


Data Ops: Streamlining Data Delivery and Reliability for the AI Era
Data Ops, a transformative methodology, is rapidly revolutionizing how modern organizations manage their data ecosystems. By integrating agile development, DevOps principles, and statistical process control, Data Ops applies rigorous engineering discipline to data analytics. This ensures that data pipelines are not only efficient and reliable but also scalable from inception to insight, fostering a new era of data-driven decision-making and innovation.
Introduction: The Imperative for Data Ops in Today’s Enterprise
In an increasingly data-intensive world, the velocity, volume, and variety of information present both immense opportunities and significant challenges. Organizations are under constant pressure to extract timely and accurate insights from their data to maintain a competitive edge. This is where Data Ops emerges as a critical solution, redefining data management from a manual, reactive process to an automated, proactive, and collaborative endeavor. World2Data categorizes Data Ops as a pivotal element within Data Orchestration and Delivery Platforms, focusing on ensuring the seamless flow of high-quality data.
At its core, Data Ops is a collaborative data management approach that bridges the gap between data creators (engineers, scientists) and data consumers (analysts, business users). It treats data as a product, emphasizing automation, monitoring, and continuous improvement across the entire data lifecycle. This holistic approach is underpinned by Core Technology/Architecture principles centered around Automated CI/CD for Data Pipelines, ensuring data assets are managed with the same rigor as software code. While often compared to methodologies like DevOps and MLOps, and contrasted with Traditional Manual Data Management, Data Ops serves as the crucial link, providing the reliable data foundation necessary for both agile software development and successful machine learning initiatives. The objective of this deep dive is to explore the intricacies of Data Ops, its architectural implications, the value it unlocks, and its position within the broader data landscape, particularly in supporting advanced analytics and AI.
Core Breakdown: Architecture, Mechanisms, and Value of Data Ops
Data Ops is more than just a set of tools; it’s a cultural shift combined with a robust technical framework designed to optimize the end-to-end data value chain. It extends the success of DevOps from application development to the intricate world of data.
Understanding the Core Principles Driving Data Ops Success
The philosophy of Data Ops rests on several foundational principles that guide its implementation and foster its benefits:
- Automation of Data Pipelines: From data ingestion and transformation to delivery and consumption, Data Ops champions automation. This includes automated data provisioning, testing, deployment, and monitoring, significantly reducing manual effort and the potential for human error.
- Seamless Collaboration: Data Ops promotes cross-functional collaboration among data engineers, data scientists, analysts, and business stakeholders. It breaks down silos, enabling shared understanding, rapid feedback, and collective ownership of data products.
- Continuous Monitoring and Feedback Loops: A central tenet is the continuous observation of data pipelines and data quality. Real-time dashboards, alerts, and automated issue detection mechanisms provide immediate feedback, allowing teams to proactively identify and resolve problems before they impact downstream consumers.
- Version Control and Reproducibility: Treating data and pipelines as code means applying version control. This ensures reproducibility of data environments, traceability of changes, and the ability to roll back to previous states, crucial for auditing and debugging.
- Agile Methodology for Data: Embracing iterative development, rapid prototyping, and frequent releases for data products, Data Ops allows organizations to respond quickly to changing business requirements and data landscapes.
Core Components of a Data Ops Ecosystem
Implementing Data Ops requires an integrated ecosystem of tools and practices:
- Automated CI/CD for Data Pipelines: This is a cornerstone. Continuous Integration ensures that changes to data transformations and models are frequently merged and tested. Continuous Delivery/Deployment automates the release of validated data products to production environments, making data available faster and more reliably.
- Automated Data Quality and Lineage Tracking: A key Data Governance Feature. Data Ops embeds automated tests throughout the pipeline to validate data quality at various stages (e.g., completeness, consistency, accuracy, validity). Lineage tracking provides a clear, auditable trail of data from its source to its final consumption point, essential for trust and regulatory compliance.
- Metadata Management: Centralized metadata repositories provide comprehensive information about data assets, including schema, relationships, business definitions, and quality metrics, facilitating discovery and understanding.
- Orchestration and Scheduling Tools: These tools manage the complex dependencies and scheduling of data pipelines, ensuring that data flows smoothly and on time.
- Monitoring and Alerting Systems: Proactive systems that track pipeline performance, data quality deviations, and resource utilization, alerting teams to potential issues before they escalate.
Enhanced Data Delivery for Agility
Through standardized processes, automated testing, and a focus on continuous delivery, Data Ops significantly reduces the lead time for data delivery. This translates directly into:
- Accelerating Time-to-Insight: Businesses can leverage fresh, reliable data for critical decisions much faster.
- Optimizing Data Flow Efficiency: Automated pipelines eliminate bottlenecks and reduce manual intervention, improving overall throughput.
- Facilitating Rapid Deployment of New Data Products: Organizations can quickly develop, test, and deploy new analytical models, dashboards, or data services, fostering innovation.
Achieving Improved Data Reliability
Data Ops strengthens trust in data by proactively identifying and resolving issues, leading to more accurate analytics and dependable reporting. This includes:
- Ensuring Data Quality and Consistency: Automated checks and continuous validation ensure data integrity across disparate systems.
- Minimizing Data Errors and Operational Disruptions: Early detection of anomalies prevents flawed data from propagating downstream, reducing the impact of errors.
- Building Robust Governance and Security: By embedding automated lineage, quality checks, and access controls into data processes, Data Ops ensures compliance and protects sensitive information.
Challenges and Barriers to Data Ops Adoption
Despite its clear benefits, implementing Data Ops is not without its hurdles:
- Cultural Resistance: Shifting from siloed, manual data management to a collaborative, automated mindset requires significant organizational change and buy-in from all levels.
- Integrating with Legacy Systems: Many organizations have deeply entrenched legacy data infrastructure that can be challenging to integrate into a modern Data Ops pipeline, often requiring significant refactoring or wrappers.
- Skill Gaps: The demand for professionals skilled in both data engineering and DevOps principles (Data Ops engineers) often outstrips supply, making talent acquisition and development a critical challenge.
- MLOps Complexity Integration: While Data Ops provides the reliable data supply for AI, integrating it seamlessly with MLOps workflows – managing model versions, retraining, and deployment – adds another layer of complexity that requires careful planning and specialized tools.
- Managing Data Drift: In dynamic environments, data schemas and semantics can change unexpectedly, leading to data drift. Data Ops must incorporate robust monitoring and adaptive mechanisms to detect and mitigate these changes, which can be technically challenging.
Business Value and ROI of Data Ops
The investment in Data Ops yields substantial returns:
- Faster Model Deployment: By providing a reliable, high-quality data supply through its Primary AI/ML Integration with MLOps, Data Ops significantly reduces the time it takes to develop, test, and deploy machine learning models into production.
- Improved Data Quality for AI: AI and ML models are only as good as the data they are trained on. Data Ops ensures the data feeding these models is clean, consistent, and validated, leading to more accurate and performant AI solutions.
- Reduced Operational Costs: Automation minimizes manual effort, leading to fewer errors and less time spent on debugging and maintenance.
- Increased Trust in Data: Reliable, governed data fosters greater confidence across the organization, leading to more informed strategic decisions.
- Competitive Advantage: Organizations that effectively leverage Data Ops can outpace competitors in data-driven innovation, product development, and customer insights.
Comparative Insight: Data Ops in the Modern Data Landscape
Understanding Data Ops fully requires positioning it alongside related methodologies and traditional approaches. It’s not merely a replacement but an evolution that integrates and enhances existing paradigms.
Data Ops vs. Traditional Data Lake/Data Warehouse Models
Historically, data management revolved around static Data Warehouses (structured, schema-on-write, for reporting) and more recently, Data Lakes (unstructured, schema-on-read, for exploration and analytics). While these architectures provide storage, they often struggle with the agility and reliability required by modern data consumers. Traditional models typically involve manual processes for data ingestion, transformation, and quality checks, leading to:
- Slow Data Delivery: Long lead times for new data sets or changes to existing ones.
- Inconsistent Data Quality: Errors often propagate unnoticed, leading to “data swamps.”
- Limited Collaboration: Siloed teams and handoffs create bottlenecks.
Data Ops transforms these foundational data repositories into dynamic, managed resources. It introduces the continuous integration and delivery of data, applying automated testing and monitoring directly to the data pipelines that feed and operate on data in lakes and warehouses. This shift ensures that data within these systems is not just stored, but is actively curated, validated, and delivered reliably and efficiently, unlocking their full potential for advanced analytics and AI.
Data Ops vs. DevOps and MLOps
Data Ops is often confused with or seen as a competitor to DevOps and MLOps. In reality, it is a complementary and foundational methodology:
- DevOps (Development Operations): Focuses on streamlining the software development lifecycle, emphasizing automation, continuous integration, continuous delivery, and collaboration between development and operations teams. Data Ops extends these principles specifically to the data pipeline, ensuring the “data factory” operates with the same efficiency and reliability as the software factory. Without Data Ops, even the most efficient software deployment via DevOps can be hampered by unreliable data.
- MLOps (Machine Learning Operations): Concentrates on the operationalization of machine learning models, managing their lifecycle from experimentation and training to deployment, monitoring, and retraining. MLOps is heavily dependent on a consistent supply of high-quality data for model training, validation, and inference. This is precisely where Data Ops plays its critical role. Data Ops ensures that the data used by MLOps is reliable, versioned, and delivered efficiently, becoming the bedrock upon which successful MLOps initiatives are built. Without robust Data Ops, MLOps efforts can struggle with data quality issues, pipeline instability, and difficulty in reproducing results.
In essence, Data Ops provides the “data for AI” and the “reliable data supply” that MLOps needs to flourish. It is an essential prerequisite for truly successful and scalable AI/ML integration, creating a virtuous cycle where Data Ops delivers quality data, MLOps operationalizes models, and the insights generated further inform data product development within the Data Ops framework. The primary keyword “AI Data Platform” becomes more robust and reliable when Data Ops principles are deeply embedded, ensuring the data foundation for AI is impeccable.
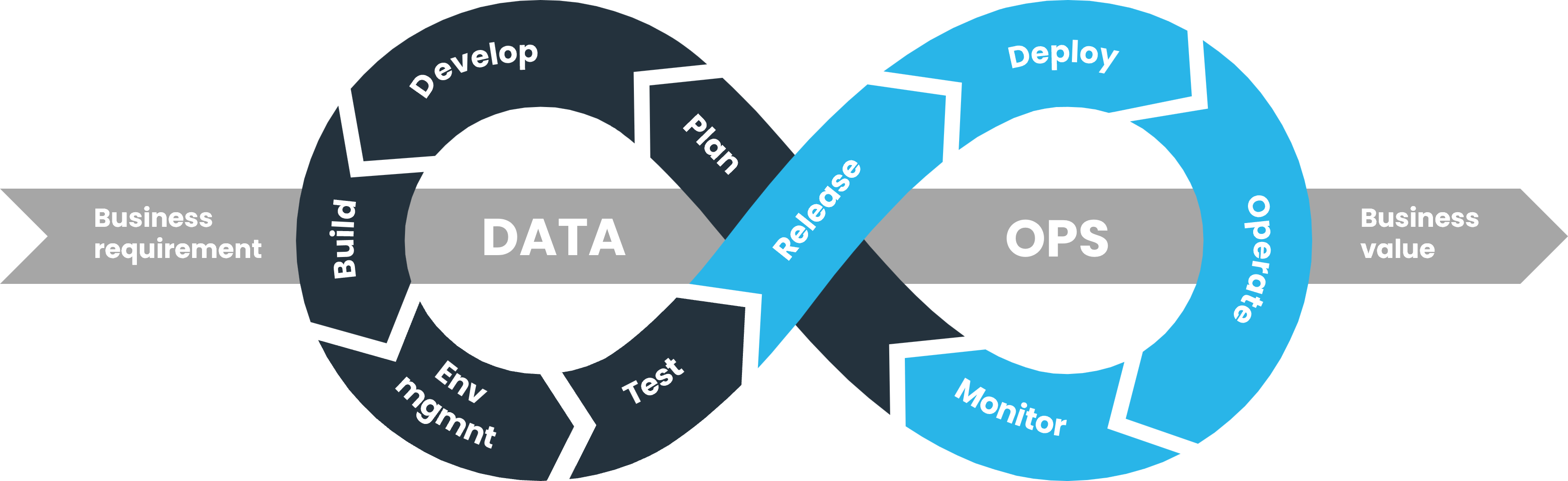
World2Data Verdict: The Indispensable Backbone for Data-Driven Futures
The trajectory of modern enterprises is inextricably linked to their ability to harness data effectively. Data Ops: Streamlining Data Delivery and Reliability is not merely a trend but an indispensable operational paradigm for any organization serious about becoming truly data-driven, especially those venturing into or scaling AI and machine learning initiatives. World2Data believes that Data Ops is the indispensable backbone that transforms raw data into a reliable, continuously delivered product, essential for accurate analytics and intelligent applications.
Our recommendation is unequivocal: organizations must prioritize the adoption of a Data Ops mindset and implement its practices across their data ecosystems. Begin with a cultural shift towards cross-functional collaboration and invest in the appropriate tools for automation, data quality, and lineage tracking. Gradually integrate Data Ops practices into existing workflows, understanding that this is an iterative journey of continuous improvement. For those aiming to build robust AI Data Platforms and achieve sustainable MLOps success, Data Ops is not optional; it is the critical enabler that ensures reliable data supply and empowers faster, more confident model deployment. The future belongs to organizations that treat their data with the engineering discipline and operational excellence that Data Ops provides.

{kind=link}