


Distributed Data Platforms: Scaling Global Analytics and AI Across Regions
In an increasingly interconnected global economy, businesses face the monumental challenge of managing, processing, and deriving insights from data scattered across various geographical locations. This complexity has elevated the Distributed Data Platform from a niche technology to an indispensable strategic asset. Such platforms fundamentally redefine how organizations interact with their vast datasets, ensuring data proximity to its point of use, thereby enabling real-time analytics and operational efficiency regardless of geographical boundaries. They are crucial for unlocking new levels of business agility and informed decision-making in a data-driven world.
Key Characteristics of a Modern Distributed Data Platform
- Platform Category: A sophisticated blend of Distributed Data Platform capabilities, serving as a comprehensive Global Analytics Platform.
- Core Technology/Architecture: Characterized by advanced Multi-region data replication, robust Federated query processing, and an overarching Data Fabric architecture designed for seamless data integration.
- Key Data Governance Feature: Includes powerful Centralized metadata management, Unified policy enforcement, and critical Data residency controls to ensure compliance and security.
- Primary AI/ML Integration: Optimized for Distributed ML training, facilitates Multi-region model deployment, and supports Data-local AI processing for enhanced performance and reduced latency.
- Main Competitors/Alternatives: Key players and alternative approaches include Snowflake, Databricks, Google Cloud Spanner, AWS Global Database, and Azure Cosmos DB.
Introduction to Distributed Data Platforms
Distributed Data Platforms are becoming indispensable for businesses navigating the complexities of global operations. A Distributed Data Platform fundamentally redefines how organizations manage, process, and analyze their vast datasets, ensuring data is closer to its point of use, regardless of geographical boundaries. This architecture decentralizes data storage and processing, moving away from monolithic databases that often become bottlenecks in global enterprises. These platforms are crucial for modern enterprises seeking agility and real-time insights from distributed sources, supporting diverse data types and high-volume transactions across various cloud environments or on-premises infrastructure. The core objective is to overcome the limitations of traditional, centralized data infrastructures, which struggle with latency, scalability, and data sovereignty requirements across different regions.
Understanding the nuances of a Distributed Data Platform involves recognizing its role in enabling high availability, disaster recovery, and consistent performance for applications and analytics worldwide. By spreading data and processing capabilities across multiple nodes and regions, these platforms mitigate the risks associated with single points of failure and ensure uninterrupted service. This approach is not merely about replicating data; it’s about intelligent data placement, dynamic workload distribution, and providing a unified view over disparate data assets, making it a cornerstone for any global analytics strategy. The inherent design of a Distributed Data Platform facilitates elastic scalability, allowing organizations to expand their data footprint and processing power as business demands grow, without significant architectural overhaul.
Core Breakdown: Architecture and Capabilities
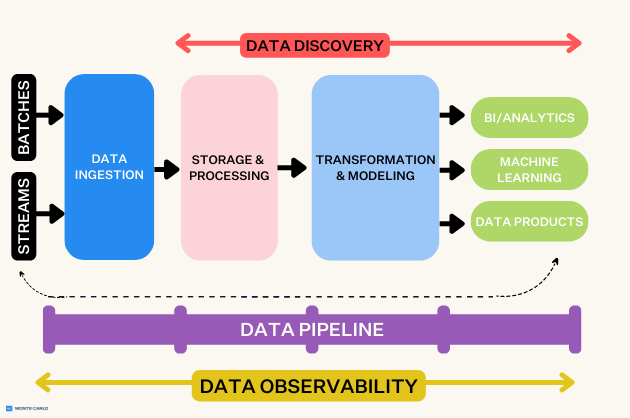
The architecture of a modern Distributed Data Platform is complex, encompassing a myriad of interconnected components designed for efficiency, resilience, and global reach. At its heart lies the principle of data decentralization, where data is stored and processed across geographically dispersed nodes. Key architectural elements often include multi-region data replication, ensuring data availability and redundancy; federated query processing, which allows queries to span multiple data sources without needing to move all data to a central location; and an overarching data fabric architecture, providing a unified, virtualized view of data across diverse systems.
Data ingestion in such platforms supports a wide array of sources, from streaming data to batch uploads, often leveraging technologies like Apache Kafka or AWS Kinesis for real-time data flows. Storage layers typically combine distributed file systems (e.g., HDFS), object storage (e.g., S3, Azure Blob Storage), and purpose-built distributed databases (e.g., Cassandra, Google Cloud Spanner, Azure Cosmos DB) to handle structured, semi-structured, and unstructured data efficiently. Processing engines like Apache Spark, Flink, or Presto enable high-performance analytics, machine learning, and data transformations directly on the distributed data. Advanced features like built-in Feature Stores provide a centralized repository for curated, consistent features for machine learning models, irrespective of the data’s physical location. Similarly, integrated Data Labeling capabilities can be distributed to leverage local expertise or specialized teams, feeding into global AI initiatives without requiring massive data transfers.
Challenges and Barriers to Adoption
Despite the immense advantages, implementing a Distributed Data Platform presents several formidable challenges. One of the primary concerns is ensuring data consistency across multiple regions. Achieving strong consistency without compromising performance or availability is a complex distributed systems problem, often requiring trade-offs between consistency, availability, and partition tolerance (CAP theorem). Network latency and bandwidth costs also pose significant hurdles, as data synchronization and federated queries across vast geographical distances can introduce delays and incur substantial operational expenses.
The operational complexity of managing a distributed system is another major barrier. MLOps complexity amplifies when dealing with models trained and deployed across regions, requiring robust orchestration, monitoring, and automated pipelines. Data drift, where the statistical properties of the target variable change over time, becomes particularly challenging in a distributed environment, as different regions might experience drift at varying rates or with different characteristics. Furthermore, navigating the labyrinth of global data governance and compliance regulations—such as GDPR, CCPA, and various data sovereignty laws—requires sophisticated mechanisms for data residency controls and unified policy enforcement. Security, in a landscape where data is spread across multiple clouds and on-premises environments, demands advanced encryption, access control, and threat detection capabilities that are difficult to implement uniformly.
Business Value and ROI
The strategic value and return on investment (ROI) derived from a well-implemented Distributed Data Platform are substantial. Foremost, these platforms enable significantly faster time to insight for global operations. By processing data closer to its source, organizations can reduce latency and obtain real-time analytics, leading to enhanced decision-making capabilities across different business units and geographies. This directly translates to improved customer experiences, more agile market responses, and optimized operational processes.
The platform’s inherent support for high-quality data for AI initiatives is a game-changer. By centralizing metadata management and ensuring consistent data access, a Distributed Data Platform provides the clean, reliable data pipelines essential for training and deploying robust machine learning models. This leads to faster model deployment and more accurate predictions, fostering innovation and competitive advantage. Moreover, compliance with stringent data residency requirements becomes manageable, mitigating legal and reputational risks. Cost optimization is also a key benefit; by processing data locally, organizations can minimize costly cross-region data transfers, optimizing cloud expenditure. For AI/ML workloads, the ability to perform distributed ML training and data-local AI processing significantly accelerates model development cycles and improves model performance by leveraging proximate, relevant data. Ultimately, a Distributed Data Platform elevates an organization’s capability to operate globally with localized efficiency, driving unprecedented business agility and growth.

Comparative Insight: Distributed vs. Traditional Data Architectures
The fundamental distinction between a Distributed Data Platform and traditional data architectures like data lakes or data warehouses lies in their approach to data management and processing, especially concerning geographical distribution and scale. Traditional data warehouses are typically centralized, highly structured, and optimized for business intelligence (BI) on historical, transformed data. While excellent for specific reporting needs, their monolithic nature makes them inherently less suited for real-time analytics, diverse data types, and global operations where data is generated and consumed across continents. Moving large volumes of data to a central warehouse for analysis introduces significant latency, egress costs, and compliance headaches regarding data sovereignty.
Data lakes, while more flexible in terms of data types and schema-on-read flexibility, often still operate within a centralized paradigm, aggregating raw data into a single, massive repository. While they address the variety and volume aspects, they can face similar challenges as data warehouses when it comes to geographical distribution, latency for users far from the central lake, and the complexities of managing access and governance across global teams without robust distributed capabilities. Data silos, while mitigated within the data lake itself, can re-emerge if different regional teams build separate, unintegrated data lakes.
In contrast, a Distributed Data Platform embraces decentralization. It leverages technologies like multi-region data replication to keep data physically close to its users and applications, significantly reducing latency. Federated query processing allows analysts to query data across disparate, distributed sources without having to physically consolidate it, preserving data residency and minimizing data movement costs. The overarching Data Fabric architecture provides a logical layer that virtualizes and integrates these distributed data assets, offering a unified view that transcends physical boundaries. This architecture inherently supports global scalability, high availability, and disaster recovery by design, rather than as an afterthought. Furthermore, DDPs are uniquely positioned to handle stringent data residency controls and unified policy enforcement, critical for navigating the complex web of global data privacy regulations, a capability often cumbersome or impossible for traditional, centralized systems to achieve efficiently.
World2Data Verdict
At World2Data.com, our analysis indicates that the adoption of a robust Distributed Data Platform is no longer a luxury but a strategic imperative for any enterprise with global ambitions. The future of data-driven decision-making hinges on the ability to access, process, and analyze data efficiently, regardless of its geographical origin or destination. Organizations that embrace a distributed data strategy will gain a significant competitive edge through unparalleled agility, faster insights, and superior compliance capabilities.
We recommend that businesses initiate a comprehensive assessment of their global data footprint and analytical requirements to identify how a Distributed Data Platform can transform their operations. Focus on solutions that offer strong capabilities in multi-region data replication, intelligent federated query processing, and a cohesive Data Fabric architecture. Prioritize platforms that provide robust features for centralized metadata management, unified policy enforcement, and granular data residency controls. Furthermore, evaluate their readiness for primary AI/ML integration, including support for distributed ML training and data-local AI processing. The path forward involves a careful selection of technologies and a phased implementation strategy, emphasizing data governance and security from the outset. Investing in a Distributed Data Platform now will future-proof your data infrastructure, empowering your organization to thrive in an increasingly data-intensive and geographically dispersed world.

{kind=link}