


Storage Layer: Crafting the Optimal Data Storage Strategy in the Age of Ingestion Layer Dynamics
The storage layer forms the bedrock of any robust data architecture, a crucial component that directly influences how effectively an organization can leverage its information. Its seamless operation often begins much earlier, critically linked to the efficiency of the Ingestion Layer, which dictates the flow and initial characteristics of incoming data. A well-considered storage strategy is not just about holding data; it is about making it accessible, performant, and secure from the moment it enters the system, fundamentally shaping an organization’s analytical and operational capabilities.
Introduction: The Foundational Role of the Storage Layer in Modern Data Architectures
In today’s data-driven world, the sheer volume, velocity, and variety of information flowing into organizations demand sophisticated and flexible storage solutions. The storage layer serves as the persistent repository for all processed and raw data, providing the foundational infrastructure for analytics, applications, and operational systems. Its design determines data retrieval speed, overall system responsiveness, and critically, the ability to derive timely insights. A poorly chosen storage strategy can bottleneck an entire data pipeline, rendering even the most advanced analytics tools ineffective. This article will delve into the intricacies of selecting the right data storage strategy, emphasizing its critical interplay with the Ingestion Layer, exploring diverse technologies, and outlining a strategic framework for decision-making.
The efficiency of the storage layer is inextricably linked to the capabilities of the Ingestion Layer. High-velocity data streams from IoT devices, real-time application logs, or continuous data feeds necessitate storage solutions capable of rapid writes, horizontal scalability, and immediate availability. Conversely, batch ingestion might allow for more cost-effective cold storage options. Understanding the characteristics of data at the point of entry – its volume, frequency, structure, and intended use – is paramount for tailoring a storage strategy that is both performant and economical. Our objective is to provide a comprehensive guide to navigating these complexities, ensuring data is not just stored, but strategically positioned for maximum business value.
Core Breakdown: Dissecting the Storage Layer’s Components and Considerations
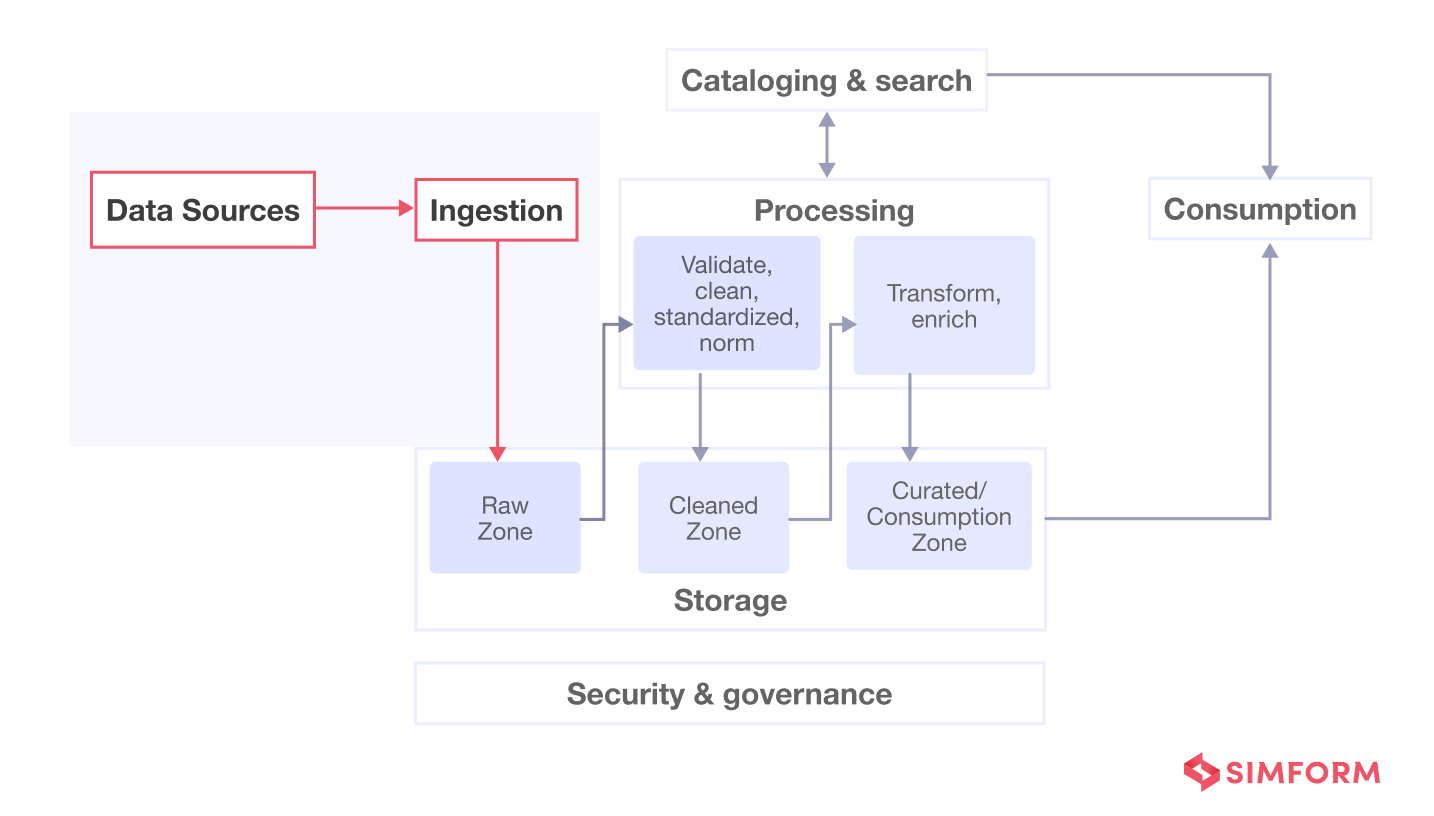
The modern storage layer is far from monolithic, encompassing a spectrum of technologies and architectural patterns designed to address diverse data needs. From foundational infrastructure to advanced governance features, each element plays a vital role in creating an efficient, scalable, and secure data environment. The choice of storage strategy is deeply influenced by the nature of data arriving from the Ingestion Layer, dictating requirements for performance, scalability, and data type handling.
Platform Categories: Tailoring Storage to Data Needs
- Data Lake: Designed for storing vast amounts of raw, multi-structured data (structured, semi-structured, unstructured) at a low cost. Often built on cloud object storage like AWS S3, Azure Data Lake Storage, or Google Cloud Storage, or distributed file systems like Apache HDFS. It excels at accommodating data directly from the Ingestion Layer without prior transformation, preserving its original format for future use cases, including advanced analytics and machine learning.
- Data Warehouse: Optimized for structured, clean, and transformed data, primarily used for business intelligence (BI) and reporting. Solutions like Snowflake or traditional relational databases offer high performance for complex analytical queries. Data typically arrives here after undergoing significant processing and transformation, often orchestrated by robust ETL/ELT pipelines from the Ingestion Layer.
- Object Storage: Highly scalable, durable, and cost-effective storage for unstructured data (images, videos, backups, data lake components). Examples include AWS S3, Azure Blob Storage, and Google Cloud Storage. Its pay-as-you-go model makes it ideal for handling bursts of data from various Ingestion Layer sources.
- Block Storage: Provides raw storage volumes that can be attached to compute instances. Offers high performance and low latency, suitable for databases, virtual machines, and transactional workloads. Often used where disk I/O performance is critical, supporting applications that demand direct, fast access to data.
- File Storage: Organizes data into files and folders, accessible via network file system protocols (NFS, SMB). Ideal for shared file access, content repositories, and specific application needs where a hierarchical file system is required.
- Hybrid Cloud Storage: A strategy that combines on-premises and cloud storage, allowing organizations to leverage the benefits of both. This offers flexibility for data governance, compliance, and cost optimization, especially for organizations with legacy systems or specific regulatory requirements for data originating from diverse Ingestion Layer endpoints.
Core Technology/Architecture: The Engines of Data Storage
Beneath the platform categories lie the core technologies that power these storage solutions:
- Distributed File Systems (e.g., HDFS): Designed for massive scalability and fault tolerance, ideal for big data processing frameworks like Apache Hadoop and Spark. Essential for managing vast data sets sourced by a high-throughput Ingestion Layer.
- Cloud Object Storage (e.g., S3, Azure Blob): Highly durable, scalable, and cost-effective for unstructured data. Offers robust APIs for integration and serves as the backbone for cloud-native data lakes.
- Relational Databases (e.g., PostgreSQL): Provide structured storage with strong consistency, ideal for transactional data requiring ACID properties.
- NoSQL Databases (e.g., MongoDB, Cassandra): Offer flexibility, horizontal scalability, and high performance for semi-structured and unstructured data, often categorized by specific data models like document, key-value, graph, or columnar. Their schema-less nature makes them agile for evolving data structures from the Ingestion Layer.
- Columnar Storage: Optimizes data for analytical queries by storing data in columns rather than rows. This significantly improves performance for aggregations and filtering, common in data warehouses and analytical databases.
- Data Lakehouse Architecture: A relatively new paradigm that attempts to combine the flexibility and cost-effectiveness of data lakes with the ACID transactions and data governance features of data warehouses. Technologies like Databricks’ Delta Lake exemplify this, bridging the gap between raw data from the Ingestion Layer and curated analytical insights.
Key Data Governance Features: Ensuring Trust and Compliance
Robust data governance is non-negotiable for any storage strategy, especially given the diverse data types and sources from the Ingestion Layer. Key features include:
- Data Encryption at Rest and in Transit: Protecting data both when stored and when moving across networks.
- Access Controls (ACLs, IAM policies): Granular control over who can access, modify, or delete data.
- Data Retention Policies: Defining how long data should be kept, crucial for compliance and cost management.
- Audit Logging: Tracking all data access and modification activities for security and compliance purposes.
- Data Masking: Obscuring sensitive data for non-production environments or specific user groups.
- Data Catalog Integration: Providing metadata, lineage, and discovery capabilities to understand and manage data assets effectively.
Primary AI/ML Integration: Powering Advanced Analytics
The storage layer must be optimized for the demanding requirements of AI and Machine Learning workloads:
- Optimized for large-scale data processing (e.g., Parquet, ORC formats): These columnar formats enable efficient storage and retrieval of large datasets, critical for ML model training and inference.
- Direct integration with ML frameworks and platforms (e.g., Apache Spark, TensorFlow): Seamless connectors allow ML engineers and data scientists to access and process data directly from storage.
- High-throughput data access for model training: ML models often require reading massive datasets repeatedly, necessitating storage solutions that can deliver data quickly.
- Support for unstructured data for deep learning: Object storage is particularly vital here, housing the images, audio, and video essential for training deep learning models.
Challenges/Barriers to Adoption: Navigating the Complexities
Despite the immense potential, implementing and managing an optimal storage layer presents several significant challenges:
- Data Sprawl and Silos: Uncontrolled growth of data across disparate storage systems can lead to silos, making data discovery and integration difficult. The diverse origins from the Ingestion Layer often contribute to this.
- Cost Optimization: Balancing performance requirements with cost-effectiveness is a continuous struggle. Over-provisioning leads to unnecessary expenses, while under-provisioning impacts performance and user experience. Tiered storage strategies are crucial here.
- Data Governance Complexity: Ensuring compliance with regulations (e.g., GDPR, CCPA) across varied storage types and geographically dispersed data is incredibly challenging. Implementing consistent access controls and retention policies across hybrid environments adds layers of complexity.
- Performance Tuning: Optimizing storage for diverse workloads—from high-volume transactional processing to ad-hoc analytical queries and intensive ML training—requires deep technical expertise and continuous monitoring.
- Integration with Existing Pipelines: Seamlessly integrating new storage solutions with established Ingestion Layer and processing pipelines can be a significant undertaking, often requiring custom connectors or middleware.
- Security in Hybrid Environments: Extending security measures across on-premises and multiple cloud providers, especially when data moves between them, introduces potential vulnerabilities if not managed meticulously.
Business Value and ROI: The Strategic Payoffs of a Smart Storage Strategy
A well-architected storage layer, mindful of the data’s journey from the Ingestion Layer, delivers substantial business value:
- Faster Data Access and Insights: Optimized storage enables quicker retrieval and processing of data, leading to faster analytical cycles and more timely business decisions.
- Improved Analytics and AI Capabilities: Providing the right data in the right format at the right speed unlocks advanced analytics, machine learning, and deep learning opportunities, driving innovation and competitive advantage.
- Enhanced Compliance and Risk Management: Robust data governance features ensure regulatory adherence, protect sensitive information, and reduce the risk of data breaches and legal penalties.
- Scalability and Agility: A flexible storage strategy can effortlessly scale to accommodate growing data volumes and evolving business needs, avoiding costly re-architecture. This is especially vital when new, high-volume data sources are added to the Ingestion Layer.
- Cost Savings and Efficiency: By intelligently tiering data and selecting appropriate technologies, organizations can significantly reduce storage expenditures while maintaining performance.
- Support for Diverse Data Needs: Accommodating structured, semi-structured, and unstructured data enables a holistic view of the business and supports a broader range of applications.

Comparative Insight: Modern Storage vs. Traditional Data Paradigms
The evolution of the storage layer can be best understood by comparing it to its predecessors and examining how current trends address past limitations. Traditionally, organizations relied heavily on relational databases for structured data, eventually progressing to separate Data Warehouses for analytical workloads. The rise of big data and the need to store massive volumes of raw, unstructured, and semi-structured information led to the popularization of the Data Lake.
While Data Lakes excel at cost-effectively storing diverse data directly from the Ingestion Layer, they often struggle with data governance, quality, and performance for complex queries, sometimes becoming “data swamps.” Data Warehouses, on the other hand, offer robust governance and high performance for structured queries but are less flexible for raw or semi-structured data and can be expensive to scale. The choices made in the Ingestion Layer—whether real-time streaming or batch, structured or unstructured—directly influence the effectiveness of these downstream storage models.
Modern storage strategies, particularly the Data Lakehouse architecture, aim to combine the best aspects of both. By building a transactional layer (like Delta Lake, Apache Iceberg, or Apache Hudi) on top of a Data Lake (often object storage), organizations gain the flexibility of storing raw data alongside the ACID properties and performance characteristics typically found in data warehouses. This hybrid approach enables unified data governance, improved data quality, and simplified data pipelines from the Ingestion Layer all the way through to analytics and machine learning. Furthermore, the rise of specialized databases, columnar storage formats like Parquet and ORC, and managed cloud services (e.g., Snowflake, Databricks) further blurs the lines, offering optimized solutions for specific use cases while demanding careful integration planning with the initial Ingestion Layer.
World2Data Verdict: Embracing a Dynamic, Layered Storage Ecosystem
The optimal data storage strategy for any organization is no longer a singular choice but a dynamic, layered ecosystem tailored to specific needs, workloads, and data characteristics. World2Data.com advocates for a pragmatic, hybrid approach that prioritizes flexibility, cost-efficiency, and robust governance, starting from the very first interaction with the Ingestion Layer. Organizations must move beyond the “one-size-fits-all” mentality and adopt a multi-modal storage architecture that combines the strengths of various technologies – leveraging cloud object storage for raw data lakes, specialized data warehouses for business intelligence, and NoSQL databases for high-performance applications. The future of data storage lies in intelligent data tiering, where data automatically migrates to the most cost-effective and performant storage solution based on its access patterns, age, and business value. Investing in a robust data catalog and strong data governance frameworks is paramount to ensure discoverability, trust, and compliance across this diverse landscape. Ultimately, the success of your storage strategy hinges on its ability to seamlessly support the demanding and ever-evolving requirements originating from your Ingestion Layer, transforming raw data into actionable intelligence with speed, security, and scalability.

{kind=link}