


Data Mesh: The Decentralized Data Architecture for True Business Agility
1. Platform Category: Data Architecture Paradigm
2. Core Technology/Architecture: Decentralized, Domain-Driven Design, Data as a Product
3. Key Data Governance Feature: Federated Computational Governance
4. Primary AI/ML Integration: Enables domain teams to build and serve ML models as data products
5. Main Competitors/Alternatives: Centralized Data Warehouse, Data Lake, Data Lakehouse
In the evolving landscape of data management, Data Mesh stands out as a transformative decentralized data architecture. It empowers organizations to overcome the bottlenecks of traditional centralized systems by treating data as a product, owned and managed by the business domains closest to it. This paradigm shift fosters unprecedented business agility, enhances data quality, and accelerates time to insight, making data a truly strategic asset for innovation and sustained competitive advantage.
Introduction: Reshaping Data Management for the Product Data Era
The digital economy thrives on data. Every customer interaction, every operational process, and every strategic decision is increasingly data-driven. However, traditional centralized data architectures, such as the monolithic data warehouse and the sprawling data lake, often struggle to keep pace with the demands of modern enterprises. While these architectures served their purpose in earlier eras, their centralized nature frequently leads to bottlenecks, slow data delivery, and a disconnect between data producers and consumers. A single, overburdened central data team becomes a choke point, hindering the rapid iteration and diverse data needs of numerous product and operational teams.
This challenge is amplified in an increasingly product-centric world, where business units need rapid, self-service access to high-quality, domain-specific data to build innovative features, personalize experiences, and optimize operations. The limitations of a centralized model, particularly its impact on agility and the speed of insights, paved the way for a revolutionary approach: the Data Mesh. This architectural paradigm shift redefines data ownership and access, empowering individual product domains to manage and serve their data, thereby unlocking the full potential of an organization’s most valuable asset. It’s not just about technology; it’s about a fundamental rethinking of how organizations interact with and leverage data at scale to achieve genuine business agility.
Core Breakdown: The Four Pillars of a Decentralized Data Architecture
At its heart, the Data Mesh architecture is built upon four foundational principles that fundamentally transform how organizations manage and utilize data. These principles address the limitations of centralized approaches by promoting decentralization, ownership, and self-service capabilities, fostering a more agile and scalable data ecosystem.
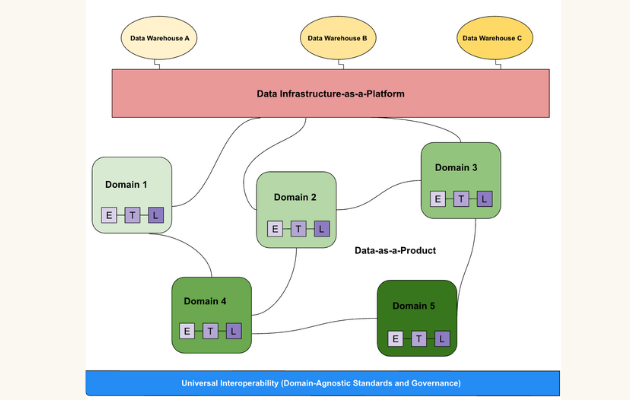
1. Domain-Oriented Decentralized Data Ownership
Instead of a single, central data team bearing the sole responsibility for all data, Data Mesh advocates for distributing data ownership to the business domains that generate and consume the data. A domain could be a specific business unit like “Customer Profiles,” “Order Fulfillment,” “Recommendation Engine,” or “Fraud Detection.” These domain teams, already deeply familiar with their operational data and business logic, become fully accountable for the data they produce and serve. This decentralization fosters a greater sense of ownership, ensures domain expertise is applied directly to data management, and eliminates the bottleneck of a central team trying to understand and serve all data needs across the entire organization. It aligns data ownership with business capabilities, making data a first-class citizen within the domain’s responsibility.
2. Data as a Product
This principle is arguably the most transformative aspect of Data Mesh. Domain teams are required to treat their data as a high-quality product that they deliver to other consumers within the organization. Just like any product, data products must be discoverable, addressable, trustworthy, interoperable, and valuable. This means ensuring clear documentation, well-defined schemas, consistent quality, and easy accessibility. A data product is not just raw data; it’s a curated, refined, and served dataset designed for specific use cases, complete with its own lifecycle, SLAs, and dedicated support from the producing domain team. This shift ensures data consumers receive reliable, ready-to-use data, rather than having to clean and transform raw data themselves.
3. Self-Serve Data Infrastructure as a Platform
To enable domain teams to effectively treat data as a product without becoming overwhelmed by infrastructure complexities, a Data Mesh requires a self-serve data infrastructure platform. This platform provides the foundational tools, services, and automation capabilities that abstract away the underlying technological complexities of data storage, processing, governance, and serving. It offers domain teams a set of capabilities – like data ingestion pipelines, storage solutions, compute environments, monitoring tools, and access controls – through a user-friendly interface or API. This allows domain teams to focus on creating valuable data products, rather than managing the intricacies of the underlying data infrastructure. The platform team acts as an enabler, providing the necessary guardrails and tools for autonomy.
4. Federated Computational Governance
While promoting decentralization, Data Mesh does not imply anarchy. Federated computational governance establishes a framework for global interoperability, security, and compliance across all data products, while still respecting local domain autonomy. Instead of a single, centralized governing body imposing rigid rules, governance is achieved through a federation of domain representatives and central data experts. This federation collaboratively defines global policies (e.g., data privacy standards, security protocols, interoperability standards) that are then enforced computationally through the self-serve platform. This ensures consistency and adherence to organizational and regulatory requirements without stifling innovation or agility within individual domains. It provides a balance between global consistency and local flexibility.
Challenges and Barriers to Adoption
Implementing a Data Mesh is a significant undertaking that extends beyond mere technical infrastructure. It introduces several challenges and potential barriers:
- Cultural and Organizational Shift: The most substantial hurdle is often organizational resistance. Moving from a centralized model to empowered domain teams requires a fundamental change in mindset, roles, and responsibilities. It necessitates breaking down traditional silos, fostering a culture of data ownership, and upskilling cross-functional teams with data expertise.
- Initial Investment and Complexity: Establishing the self-serve data infrastructure platform, migrating existing data products, and re-architecting data pipelines require substantial initial investment in technology, talent, and time. The conceptual clarity of Data Mesh can sometimes mask the practical complexities of integration across diverse legacy systems.
- Interoperability and Standardization: While federated governance aims for consistency, ensuring seamless interoperability between data products from different domains can be challenging. Defining common standards for data contracts, metadata, and APIs is critical but can be difficult to enforce consistently across many autonomous teams.
- Data Lineage and Discovery: In a decentralized environment, tracing the lineage of data and ensuring effective discoverability of available data products can become complex. Robust metadata management and cataloging tools are essential to prevent the creation of “mini data swamps” within domains.
- Security and Compliance: Distributing data ownership means distributing security and compliance responsibilities. Ensuring all domain teams adhere to global security policies and regulatory requirements (like GDPR or HIPAA) requires robust automated enforcement mechanisms and continuous monitoring, adding a layer of complexity to governance.
Business Value and ROI
Despite the challenges, the adoption of a Data Mesh offers compelling business value and significant return on investment, making it a strategic choice for forward-thinking organizations:
- Enhanced Business Agility and Faster Time to Insight: By empowering domain teams, organizations can significantly reduce the lead time for data access and insight generation. Product teams can iterate faster, develop new features with relevant data more quickly, and respond to market changes with greater speed.
- Improved Data Quality and Trust: Domain experts, being closest to the data, are best positioned to ensure its accuracy, completeness, and reliability. This direct accountability leads to higher data quality and increased trust in data products across the organization, crucial for critical decision-making.
- Reduced Bottlenecks and Operational Costs: Eliminating the central data team as a single bottleneck frees up resources and reduces operational friction. Domain teams can work autonomously, reducing dependencies and the costs associated with lengthy data request cycles and custom data engineering efforts.
- Accelerated Innovation and Experimentation: With self-serve capabilities and direct ownership, domain teams are empowered to experiment with data, build new data products, and integrate machine learning models as data products (aligning with the “Primary AI/ML Integration” point) much more rapidly. This fosters a culture of innovation and data-driven product development.
- Scalability and Decentralized Growth: The architectural pattern naturally scales with the organization. As new business domains emerge or existing ones expand, they can integrate into the mesh without overwhelming a central data team, allowing for organic and efficient data ecosystem growth.
- Better Alignment with MLOps Practices: By treating ML models and features as data products, Data Mesh inherently supports MLOps principles, enabling domain teams to deploy, monitor, and manage their models with greater autonomy and efficiency, tightly integrating ML into the business domain’s operational fabric.
Comparative Insight: Data Mesh vs. Traditional Architectures
Understanding the distinct advantages of Data Mesh requires a comparative look at the data architectures it aims to supersede: the Centralized Data Warehouse, the Data Lake, and the Data Lakehouse. While each of these has its merits and historical significance, they fundamentally differ from the Data Mesh paradigm in their approach to ownership, structure, and agility.
Traditional Data Warehouse
The traditional data warehouse is a centralized repository of structured, integrated data, primarily designed for business intelligence and reporting. Data is typically extracted from operational systems, transformed, and loaded (ETL) into a predefined schema. While excellent for consistent, aggregated reporting and historical analysis, data warehouses suffer from inflexibility. Schema changes are slow, new data sources are difficult to integrate, and they often struggle with diverse, unstructured data. The central data team owns and controls all data, becoming a bottleneck for agile data access and new use cases, particularly for domain-specific analytics or machine learning initiatives.
Data Lake
Data lakes emerged to address the inflexibility of data warehouses by offering a centralized storage location for vast amounts of raw, diverse data – structured, semi-structured, and unstructured. They use a “schema-on-read” approach, providing greater flexibility for storing various data types. While data lakes democratized storage and allowed for more experimental analytics, they often become “data swamps” without robust governance, metadata management, and clear ownership. Data quality can be inconsistent, and extracting value from the raw data often requires significant effort from data engineers or scientists, still typically centralized, leading to similar bottlenecks as the data warehouse in terms of insight delivery.
Data Lakehouse
The Data Lakehouse attempts to combine the best of both worlds: the flexibility and scalability of data lakes with the data management and ACID transaction capabilities typically found in data warehouses. It aims to provide a unified platform for both analytics and machine learning, often leveraging open table formats like Delta Lake or Apache Iceberg. While a significant improvement over standalone lakes and warehouses, many Lakehouse implementations still lean towards a centralized ownership and operational model. Data governance, while improved, often remains a centralized function, and the underlying data platform is typically managed by a single team. This can still lead to some degree of bottleneck for highly agile, domain-specific requirements, especially in large, complex organizations with many autonomous product teams.
Data Mesh Differentiators
Data Mesh fundamentally diverges from these alternatives primarily through its decentralization of ownership and its “data as a product” philosophy:
- Ownership and Accountability: Unlike the centralized ownership in warehouses, lakes, and lakehouses, Data Mesh pushes ownership and accountability to the business domains. This eliminates the central bottleneck and ensures domain experts are directly responsible for the quality and utility of their data.
- Data as a Product: Data Mesh elevates data beyond mere storage or processing artifacts. Each domain’s data is treated as a product with clear APIs, SLAs, and dedicated support, ensuring discoverability, reliability, and immediate value for consumers. Traditional architectures often view data as a byproduct or a raw material that needs significant work before it becomes useful.
- Distributed Architecture: While a data lake or lakehouse can store distributed data, the governance and management layers often remain centralized. Data Mesh decentralizes the entire data lifecycle, from ingestion to serving, governed by a federated model that balances autonomy with global standards.
- Agility and Scalability: By empowering domains, Data Mesh inherently promotes greater agility, as product teams can innovate independently with their data products. It scales more naturally with organizational growth, avoiding the performance degradation and complexity common in growing centralized systems.
- Native MLOps Alignment: Data Mesh is particularly well-suited for modern MLOps (Machine Learning Operations) needs. By structuring features and models as data products, it allows for seamless integration of ML workflows directly within domain teams, fostering faster deployment and better model governance, which traditional architectures often struggle to support without significant custom engineering.
In essence, while traditional architectures focus on centralizing data for efficiency, Data Mesh focuses on decentralizing data ownership and responsibility to maximize agility, quality, and domain-specific innovation, making it uniquely positioned for enterprises operating in a rapidly evolving, data-driven product landscape.
World2Data Verdict: Embracing the Future of Data-Driven Enterprise
World2Data.com believes that Data Mesh is not merely an architectural choice but a strategic imperative for enterprises striving for true data-driven agility and innovation in the product era. While demanding significant organizational and cultural shifts, its promise of decentralized ownership and data-as-a-product thinking provides the robust framework for scalable, high-quality data ecosystems that directly fuel business growth and empower autonomous, data-savvy domain teams. Organizations that are ready to embrace this evolution will find themselves uniquely positioned to leverage data as their most competitive asset, driving faster insights, superior product development, and sustained differentiation. The future of enterprise data management lies in empowering those closest to the data to own its lifecycle, transforming data from a mere resource into a powerful, self-sustaining product ecosystem. Adopting Data Mesh means investing in a future where data fuels every aspect of your business with unprecedented speed and precision.

{kind=link}