechanism, unexpected changes in data schemas or characteristics (data drift) can lead to processing failures that fault tolerance mechanisms might recover from, but the underlying data quality issue remains, leading to corrupted output or incorrect insights. Ensuring robust data validation alongside fault tolerance is crucial to prevent silent data corruption.
- MLOps Complexity: For AI/ML workloads, achieving fault tolerance for model training and serving is complicated by the stateful nature of training, dependency on specific hardware (e.g., GPUs), and the need for consistent model versions across distributed inference engines. Managing checkpoints for models, ensuring reproducibility, and orchestrating recovery within complex MLOps pipelines adds layers of difficulty, often requiring specialized frameworks.
- Cost Implications: Redundancy, whether through data replication, checkpointing, or implementing erasure coding, inherently consumes more resources (storage, compute, network bandwidth). Balancing the desired level of fault tolerance with infrastructure costs is a constant optimization problem for organizations striving for efficiency.
Business Value and Return on Investment (ROI)
The investment in robust Big Data Fault Tolerance yields substantial business value and a tangible return on investment:
- Uninterrupted Operations and Data Availability: The most direct benefit is the assurance of continuous service. Businesses can rely on their data infrastructure to be available 24/7, enabling critical applications, customer services, and analytics to run without disruption, even during component failures.
- Preservation of Data Integrity: Fault tolerance mechanisms are crucial for preventing data corruption and loss. This ensures that the information flowing through the system remains accurate, reliable, and trustworthy, which is vital for compliance, auditing, and informed decision-making.
- Reduced Downtime Costs: Every minute of downtime in a big data system can cost organizations significantly, both in direct revenue loss and indirect impacts like reputational damage. Fault tolerance drastically reduces the frequency and duration of outages, leading to substantial cost savings and safeguarding brand reputation.
- Enhanced Productivity and Resource Utilization: With automatic recovery, IT teams spend less time on manual interventions and troubleshooting after failures, allowing them to focus on innovation and system optimization. Furthermore, resources aren’t wasted on re-running entire jobs from scratch, improving overall operational efficiency.
- Faster Insights and Reliable Decision-Making: Consistent data availability and processing allow business analysts and data scientists to generate insights more quickly and with greater confidence. This accelerates time-to-market for data products and enables agile responses to market changes, providing a competitive edge.
- Compliance and Regulatory Adherence: Automated Data Backup and Recovery, a core feature of fault-tolerant systems, plays a critical role in meeting stringent regulatory requirements for data retention, disaster recovery, and business continuity planning across various industries.

Comparative Insight: Big Data Fault Tolerance vs. Traditional Systems
The approach to fault tolerance in modern big data systems represents a significant paradigm shift from traditional data management architectures, such as monolithic relational database management systems (RDBMS) or early data warehouses. Understanding these distinctions is crucial for appreciating the inherent resilience built into contemporary big data platforms.
Traditional systems often relied on concepts like disk mirroring (RAID), database backups, and hot standby servers for disaster recovery. While effective for their scale, these approaches typically implied a “single point of failure” model, where the failure of the primary server or storage unit necessitated a failover to a secondary, often inactive, system. Recovery could involve significant downtime, manual intervention, and a potential for data loss between the last backup and the point of failure. The entire system would often need to be brought down for maintenance or significant upgrades, impacting availability for all users and applications.
In stark contrast, modern Big Data Processing Frameworks and Distributed Storage Systems are designed with fault tolerance as a fundamental, distributed characteristic. They operate on a “shared-nothing” architecture, where data and computation are distributed across hundreds or thousands of commodity servers. This inherent distribution eliminates single points of failure. If a node goes down, the system doesn’t stop; it continues processing by leveraging redundant data copies and re-assigning tasks to healthy nodes. This is the essence of a truly resilient architecture, where failures are anticipated as normal occurrences rather than exceptional events, leading to significantly higher uptime and continuous data availability.
When considering Main Competitors/Alternatives in fault tolerance strategies, we often differentiate between Replication-based vs. Erasure Coding. Replication, as discussed, stores identical copies of data. Erasure coding, on the other hand, breaks data into fragments and generates parity fragments, allowing the original data to be reconstructed even if several fragments are lost. Erasure coding offers similar fault tolerance with significantly less storage overhead compared to replication, albeit with higher computational complexity during recovery. HDFS, for example, supports both, with erasure coding becoming more prevalent for cold data storage to optimize costs while maintaining resilience.
Another key distinction lies in Reactive vs. Proactive fault tolerance. Reactive fault tolerance, common in many big data systems, involves detecting failures and then initiating recovery (e.g., re-replicating data, re-running tasks from a checkpoint). Proactive fault tolerance, still an evolving area, aims to predict impending failures (e.g., using machine learning to monitor hardware health) and migrate data or tasks away from a failing component *before* it actually crashes, thereby minimizing disruption. While fully proactive systems are complex, hybrid approaches are becoming more common, augmenting reactive recovery with predictive maintenance capabilities to further enhance system reliability.
World2Data Verdict: Pioneering Resilient Big Data Futures
At World2Data.com, our analysis unequivocally concludes that robust Big Data Fault Tolerance is not merely a feature but the bedrock upon which any successful large-scale data strategy must be built. The continuous innovation in distributed systems design, from advanced data replication and erasure coding to sophisticated checkpointing and lineage-based re-computation, underscores a clear trend: data platforms are evolving to be inherently self-healing and extraordinarily resilient. For organizations looking to future-proof their data initiatives, moving beyond reactive problem-solving to proactive, intelligent fault avoidance and swift recovery is paramount.
Our recommendation is to prioritize architectures that integrate end-to-end fault tolerance, spanning from data ingestion and storage to processing and serving. This includes evaluating Big Data Processing Frameworks and Distributed Storage Systems based on their native fault-tolerance capabilities, their efficiency in recovery, and their ability to integrate with broader data governance strategies like Automated Data Backup and Recovery. Furthermore, as AI/ML workloads become central, the capability to handle long-running model training jobs with seamless checkpointing will be a non-negotiable differentiator. Investing in these resilient foundations ensures not just operational continuity, but also fosters an environment of trust in data, enabling truly data-driven innovation and competitive advantage in a world where data is everything, and its availability is paramount.

{kind=link}