


Data Aggregation: Combining Multiple Sources for Better Insights
In today’s hyper-connected, data-rich environment, the ability to consolidate, cleanse, and analyze information from myriad sources is not merely an advantage but a fundamental necessity. Data aggregation stands as the cornerstone of modern analytics, transforming disparate, often chaotic, datasets into a unified, coherent whole. This critical process empowers organizations to move beyond isolated data points, revealing deeper trends, enhancing decision-making, and fostering a truly holistic understanding of their operations and market dynamics. Without effective data aggregation, businesses risk operating on incomplete intelligence, hindering their ability to innovate and compete effectively.
The Strategic Imperative of Data Aggregation
The contemporary enterprise is awash in data, emanating from diverse origins such as transactional systems, CRM platforms, IoT devices, social media feeds, and external market intelligence. Each source offers a unique, yet often fragmented, piece of the puzzle. The objective of data aggregation is to systematically gather this raw data, integrate it, and structure it into a cohesive format that is ready for analysis. This process is pivotal for unlocking granular insights, providing a singular, comprehensive perspective that is impossible to achieve when information remains siloed across various operational systems.
Understanding the core concept of unifying data begins with recognizing the inherent challenges of data diversity. Data points often arrive in varied formats, with different schemas, definitions, and levels of granularity. Effective data aggregation collects these discrete points from multiple sources, then harmonizes these varied formats, making them compatible for comprehensive analysis. Beyond mere collection, transforming raw information involves a crucial stage where data undergoes cleaning, validation, and structuring. This step ensures accuracy, eliminates redundancies, and prepares complex multi-source data for analytical readiness, guaranteeing that subsequent analyses are based on reliable and high-quality information.
Core Breakdown: Architecture and Advanced Practices in Data Aggregation
The architecture underpinning robust data aggregation is multi-faceted, incorporating several critical components and advanced technologies to handle the volume, velocity, and variety of modern data. At its heart, data aggregation relies on sophisticated processes and platforms to ingest, process, and store integrated information.
Fundamental Technologies and Architectural Components
- ETL/ELT Pipelines: Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT) processes are fundamental to data aggregation. ETL historically involved transforming data before loading it into a data warehouse, while ELT loads raw data first into a data lake, leveraging the processing power of modern data platforms for transformation. These pipelines are essential for moving data from operational sources, applying necessary transformations (cleansing, standardizing, joining), and loading it into analytical stores.
- Data Integration Platforms: These are specialized software solutions designed to facilitate the complex task of connecting to diverse data sources, extracting data, and applying business rules to ensure consistency and quality. Platforms like Informatica, Talend, IBM DataStage, Microsoft Azure Data Factory, AWS Glue, and Google Cloud Dataflow are prime examples, offering extensive connectors, transformation capabilities, and workflow orchestration for enterprise-grade data aggregation.
- Data Warehouses and Data Lakes: Data warehouses serve as centralized repositories for structured, aggregated, and historical data, optimized for analytical queries. Data lakes, conversely, store vast amounts of raw, unstructured, and semi-structured data from various sources, offering flexibility for future analytical needs. Both are critical destinations for aggregated data, serving different purposes in the analytical lifecycle.
- Data Virtualization and Data Federation: These advanced techniques allow organizations to access and combine data from multiple sources in real-time without physically moving or copying it. Data virtualization creates a virtual layer that presents a unified view of disparate data, while data federation integrates data from different sources into a single virtual database. They offer agility and reduce the need for extensive ETL processes for certain use cases.
- Distributed Computing: Technologies like Apache Spark are crucial for processing vast datasets at scale. Spark’s in-memory processing capabilities make it ideal for high-volume, high-velocity data aggregation tasks, enabling rapid transformations and complex analytical operations across distributed clusters.
- Cloud-native Data Integration Services: Cloud platforms offer scalable, flexible, and often serverless solutions for data aggregation. Services like AWS Glue, Azure Data Factory, and Google Cloud Dataflow simplify integrating and processing vast datasets, leveraging elastic cloud resources to manage fluctuating data volumes and velocities efficiently.
Challenges and Barriers to Effective Data Aggregation
Despite its undeniable benefits, implementing and maintaining effective data aggregation strategies presents several significant challenges:
- Data Inconsistencies and Quality Issues: Reconciling disparate formats, definitions, and semantics across multiple sources is a primary hurdle. Data quality issues like missing values, duplicates, and inaccuracies can propagate and undermine the reliability of aggregated insights. Robust Data Quality Management frameworks and automated cleaning processes are vital.
- Data Volume, Velocity, and Variety (Big Data Challenges): The immense volume of data, coupled with its high velocity (real-time streams) and wide variety (structured, semi-structured, unstructured), demands scalable infrastructure and sophisticated processing capabilities. Managing these “3Vs” without incurring prohibitive costs or performance bottlenecks is a constant challenge.
- Schema Evolution and Data Drift: Source systems constantly evolve, leading to changes in data schemas (schema evolution). Over time, the statistical properties of data in production change, a phenomenon known as data drift. These shifts can break aggregation pipelines and invalidate models built on aggregated data, requiring continuous monitoring and adaptive solutions.
- Ensuring Data Security and Compliance: Centralizing sensitive information from various sources escalates security risks. Implementing stringent security protocols, including encryption, access controls (like Role-Based Access Control), and Data Masking for sensitive fields, is paramount. Furthermore, adherence to regulatory compliance standards (e.g., GDPR, CCPA) becomes more complex with aggregated data.
- Complexity of Data Lineage and Metadata Management: Tracking the origin, transformations, and destinations of aggregated data (Data Lineage) is crucial for auditing, troubleshooting, and understanding data trustworthiness. Comprehensive Metadata Management is essential for cataloging data assets, understanding their context, and facilitating discoverability.
Business Value and ROI Derived from Data Aggregation
The strategic investment in data aggregation yields substantial business value and a compelling return on investment:
- Enhanced Decision-Making: A comprehensive, aggregated view supports informed, strategic decisions. Leaders gain clearer, real-time insights into operational performance, market trends, customer behavior, and emerging opportunities, enabling proactive and data-driven strategies.
- Improved Data Quality and Consistency: Consolidating data across sources facilitates the identification and correction of inconsistencies, duplicates, and errors, significantly boosting overall data quality. High-quality aggregated data ensures that analyses and subsequent decisions are based on reliable and accurate information.
- Gaining a Holistic View and 360-Degree Insights: Data aggregation provides a 360-degree perspective of customers, products, or business processes. This unified overview is essential for revealing intricate relationships, hidden patterns, and interdependencies that are otherwise invisible in siloed datasets.
- Operational Efficiency and Cost Reduction: By streamlining data pipelines and automating the integration process, organizations reduce manual effort, accelerate data availability, and minimize the costs associated with disparate data management.
- Faster Model Deployment and AI/ML Enablement: Clean, consistent, and aggregated data is the lifeblood of Artificial Intelligence and Machine Learning models. Effective data aggregation provides the high-quality training data required for building more accurate predictive models, facilitating initiatives like Automated Data Mapping and Schema Matching, Anomaly Detection in Data Pipelines, and ML-driven Data Quality Checks. It also enables Predictive Analytics on Aggregated Data, delivering actionable foresight.
- Competitive Advantage: Organizations that master data aggregation can react more quickly to market changes, identify new business opportunities, and offer personalized experiences, thereby gaining a significant competitive edge.
Comparative Insight: Data Aggregation vs. Traditional Data Architectures
While concepts like Data Lakes and Data Warehouses are integral components within a comprehensive data strategy, data aggregation specifically refers to the *process* of combining and preparing data, which is a foundational layer for both. Traditional data architectures often struggled with the scale and diversity of modern data, whereas contemporary data aggregation approaches are designed to overcome these limitations.
In a traditional data warehouse setup, data was typically highly structured and aggregated during the ETL process, often leading to a loss of granular detail and limited flexibility for ad-hoc analysis. The focus was on pre-defined reports and business intelligence dashboards. While effective for its time, this approach often became a bottleneck when new data sources emerged or when business users required more exploratory analytics.
Data lakes offered a solution to the inflexibility of data warehouses by storing raw data in its native format, enabling schema-on-read flexibility. However, without robust data aggregation practices layered on top, a data lake can quickly become a “data swamp”—a repository of ungoverned, uncatalogued, and ultimately unusable data. Modern data aggregation strategies bridge this gap by imposing structure and meaning *after* the raw data is stored, often through ELT processes, transforming raw lake data into curated, aggregated datasets suitable for advanced analytics and machine learning workloads.
The key distinction lies in the dynamism and scope. Traditional methods often involved batch processing and predefined schemas, limiting agility. Modern data aggregation, especially with the advent of Cloud-native Data Integration Services and distributed computing frameworks like Apache Spark, allows for real-time or near real-time aggregation, support for diverse data types, and the ability to handle fluctuating data volumes with elastic scalability. It’s not just about centralizing data; it’s about making that centralized data intelligently usable across the entire enterprise, driving everything from routine reporting to advanced AI initiatives.
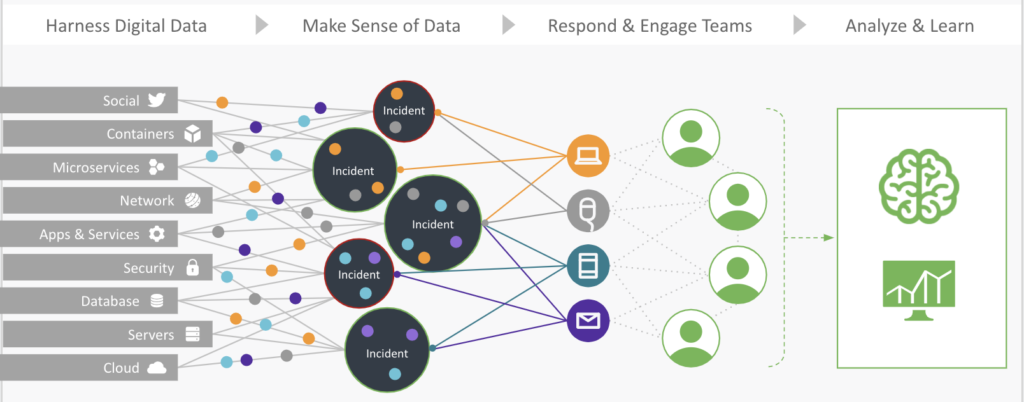
World2Data Verdict: The Unifying Force for Future-Ready Analytics
At World2Data, we view data aggregation not just as a technical process but as the unifying force that underpins all successful data-driven initiatives. Its mastery is non-negotiable for organizations aiming to extract genuine value from their data assets. The future of analytics, AI, and competitive advantage hinges on the ability to seamlessly integrate, cleanse, and contextualize information from every available source. We recommend that enterprises prioritize investment in robust Data Integration Platforms and adopt agile methodologies for pipeline development. Furthermore, embrace AI/ML-driven capabilities for automated schema matching, anomaly detection, and continuous data quality monitoring to proactively manage the complexities of modern data landscapes. The sustained success of any data strategy will be directly proportional to the effectiveness of its underlying data aggregation framework, transforming raw information into the strategic intelligence required for tomorrow’s challenges.
The ability to effectively consolidate and analyze information from numerous origins is no longer a luxury but a fundamental necessity for any entity striving for competitive advantage and deeper understanding. It allows organizations to genuinely harness the power of interconnected information, revealing possibilities that single data streams could never fully disclose. Investing in sophisticated data aggregation strategies will differentiate market leaders, empowering them with unparalleled insights and the agility to navigate an increasingly complex global economy.

{kind=link}