


Unlocking Data’s Full Potential: Deep Dive into AI Trends in Metadata Management
The landscape of data management is undergoing a profound transformation, spearheaded by sophisticated AI capabilities. This article delves into the critical role of AI Metadata Management Trends in shaping modern data ecosystems. From enhancing data discovery and cataloging to fortifying data governance and quality, AI is not just optimizing processes but fundamentally redefining how organizations derive intelligence from their vast data assets. We’ll explore the core technological advancements, analyze their business impact, and offer a strategic outlook for businesses navigating this evolving domain.
- Platform Category: Active Metadata Management Platform, Data Catalog, Data Governance Platform
- Core Technology/Architecture: Machine Learning, Natural Language Processing (NLP), Knowledge Graphs, Generative AI
- Key Data Governance Feature: Automated Data Classification and PII Detection
- Primary AI/ML Integration: Automated Tagging/Classification, Natural Language Querying (NLQ), Anomaly Detection in Data Quality
- Main Competitors/Alternatives: Collibra, Alation, Atlan, Informatica, Google Cloud Dataplex
Introduction: The Dawn of Intelligent Data Governance with AI
In an era where data volumes escalate exponentially, the ability to efficiently find, understand, govern, and leverage information has become paramount. Traditional metadata management approaches, often manual and reactive, struggle to keep pace with the velocity and complexity of modern data environments. This is where AI Metadata Management Trends emerge as a game-changer. By integrating artificial intelligence and machine learning capabilities, organizations can transition from passive data catalogs to active, intelligent metadata platforms that not only describe data but also actively manage, enrich, and secure it. This article aims to explore the multifaceted impact of AI on metadata management, dissecting the underlying technologies, examining the benefits, and providing a forward-looking perspective on this indispensable evolution in data strategy.
Core Breakdown: Architecting Intelligence into Data Assets
The integration of AI into metadata management is rapidly redefining how organizations interact with their data assets. The evolution of AI Metadata Management Trends signifies a pivotal shift towards more intelligent, automated, and insightful approaches to data organization and utilization. This transformation is not merely about efficiency; it is about unlocking unprecedented value from the vast amounts of information businesses generate daily.
Enhanced Data Discovery and Cataloging
Enhanced Data Discovery and Cataloging capabilities are at the forefront of this revolution. AI algorithms excel at sifting through complex data landscapes to identify, categorize, and document metadata far beyond manual capacity. This not only accelerates the initial setup of data catalogs but also ensures their continuous relevance as data evolves. Through advanced pattern recognition and unsupervised learning, AI can discover relationships and attributes that would otherwise remain hidden, providing a much richer context for data users.
- Automated Tagging and Classification: Driven by machine learning, this ensures consistent and accurate labeling of data, making it effortlessly searchable and understandable. AI models can learn from existing tags and data patterns to automatically apply metadata tags, categorize data assets (e.g., customer data, financial reports, operational logs), and even detect sensitive information like PII (Personally Identifiable Information). This reduces human error, ensures compliance with data privacy regulations, and speeds up the cataloging process significantly. The precision and scale offered by AI in this area are unmatched by manual methods, ensuring that data is always classified correctly and consistently across the enterprise.
- Semantic Understanding for Richer Context: AI, particularly through Natural Language Processing (NLP) and knowledge graphs, can grasp the true meaning and relationships between data elements. This enriches metadata with deeper insights, allowing systems to understand not just what a piece of data is, but what it represents, how it relates to other data, and its business context. For instance, AI can identify that ‘customer_id’ in one system refers to the same entity as ‘client_identifier’ in another, bridging semantic gaps and facilitating more intuitive data exploration. This semantic layer empowers users to query data using natural language, making data accessible to a broader audience without requiring deep technical knowledge.
Predictive Analytics for Data Governance
Predictive Analytics for Data Governance represents another critical advancement. AI can anticipate potential data risks and compliance issues before they manifest, shifting governance from a reactive burden to a proactive, strategic advantage. By continuously monitoring data access patterns, usage behaviors, and policy adherence, AI platforms can identify deviations from expected norms that might signal a potential security threat or a breach of regulatory policy.
- Proactive Risk Identification: AI monitors data usage patterns and access permissions to flag anomalies that might indicate security vulnerabilities or policy breaches. Machine learning models analyze historical data access logs, user roles, and data sensitivity levels to establish baselines. Any deviation from these baselines, such as an unusual access pattern for a highly sensitive dataset or an unauthorized attempt to modify critical metadata, triggers an alert. This enables timely intervention, preventing potential data loss, unauthorized exposure, or non-compliance penalties.
- Policy Enforcement and Compliance Monitoring: AI makes policy enforcement and compliance monitoring more robust by continuously verifying adherence to regulatory requirements and internal governance policies. AI-driven systems can automatically scan data for compliance with regulations like GDPR, CCPA, HIPAA, or industry-specific standards. They can automate reporting and auditing functions, generating comprehensive compliance reports and demonstrating due diligence without extensive manual effort. This ensures that data remains compliant throughout its lifecycle, significantly reducing legal and reputational risks.
Streamlined Data Quality and Lineage Processes
Streamlined Data Quality and Lineage processes are also profoundly impacted by AI. Maintaining high-quality data and understanding its journey is crucial for reliable insights and trustworthy AI/ML models. AI provides the capability to continuously assess data quality and trace its origins with unprecedented accuracy and automation.
- AI-Powered Anomaly Detection: Automatically identifies inconsistencies, errors, and missing values within metadata, alerting users to potential data quality issues that need attention. Instead of relying on predefined rules that can miss subtle issues, AI models learn what “normal” data looks like and can spot outliers, corrupted entries, or illogical values. For example, it can detect a date field with an unrealistic future date or a customer record with an invalid email format. These proactive alerts enable data stewards to address issues before they propagate through downstream systems, ensuring the integrity of analytical outputs and operational processes.
- Automated Lineage Mapping: Tracks the complete lifecycle of data, from its origin to its transformation and consumption, providing an undeniable audit trail and improving transparency. AI algorithms can parse ETL scripts, database logs, and application code to automatically map how data flows through various systems, where it’s transformed, and by whom. This automated lineage is invaluable for impact analysis (e.g., understanding which reports are affected if a source column changes), root cause analysis of data errors, and regulatory compliance, offering a clear, visual representation of data’s journey without manual effort.
Intelligent Data Integration
Intelligent Data Integration is becoming a standard expectation with AI-driven solutions. Connecting disparate data sources is made easier and more adaptable, reducing the complexity and manual overhead traditionally associated with integration projects. AI can dynamically adjust to changes in source systems, making data pipelines more resilient and self-healing.
- Adaptive Schema Matching: Allows AI to intelligently map data fields between different systems, even with evolving schemas, reducing the manual effort in integration projects. Traditional schema matching is often a manual, tedious process. AI-powered tools leverage machine learning to suggest optimal mappings based on data patterns, names, and even semantic context, significantly accelerating data integration for new sources or when schemas change. This adaptability is crucial in agile environments where data structures frequently evolve.
- Self-Optimizing Data Pipelines: Utilize AI to continuously learn and adjust data flow for optimal performance, resource allocation, and reliability, minimizing bottlenecks. AI can monitor pipeline performance metrics such as latency, throughput, and error rates, and then dynamically reconfigure resources, adjust processing logic, or even reroute data to maintain optimal efficiency. This self-optimization capability ensures that data is delivered reliably and efficiently, even under varying loads and system conditions, reducing operational costs and improving data availability.
Democratizing Data Access and Understanding
Democratizing Data Access and Understanding is perhaps one of AI’s most impactful contributions to metadata management. It makes data accessible to a broader audience, breaking down technical barriers and fostering a data-driven culture across the organization. By simplifying how users interact with and comprehend data, AI enables more stakeholders to independently find and leverage insights.
- Natural Language Querying (NLQ): Empowers non-technical users to find and retrieve data using simple, conversational language, transforming how insights are gathered. Instead of writing complex SQL queries or navigating intricate dashboards, users can simply ask questions in plain English, such as “Show me sales figures for Q3 last year in Europe” or “What is the average customer lifetime value?”. AI-powered NLQ engines interpret these queries, translate them into actionable data requests, and present the results in an easy-to-understand format. This drastically lowers the barrier to entry for data exploration, enabling business users to gain insights without relying on data analysts.
- Personalized Metadata Views: Tailor the presentation of metadata to individual user roles and needs, ensuring relevance and reducing cognitive overload, fostering greater data literacy across the organization. An HR manager might see metadata related to employee data and payroll, while a marketing analyst would see campaign performance and customer demographics. AI can dynamically curate these views based on user permissions, past interactions, and stated preferences, making the data catalog more intuitive and less overwhelming. This personalized experience helps users quickly find the information most relevant to their tasks, enhancing productivity and promoting a deeper understanding of available data assets.
Challenges and Barriers to Adoption
Despite the immense potential of AI Metadata Management Trends, several challenges and barriers hinder widespread adoption. Organizations often grapple with the complexity of integrating AI into existing legacy systems, a process that can be resource-intensive and require significant architectural overhaul.
- Data Quality and Volume for AI Training: AI models thrive on high-quality, relevant data. However, many organizations struggle with inconsistent data quality, siloed data sources, and insufficient volumes of labeled metadata to effectively train sophisticated AI models for tasks like automated classification or anomaly detection. Poor training data can lead to biased or inaccurate AI outputs, undermining trust in the metadata system.
- Skills Gap and Organizational Change: Implementing and managing AI-powered metadata platforms requires specialized skills in areas like machine learning engineering, data science, and AI governance. A shortage of these skilled professionals, coupled with organizational resistance to change and a lack of understanding regarding AI’s capabilities, can impede successful adoption. Shifting from manual processes to AI-driven automation often requires significant cultural adjustments.
- Ethical AI and Bias Concerns: As AI takes on more responsibility in data governance, concerns around algorithmic bias, fairness, and transparency become critical. If AI models are trained on biased data or designed with inherent biases, they could inadvertently perpetuate discriminatory practices in data access, classification, or privacy detection. Ensuring ethical AI implementation and maintaining explainability of AI decisions in metadata management is a complex but essential challenge.
- Complexity of Integration and Scalability: Integrating AI metadata platforms with a diverse ecosystem of existing data sources, applications, and tools (e.g., ETL tools, BI platforms, data warehouses) can be highly complex. Ensuring the AI system can scale to handle ever-increasing data volumes and evolving architectural landscapes without performance degradation is another significant technical hurdle.
Business Value and ROI of AI Metadata Management
The investment in AI Metadata Management Trends yields substantial business value and a compelling return on investment (ROI) by transforming how organizations perceive and utilize their data. The benefits extend beyond mere efficiency gains, touching upon strategic advantages and risk mitigation.
- Accelerated Data Discovery and Time-to-Insight: By automating data discovery, classification, and semantic enrichment, AI significantly reduces the time it takes for data consumers to find, understand, and use relevant data. This acceleration translates directly into faster report generation, quicker development of new analytical models, and ultimately, more rapid decision-making, which is a critical competitive advantage.
- Improved Data Quality and Trust: AI’s ability to proactively detect anomalies and automate data lineage provides a continuous quality assurance mechanism for metadata and underlying data. Higher data quality leads to more reliable analytical insights, reducing the risk of flawed business decisions and fostering greater trust in the organization’s data assets across all stakeholders.
- Enhanced Data Governance and Compliance: AI streamlines compliance efforts by automating PII detection, policy enforcement, and audit trail generation. This not only reduces the manual burden on compliance teams but also significantly lowers the risk of regulatory fines and reputational damage associated with data breaches or non-compliance. The proactive identification of risks leads to a more robust and resilient data governance framework.
- Cost Reduction and Operational Efficiency: Automating manual tasks like data tagging, schema mapping, and lineage tracking frees up valuable data professionals to focus on higher-value strategic initiatives. Furthermore, self-optimizing data pipelines reduce operational overheads and resource consumption, leading to tangible cost savings in data operations and management.
- Democratization of Data and Innovation: Natural Language Querying and personalized metadata views empower a broader range of business users to interact directly with data, fostering a data-driven culture. This democratization sparks innovation by enabling new analytical perspectives and reducing the bottleneck on data teams, allowing more employees to contribute to data-driven strategies and discover new business opportunities.
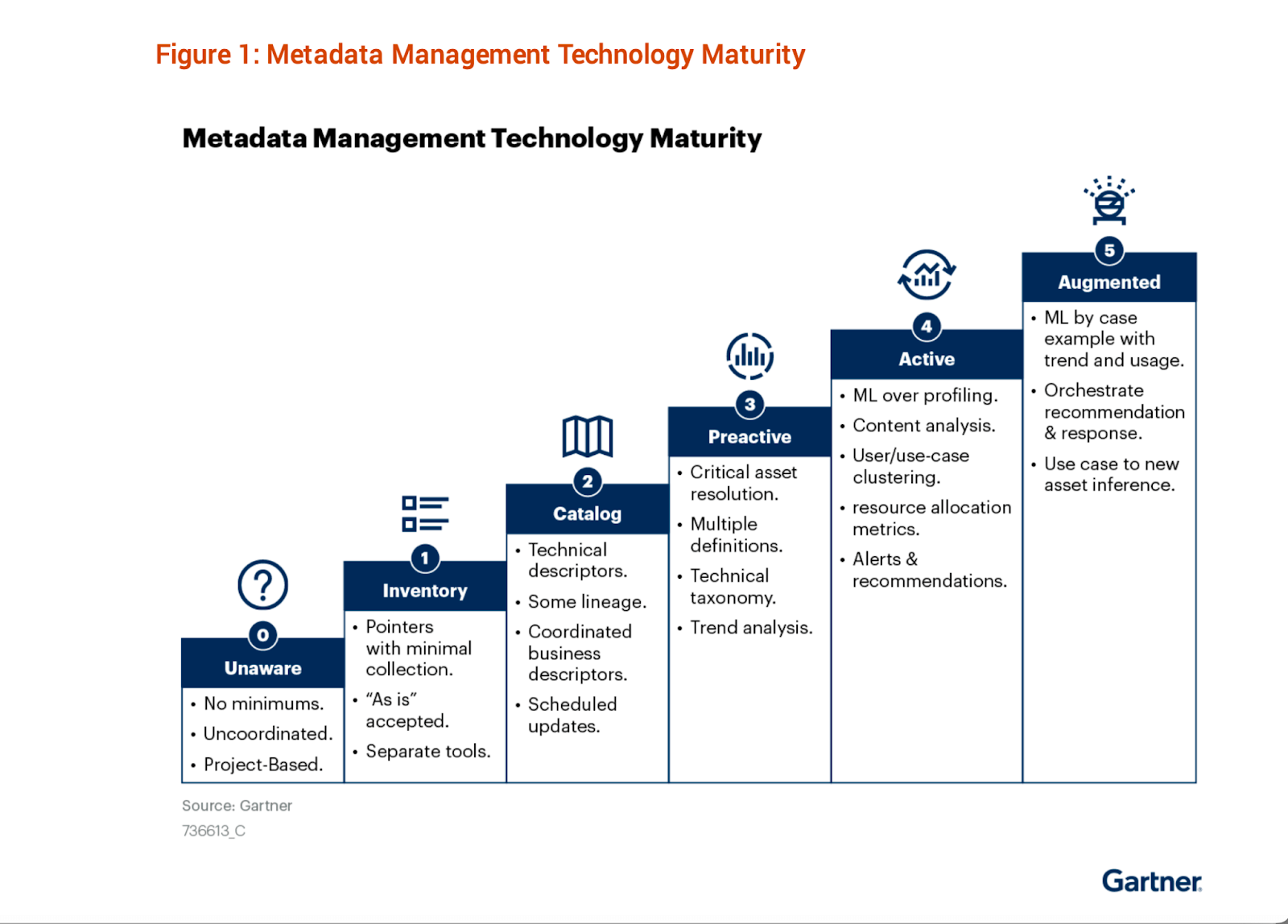
Comparative Insight: AI-Powered vs. Traditional Metadata Management
The advent of AI Metadata Management Trends marks a clear divergence from traditional metadata management paradigms, much like how modern data lakes evolved from simple file storage. Understanding this comparative insight is crucial for organizations planning their data strategy.
Traditional Metadata Management: Reactive and Manual
Traditional metadata management systems, often epitomized by static data catalogs or homegrown spreadsheets, are characterized by their reactive nature and heavy reliance on manual processes. These systems typically require data stewards to manually input, update, and categorize metadata. While they provide a foundational inventory of data assets, their limitations become glaringly apparent in today’s dynamic data environments:
- Static and Outdated: Manual updates mean metadata often lags behind changes in data sources, leading to stale and inaccurate information.
- Limited Discovery: Discovery capabilities are usually keyword-based, making it difficult to find data without knowing exactly what to search for. Semantic relationships are rarely captured.
- Governance Burden: Policy enforcement and compliance monitoring are manual, prone to human error, and time-consuming, making it challenging to scale across diverse regulatory landscapes.
- Siloed Information: Metadata often resides in disparate tools, making a unified, holistic view of data assets difficult to achieve.
- Low Adoption: The complexity and lack of intuitive interfaces often lead to low adoption rates among business users, limiting data democratization.
AI-Powered Metadata Management: Proactive and Autonomous
In stark contrast, AI-powered metadata management platforms are designed to be proactive, dynamic, and largely autonomous. They leverage machine learning, NLP, and knowledge graphs to create an “active” metadata layer that continuously observes, analyzes, and enriches data assets.
- Dynamic and Real-time: AI continuously monitors data sources for changes, automatically updating metadata and detecting new data assets, ensuring metadata is always current and relevant.
- Intelligent Discovery: Beyond keyword searches, AI enables semantic search, natural language querying, and contextual recommendations, allowing users to discover data based on its meaning and relevance to their specific tasks.
- Automated Governance: AI automates data classification (including PII detection), monitors policy adherence, and proactively identifies data quality issues and security risks, transforming governance into an agile and efficient process.
- Unified and Contextual: AI can infer relationships across disparate data sources, building a comprehensive knowledge graph that provides a unified, semantic view of all data assets, complete with rich business context.
- Democratized Access: Intuitive interfaces, natural language querying, and personalized views empower a wide range of users, from technical data engineers to non-technical business analysts, to interact with data confidently.
While traditional methods offer a basic inventory, AI-powered metadata management solutions provide an intelligent, self-adapting fabric that weaves together disparate data sources, making data truly discoverable, governable, and valuable for driving strategic business outcomes. They transform metadata from a static description to an active engine for data intelligence.
World2Data Verdict: The Imperative of Active Metadata for Future-Proofing Data Strategy
The trajectory of data management is undeniably moving towards greater automation and intelligence, with AI Metadata Management Trends serving as the central nervous system of future-proof data strategies. Organizations that merely catalog data manually will find themselves increasingly disadvantaged, struggling with data sprawl, compliance complexities, and slow time-to-insight.
World2Data.com asserts that embracing an active, AI-powered metadata management platform is no longer a luxury but an imperative for any enterprise aiming for true data mastery. Our recommendation is clear: organizations must strategically invest in solutions that leverage machine learning, NLP, and knowledge graphs to automate metadata discovery, enhance semantic understanding, and establish continuous data governance. Prioritize platforms that offer robust capabilities for automated data classification, natural language querying, and proactive anomaly detection to truly unlock the full potential of your data assets. Looking ahead, the integration of generative AI will further revolutionize how we interact with metadata, potentially allowing for on-demand metadata generation and even more intuitive data exploration, solidifying AI’s role at the core of intelligent data ecosystems.

{kind=link}