


AI Data Mesh: The New Era of Distributed Architecture for Modern AI
- Platform Category: Data Architecture Paradigm
- Core Technology/Architecture: Decentralized, Domain-Oriented Architecture
- Key Data Governance Feature: Federated Computational Governance
- Primary AI/ML Integration: Decentralized AI/ML model development and deployment within domains
- Main Competitors/Alternatives: Centralized Data Warehouse, Centralized Data Lake, Data Fabric
The landscape of data management is undergoing a profound transformation, driven by the escalating demands of artificial intelligence and machine learning. In this dynamic environment, the AI Data Mesh Architecture is emerging as a critical paradigm, fundamentally reshaping how organizations manage and leverage their vast data assets. Moving beyond the limitations of monolithic, centralized systems, this innovative approach champions a decentralized, domain-oriented framework that promises unprecedented agility, scalability, and enhanced data quality, especially for advanced analytics and AI initiatives. This article delves into the core tenets, benefits, challenges, and the strategic implications of adopting an AI Data Mesh Architecture.
Introduction: Reimagining Data Foundations for the AI Era
In an age where data is the new oil, and artificial intelligence the refinery, the efficiency and quality of data pipelines are paramount. Traditional data architectures, such as centralized data lakes and data warehouses, while foundational in their time, increasingly struggle to keep pace with the velocity, volume, and variety of data required by modern AI applications. These systems often lead to bottlenecks, data silos, and a lack of clear data ownership, hindering rapid experimentation and deployment of AI models. The AI Data Mesh Architecture offers a compelling alternative, proposing a paradigm shift that decentralizes data ownership and empowers individual business domains to treat data as a product.
The objective of this deep dive is to explore the intricacies of the AI Data Mesh Architecture, elucidating its core components, the value it delivers to AI and ML initiatives, and how it addresses long-standing challenges in data management. We will also compare its merits against traditional models and conclude with World2Data.com’s strategic verdict on its future trajectory and adoption.
Core Breakdown: Dissecting the AI Data Mesh Architecture
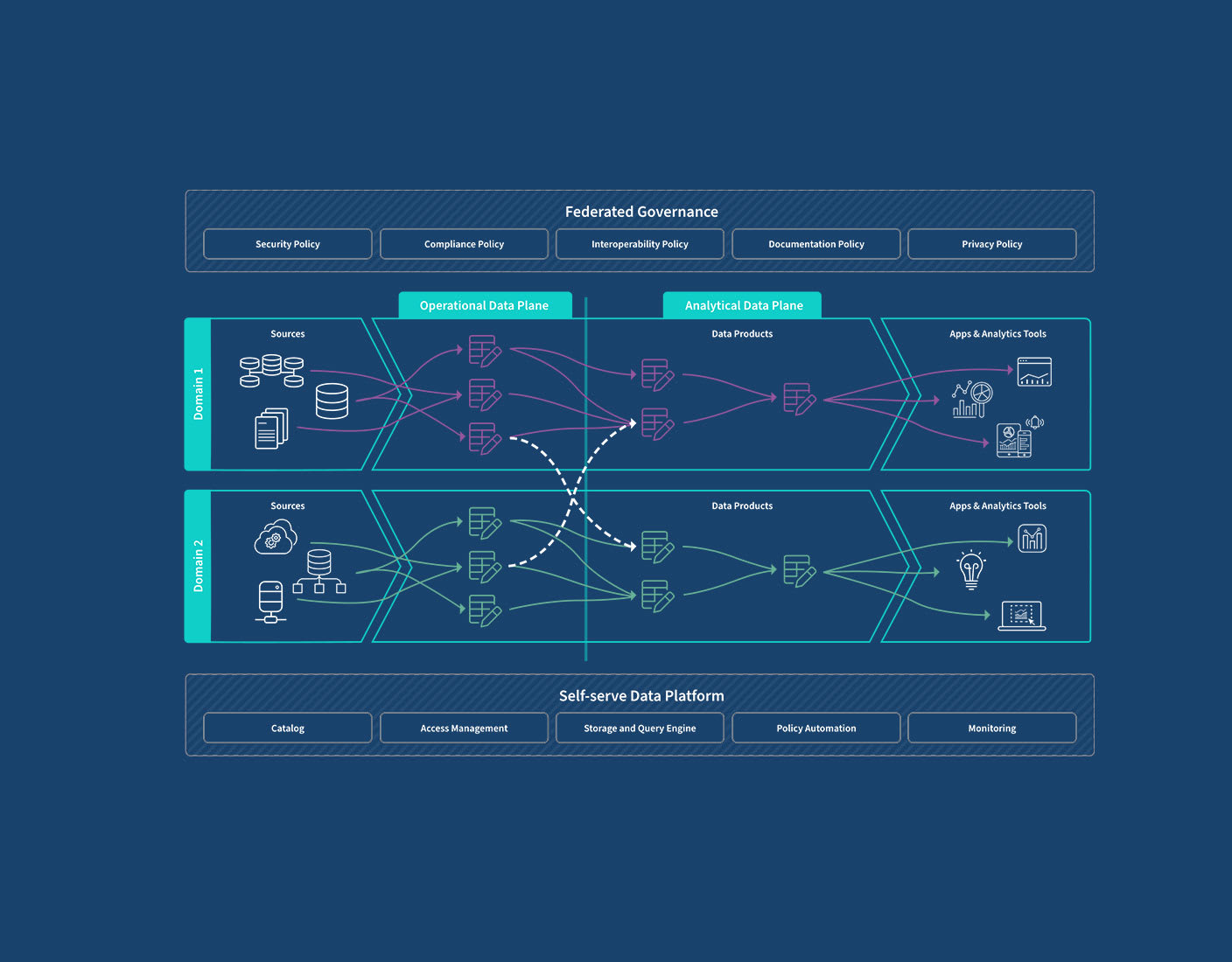
At its heart, the AI Data Mesh Architecture is built upon four foundational principles that redefine data management and ownership, making it particularly potent for AI and machine learning workloads.
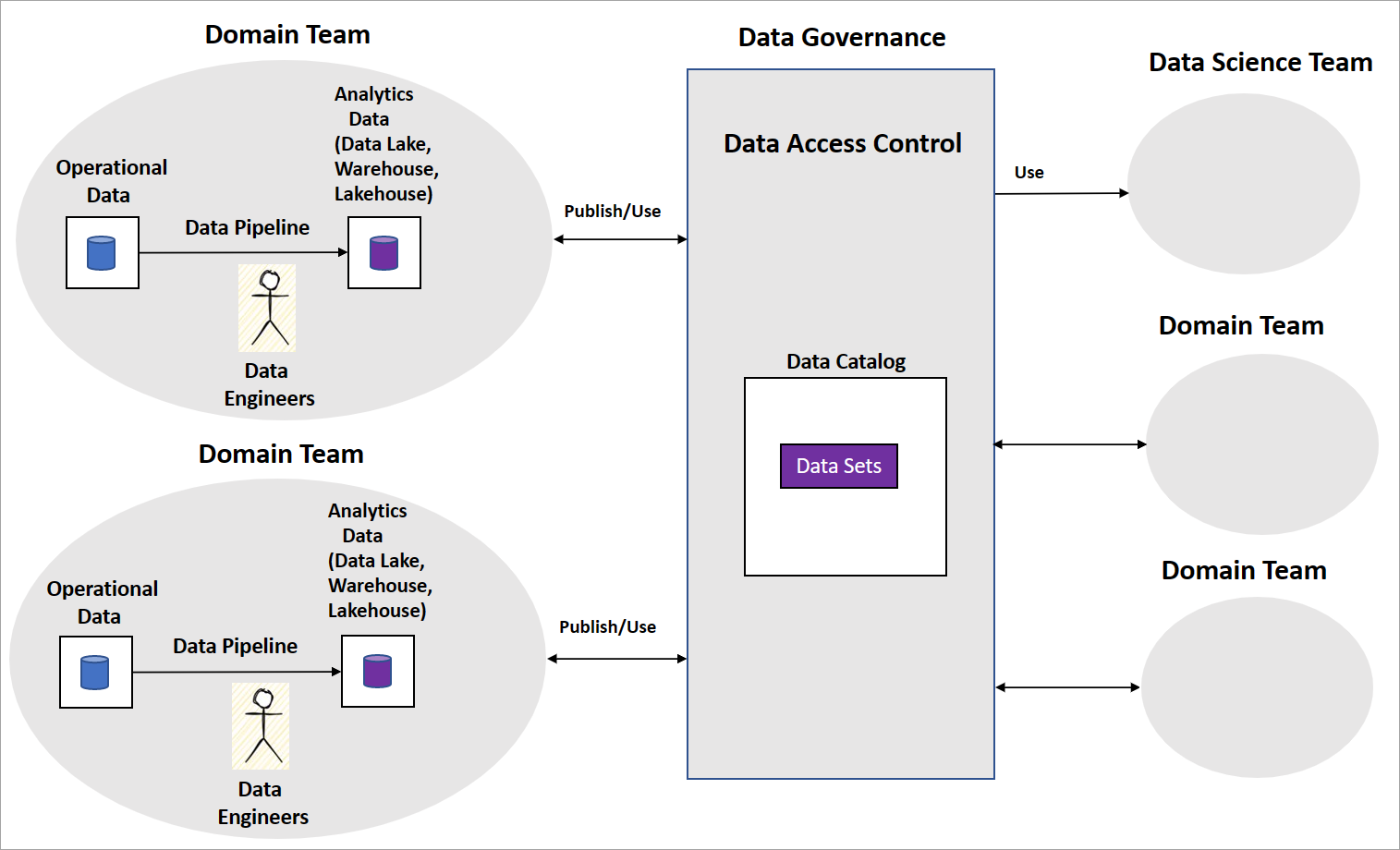
1. Domain-Oriented Data Ownership
This principle dictates that ownership and responsibility for data lie with the business domains that generate or consume it. Instead of a central IT team being responsible for all data, marketing owns marketing data, sales owns sales data, and so on. This shift fosters a deeper understanding of data context, improved data quality, and greater accountability. For AI, this means data scientists and machine learning engineers can access data directly from experts who understand its nuances, leading to more accurate models and fewer misinterpretations.
2. Data as a Product
Within an AI Data Mesh Architecture, raw data is transformed into “data products.” These are curated, reliable, discoverable, addressable, trustworthy, secure, and interoperable datasets offered by domains to other domains or external consumers. Each data product is designed with a clear purpose and an explicit interface (API or standard schema), much like a software product. This ensures data consumers (including AI algorithms) receive high-quality, well-documented, and readily consumable data, significantly reducing the “data wrangling” time that often plagues AI projects.
- Discoverability: Data products are registered in a centralized catalog, making them easy to find.
- Addressability: Each data product has a unique identifier and clear access mechanism.
- Trustworthiness: Quality metrics, lineage, and ownership are transparently associated with the data product.
- Security & Governance: Access controls and compliance are baked into each data product.
- Interoperability: Standardized formats and interfaces allow seamless integration across domains and AI tools.
3. Self-Serve Data Platform
To enable domain teams to build, deploy, and manage their data products autonomously, an AI Data Mesh Architecture relies on a self-serve data platform. This platform provides the necessary tools, infrastructure, and capabilities for domains to operate independently without constant reliance on central data engineering teams. It abstracts away underlying technological complexities, offering templates, automation, and a rich ecosystem for data storage, processing, transformation, and serving. This autonomy accelerates the development cycle for data products and, by extension, the AI models that consume them.
4. Federated Computational Governance
While decentralization is key, anarchy is not an option. Federated computational governance establishes a framework of global rules and policies that all domains must adhere to, ensuring consistency, compliance, security, and ethical use of data across the entire organization. This governance model is “computational” because many policies are enforced programmatically, rather than solely through manual processes. It strikes a crucial balance between domain autonomy and enterprise-wide standards, vital for maintaining data integrity and regulatory compliance, particularly for sensitive AI applications.
Challenges and Barriers to Adoption
Despite its compelling advantages, implementing an AI Data Mesh Architecture is not without its hurdles. Organizations must be prepared to address several significant challenges:
- Cultural and Organizational Shift: The move from centralized ownership to domain-oriented accountability requires a fundamental change in mindset, roles, and responsibilities. This is often the biggest barrier.
- Complexity of Decentralized Governance: Establishing and maintaining federated governance requires sophisticated tooling and a robust framework to balance autonomy with global standards, data privacy, and security.
- Initial Investment and Tooling Landscape: Building a comprehensive self-serve data platform and integrating disparate domain-specific technologies can be a substantial upfront investment in time and resources.
- Data Product Definition and Standardization: Defining what constitutes a “data product” and ensuring consistent quality and interoperability across numerous domains can be challenging without strong leadership and clear guidelines.
- Skill Gap: Organizations may lack the necessary talent in data product management, distributed systems, and federated governance to effectively implement and operate an AI Data Mesh Architecture.
Business Value and ROI of AI Data Mesh
For organizations committed to becoming data-driven and AI-first, the return on investment from an AI Data Mesh Architecture can be substantial:
- Accelerated AI/ML Development and Deployment: By providing high-quality, discoverable data products, data scientists spend less time on data preparation and more time on model building, leading to faster time-to-market for AI solutions.
- Improved Data Quality and Trust: Domain ownership directly incentivizes data quality, as teams are responsible for the products they offer, resulting in more reliable data for AI models and better decision-making.
- Enhanced Agility and Scalability: The decentralized nature allows individual domains to innovate and scale independently, without bottlenecking the entire organization. This is crucial for rapidly evolving AI initiatives.
- Reduced Central IT Bottlenecks: Self-serve capabilities empower domain teams, freeing central data teams to focus on platform development and strategic initiatives rather than bespoke data requests.
- Better Business Domain Alignment & Innovation: Data products are designed with direct business needs in mind, leading to more relevant data for domain-specific AI applications and fostering innovation from the edge.
- Compliance and Risk Mitigation: Federated computational governance embeds compliance and security from the outset, reducing risks associated with data privacy (e.g., GDPR, CCPA) across distributed AI applications.
Comparative Insight: AI Data Mesh vs. Traditional Data Architectures
To fully appreciate the innovation of the AI Data Mesh Architecture, it’s essential to compare it with the traditional data lake and data warehouse models that have long dominated the enterprise data landscape.
Traditional Data Warehouse
Data warehouses are centralized repositories of structured, cleaned, and transformed data, optimized for reporting and business intelligence. They enforce a strict schema-on-write approach. While excellent for historical analysis and predefined queries, they struggle with semi-structured or unstructured data, the agility required by AI/ML workloads, and the sheer volume and velocity of modern data. Data often resides in silos, managed by a central team, creating bottlenecks for domain-specific AI projects.
Traditional Data Lake
Data lakes emerged to address the limitations of data warehouses, offering a centralized storage solution for vast amounts of raw, multi-structured data at a low cost. They employ a schema-on-read approach, providing flexibility. However, without strong governance, data lakes can quickly devolve into “data swamps,” where data quality is low, discoverability is poor, and data is difficult to use effectively for AI without significant cleaning and processing by central teams. They still represent a centralized bottleneck and often fail to empower domain experts.
The AI Data Mesh Difference
The AI Data Mesh Architecture fundamentally differs by decentralizing ownership and shifting from a centralized technical platform to a federated ecosystem of data products. Here’s a comparative overview:
- Ownership & Responsibility:
- Traditional: Centralized IT/data teams own and manage all data.
- Data Mesh: Business domains own and are responsible for their data products, directly impacting the quality of data for AI.
- Data Consumption for AI:
- Traditional: Data often requires extensive extraction, transformation, and loading (ETL/ELT) by central teams before it’s usable for AI, leading to delays.
- Data Mesh: Data is consumed as pre-curated, self-describing data products via standardized interfaces, significantly accelerating AI model development and deployment.
- Scalability & Agility:
- Traditional: Centralized architectures can become bottlenecks, limiting overall scalability and slowing down agile AI initiatives.
- Data Mesh: Decentralized domains can scale independently and innovate faster, supporting parallel AI development efforts across the organization.
- Governance:
- Traditional: Centralized governance, often manual and slow, struggles with enforcing policies across diverse data types and uses.
- Data Mesh: Federated computational governance enforces global standards automatically while allowing domain autonomy, ensuring compliance for distributed AI models.
- Data Quality:
- Traditional: Data quality is often an afterthought or a challenge for central teams across vast, disparate datasets.
- Data Mesh: Domain ownership directly ties data quality to business accountability, yielding more trustworthy data for critical AI applications.
In essence, while traditional architectures focus on centralizing data storage, the AI Data Mesh Architecture focuses on decentralizing data ownership and empowering domains to serve data as products, making it a natural fit for the dynamic and distributed needs of modern AI.
World2Data Verdict: The Imperative for an AI Data Mesh Architecture
The advent of sophisticated AI and machine learning models has irrevocably changed the demands placed on enterprise data architectures. World2Data.com asserts that the AI Data Mesh Architecture is not merely an evolutionary step but a strategic imperative for organizations aiming to unlock the full potential of their data assets for AI innovation. Traditional centralized models are increasingly showing their age, characterized by bottlenecks, data quality issues, and a lack of agility that directly impedes the speed and effectiveness of AI development.
For enterprises committed to being data-driven and AI-first, adopting an AI Data Mesh Architecture offers a clear pathway to achieving superior data quality, accelerating AI model deployment, and fostering true business agility. While the journey involves significant organizational and cultural shifts, the long-term benefits of empowering domain teams, creating high-quality data products, and establishing robust federated governance far outweigh the initial challenges. World2Data.com recommends that organizations strategically assess their current data architecture against their AI ambitions. For those struggling with data silos, slow AI development cycles, or inadequate data quality for ML, investing in the principles and implementation of an AI Data Mesh Architecture will be a defining factor in their competitive success in the coming decade. It represents the future of scalable, sustainable, and truly intelligent data management.

{kind=link}