


MLOps vs DataOps: Bridging the Divide for Seamless AI with Integrated Operational Frameworks
The realms of data management and machine learning operations are converging, making the topic of MLOps vs DataOps critically important for modern enterprises. As artificial intelligence applications move from experimental stages to core business functions, understanding the nuanced differences and, more importantly, the strategies for effective MLOps vs DataOps Integration becomes paramount. Both methodologies aim to streamline processes and enhance reliability, but their distinct focal points present unique opportunities for synergistic collaboration that drives superior AI outcomes.
Introduction: Setting the Stage for Operational Frameworks in AI
In the rapidly evolving landscape of data-driven innovation, organizations are increasingly relying on sophisticated operational frameworks to manage their data and machine learning lifecycles. This article delves into MLOps and DataOps, two such pivotal frameworks categorized under Operational Frameworks, exploring their core technologies, architectures, and the profound benefits of their integration. While MLOps focuses on the systematic development and deployment of machine learning models, DataOps ensures the integrity and efficiency of the underlying data pipelines that fuel these models. The objective here is to delineate their respective scopes, highlight their synergistic potential, and offer actionable insights into achieving robust MLOps vs DataOps Integration.
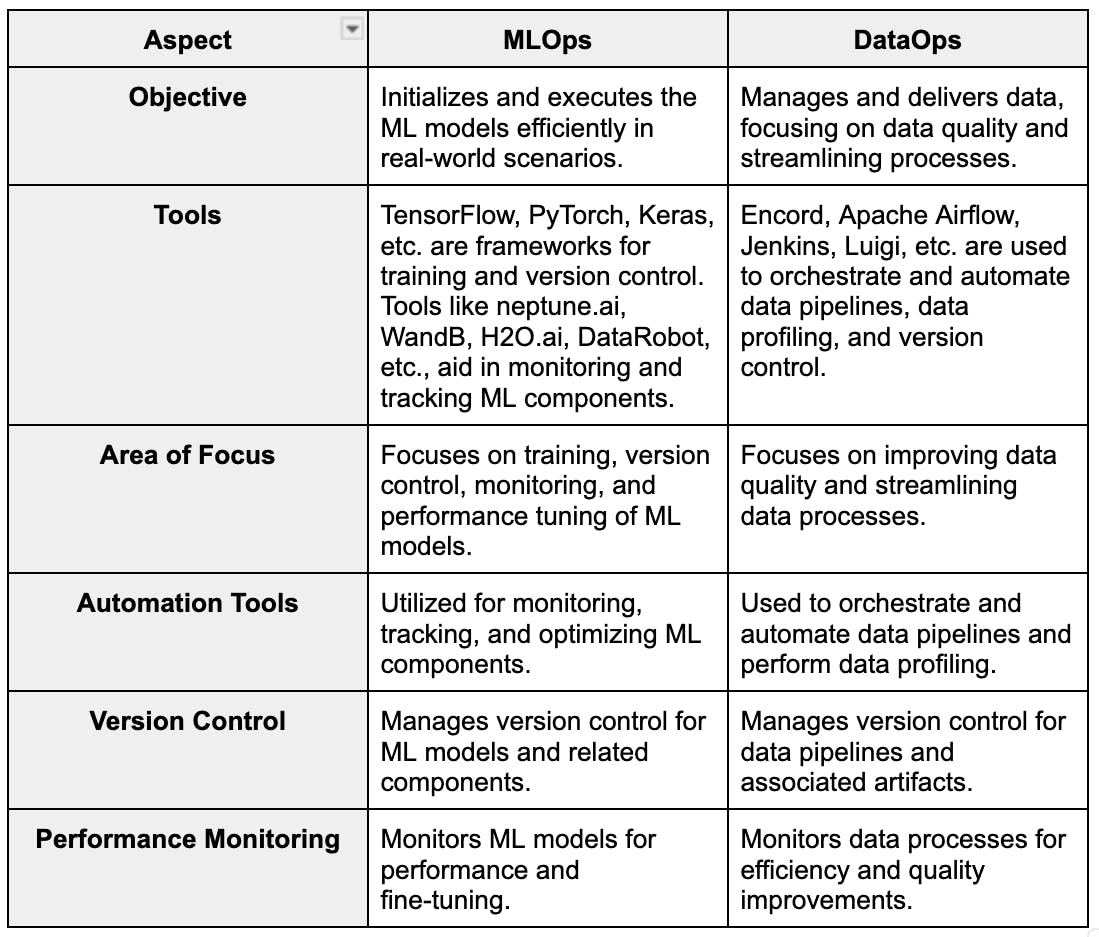
At their core, both MLOps and DataOps leverage principles of CI/CD (Continuous Integration/Continuous Deployment) pipelines, automation, and orchestration to enhance efficiency and reliability. DataOps is inherently concerned with Data Quality and Lineage, ensuring that the data consumed by any system, especially AI/ML, is accurate, consistent, and traceable. MLOps, on the other hand, prioritens Model Governance and Versioning, safeguarding the performance, reproducibility, and ethical deployment of AI models. The primary AI/ML integration point manifests when DataOps provides automated, high-quality data pipelines, which then feed seamlessly into MLOps model training and deployment cycles, forming an unbreakable chain of trust and efficiency from raw data to deployed AI insights.
Core Breakdown: Dissecting MLOps and DataOps Architectures
To truly appreciate the value of MLOps vs DataOps Integration, it’s essential to understand each framework in isolation before exploring their combined power. Each represents a distinct, yet complementary, approach to managing complex technological ecosystems.
Understanding MLOps: The Machine Learning Lifecycle Orchestrator
MLOps (Machine Learning Operations) is a set of practices that aims to deploy and maintain ML models in production reliably and efficiently. It extends the DevOps principles of CI/CD to the machine learning lifecycle, encompassing everything from data preparation and model training to deployment, monitoring, and continuous retraining. Key components of an MLOps architecture include:
- Experiment Tracking and Management: Tools for logging experiments, hyper-parameters, metrics, and models.
- Data Versioning: Ensuring that specific versions of data used for training can be tracked and reproduced.
- Model Versioning and Registry: A centralized repository for managing different versions of models, enabling rollbacks and clear lineage.
- Automated Model Training and Retraining Pipelines: CI/CD pipelines that automatically trigger model training upon new data arrival or code changes.
- Automated Model Deployment: Systems for deploying trained models to production environments (e.g., APIs, batch processing).
- Model Monitoring: Continuous tracking of model performance, data drift, concept drift, and prediction quality in real-time.
- Reproducibility: Ensuring that any model outcome can be recreated given the specific data and code versions.
- Infrastructure Management: Tools for provisioning and managing the compute resources for ML workloads.
The ultimate goal of MLOps is to reduce the time-to-value for machine learning initiatives, improve the reliability of models in production, and foster better collaboration between data scientists, ML engineers, and operations teams.
Understanding DataOps: The Data Lifecycle Enabler
DataOps (Data Operations) is a collaborative, process-oriented methodology for improving the quality and reducing the cycle time of data analytics. It applies agile development, DevOps, and statistical process control to data management, emphasizing automation, continuous delivery, and monitoring across the entire data lifecycle. Critical elements of a DataOps framework typically involve:
- Automated Data Ingestion and Transformation: Pipelines for efficiently acquiring data from various sources and transforming it into usable formats.
- Data Quality Assurance: Proactive monitoring and validation of data quality at every stage of the pipeline, using automated tests and alerts.
- Data Lineage and Governance: Tracking the origin, transformations, and usage of data, ensuring compliance with regulatory requirements and internal policies. DataOps establishes robust Data Quality and Lineage protocols to ensure data integrity.
- Data Security and Access Management: Implementing controls to protect sensitive data and manage access rights efficiently.
- Environment Management: Providing isolated, reproducible environments for data development and testing.
- Collaboration Tools: Facilitating seamless interaction between data engineers, data analysts, and other stakeholders.
- Continuous Monitoring and Alerting: Real-time oversight of data pipelines for performance, errors, and quality deviations.
DataOps strives to deliver trustworthy, accessible, and timely data to all consumers, including analytics platforms and, crucially, machine learning systems, ensuring they operate on the best possible information.
Challenges and Barriers to Adoption
Despite the clear benefits, organizations face several hurdles in adopting and integrating MLOps and DataOps:
- Data Silos and Fragmentation: Data often resides in disparate systems with inconsistent formats, making unified data pipelines challenging.
- Skill Gaps: A shortage of professionals skilled in both data engineering and machine learning operations.
- Tool Proliferation: The vast ecosystem of tools for data management and ML can lead to complexity and integration headaches.
- Cultural Resistance: Bridging the gap between traditionally separate data, development, and operations teams requires significant cultural shifts.
- Data Drift and Model Decay: ML models trained on historical data may degrade in performance over time due to changes in real-world data distributions, necessitating continuous retraining and robust data pipelines.
- MLOps Complexity: Managing model experimentation, versioning, deployment, and monitoring across various environments is inherently complex.
- Data Quality Issues: Poor data quality upstream can invalidate ML models, yet addressing it requires deep integration with data governance practices.
Business Value and ROI of Integrated MLOps and DataOps
Overcoming these challenges through effective MLOps vs DataOps Integration unlocks significant business value and ROI:
- Faster Time-to-Market for AI/ML Solutions: Automated, integrated pipelines drastically reduce the cycle time from data ingestion to model deployment.
- Improved Model Performance and Reliability: Models are trained on consistently high-quality, relevant data and continuously monitored, leading to more accurate and reliable predictions.
- Enhanced Data Quality for AI: DataOps practices ensure that the data feeding ML models is validated, clean, and consistent, directly impacting model efficacy.
- Operational Efficiency and Cost Reduction: Automation minimizes manual errors, reduces operational overhead, and optimizes resource utilization across both data and ML infrastructures.
- Reduced Risk and Enhanced Compliance: Robust data lineage and model governance (Model Governance and Versioning) ensure transparency, auditability, and adherence to regulatory requirements.
- Better Decision-Making: Reliable data and accurate models lead to more informed and impactful business decisions.
- Scalability: A well-integrated framework scales seamlessly with increasing data volumes and the growing number of ML models.
Comparative Insight: MLOps/DataOps Integration vs. Manual & Siloed Approaches
To truly grasp the transformative power of a combined MLOps and DataOps strategy, it’s beneficial to compare it against its main competitors/alternatives: manual data management and ad-hoc ML model deployment. Historically, organizations often managed their data and machine learning processes in separate, siloed operations, leading to inefficiencies, inconsistencies, and significant bottlenecks.
The Limitations of Siloed Operations
- Manual Data Management: In traditional setups, data preparation, cleaning, and validation are often manual, prone to human error, and time-consuming. This directly impacts data quality, making it difficult to trust the data used for analytical or ML purposes. Data lineage is often poorly documented or nonexistent, hindering auditing and compliance.
- Ad-hoc ML Model Deployment: Without a structured MLOps framework, deploying ML models can be an artisanal process. Models are often developed on local machines, with inconsistent environments, lack of version control for code and models, and manual handoffs to operations teams. This leads to slow deployments, difficulty in reproducing results, lack of monitoring, and significant challenges in retraining models effectively.
- Disconnected Governance: Key Data Governance Features are often fragmented. Data quality and lineage might be managed in one system (or not at all), while model governance and versioning are overlooked, leading to unexplainable models and regulatory risks.
- Delayed Innovation: The friction between data providers and ML consumers creates significant delays in iterating on models and deploying new AI-powered features, slowing down innovation and competitive advantage.
- Technical Debt Accumulation: Lack of standardized processes and automation leads to a buildup of technical debt, making systems harder to maintain and evolve.
The Integrated Advantage
The integrated approach of MLOps vs DataOps Integration systematically addresses these limitations by fostering a continuous, automated, and collaborative environment. By harmonizing their distinct strengths, organizations can achieve a synergy that far surpasses what either framework could deliver in isolation.
- Seamless Data Flow to Models: DataOps ensures that ML models consistently receive high-quality, verified, and timely data, eliminating a major source of model errors and performance degradation. Automated data pipelines feed directly into automated model training processes.
- End-to-End Governance: With integration, organizations establish comprehensive governance that spans both data and models. DataOps provides robust Data Quality and Lineage, ensuring data integrity from source to consumption. MLOps then takes over with strong Model Governance and Versioning, ensuring that models are developed, deployed, and monitored responsibly, with clear audit trails and ethical considerations.
- Accelerated Innovation Cycles: The automation and continuous processes inherent in integrated DataOps and MLOps drastically reduce the time from data acquisition to model deployment and iteration. This allows businesses to experiment faster, deploy more frequently, and adapt to market changes with agility.
- Reproducibility and Auditability: Every step, from data ingestion to model prediction, is versioned and trackable. This is crucial for debugging, regulatory compliance, and building trust in AI systems.
- Optimized Resource Utilization: Automation and orchestration across the data and ML stack lead to more efficient use of compute and storage resources, reducing operational costs.
Effective MLOps and DataOps Integration Strategies
Achieving successful MLOps vs DataOps Integration is not merely about adopting both frameworks; it requires a deliberate strategy that unifies their principles and operational workflows. The goal is to create a cohesive ecosystem where data flows seamlessly, models are robust, and collaboration is paramount.
- Establish a Unified Data Platform:
- Centralized Data Repository: Implement a modern data platform (e.g., a data lakehouse architecture) that serves as a single source of truth for all data, regardless of its ultimate consumer. This minimizes data silos and ensures consistency.
- Standardized Data Formats and APIs: Enforce common data schemas and provide well-documented APIs for accessing data, simplifying its consumption by MLOps pipelines.
- Metadata Management: Implement comprehensive metadata management that tracks data lineage, quality metrics, and usage across the entire data lifecycle. This empowers both DataOps and MLOps teams to understand the context and reliability of their data.
- Implement Shared Governance Policies:
- Joint Data and Model Governance: Develop governance policies that span both data quality and model performance. DataOps ensures the integrity of input data, while MLOps ensures the reliability of the output model.
- Access Control and Security: Harmonize security protocols and access management for both data assets and ML models, ensuring compliance and data protection.
- Compliance and Auditability: Design systems to inherently support audit trails for both data transformations and model decisions, critical for regulatory compliance (e.g., GDPR, CCPA).
- Leverage Common Toolchains and Automation:
- Integrated CI/CD Pipelines: Extend CI/CD practices to cover the entire journey from data ingestion (DataOps) to model deployment and monitoring (MLOps). Tools like Apache Airflow, Kubeflow, or cloud-native services can orchestrate these end-to-end workflows.
- Data and Model Versioning: Utilize tools that support robust versioning for both datasets and ML models. This ensures reproducibility and allows for easy rollbacks and experimentation.
- Automated Testing: Implement automated tests for data quality (DataOps) and model validation (MLOps). Data tests ensure data integrity before training, and model tests ensure performance and fairness after training and before deployment.
- Centralized Monitoring and Alerting: Use integrated dashboards and alerting systems to monitor data pipelines, infrastructure health, model performance, and data/concept drift.
- Foster Cross-Functional Teams and Collaboration:
- Shared Ownership: Encourage data engineers, data scientists, and ML engineers to collaborate closely, potentially even forming integrated “AI Product Teams” with shared KPIs.
- Documentation and Knowledge Sharing: Emphasize clear documentation of data pipelines, model specifications, and operational procedures to break down knowledge silos.
- Feedback Loops: Establish strong feedback loops where insights from model monitoring (MLOps) can inform data quality improvements or new data acquisition strategies (DataOps).
- Gradual Implementation and Iteration:
- Start Small: Begin with integrating DataOps and MLOps for a critical, well-defined AI project before scaling across the organization.
- Continuous Improvement: Treat the integration process itself as an iterative project, continuously refining processes, tools, and team structures based on feedback and performance metrics.
World2Data Verdict: The Imperative for a Unified Operational AI Ecosystem
The distinction between MLOps and DataOps is becoming increasingly blurred as organizations mature in their AI journeys. World2Data’s verdict is clear: successful, scalable, and responsible AI requires a unified operational ecosystem where MLOps vs DataOps Integration is not just an advantage, but an absolute imperative. Attempting to manage machine learning models without robust, automated data pipelines, or conversely, having pristine data without efficient model operationalization, will inevitably lead to bottlenecks, unreliable AI systems, and untapped potential.
Looking ahead, the future of enterprise AI lies in platforms that seamlessly merge the capabilities of both DataOps and MLOps, offering end-to-end automation, comprehensive governance, and a collaborative environment from data ingestion to model retirement. Companies that proactively invest in this integration will not only accelerate their AI initiatives but also build a resilient, trustworthy, and future-proof foundation for continuous innovation. The strategic amalgamation of these frameworks will transform data and models into a powerful, agile engine for business growth, ensuring that AI-driven insights are consistently reliable, timely, and impactful.

{kind=link}