


Revolutionizing Data Operations: The Power of AI in Data Pipeline Management
Platform Category: Data Orchestration and Observability
Core Technology/Architecture: Machine Learning for Anomaly Detection and Predictive Optimization
Key Data Governance Feature: Automated Schema Drift Detection and Data Quality Monitoring
Primary AI/ML Integration: Autonomous Root Cause Analysis and Predictive Failure Alerting
Main Competitors/Alternatives: Informatica (CLAIRE), IBM (DataStage), Databricks, Ascend.io, Monte Carlo
AI in Data Pipeline Management is no longer a futuristic concept but a vital necessity for organizations navigating the complexities of modern data landscapes. As data volumes explode and velocity increases, traditional manual approaches to pipeline management struggle to keep pace, leading to bottlenecks, errors, and significant operational overhead. This is where advanced AI Data Pipeline Management solutions step in, transforming how businesses handle their most critical asset, ensuring data integrity, efficiency, and real-time responsiveness for all downstream analytical and machine learning initiatives.
Introduction: The Imperative of Intelligent Data Flow
The digital age has ushered in an era of unprecedented data generation, making robust and efficient data pipelines the backbone of any data-driven enterprise. However, the sheer scale, variety, and velocity of modern data streams often overwhelm traditional, rule-based data management systems. Manual monitoring, troubleshooting, and optimization of complex data pipelines are not only resource-intensive but also prone to human error, leading to data quality issues, delayed insights, and costly operational failures. This article delves into how artificial intelligence is fundamentally reshaping data pipeline management, offering a comprehensive analysis of its components, benefits, challenges, and its transformative impact on data ecosystems. Our objective is to illustrate why integrating AI into data pipelines, giving rise to sophisticated AI Data Pipeline Management systems, is no longer an option but a strategic imperative for maintaining competitive advantage and unlocking the full potential of enterprise data.
Core Breakdown: Dissecting AI-Driven Data Pipeline Management
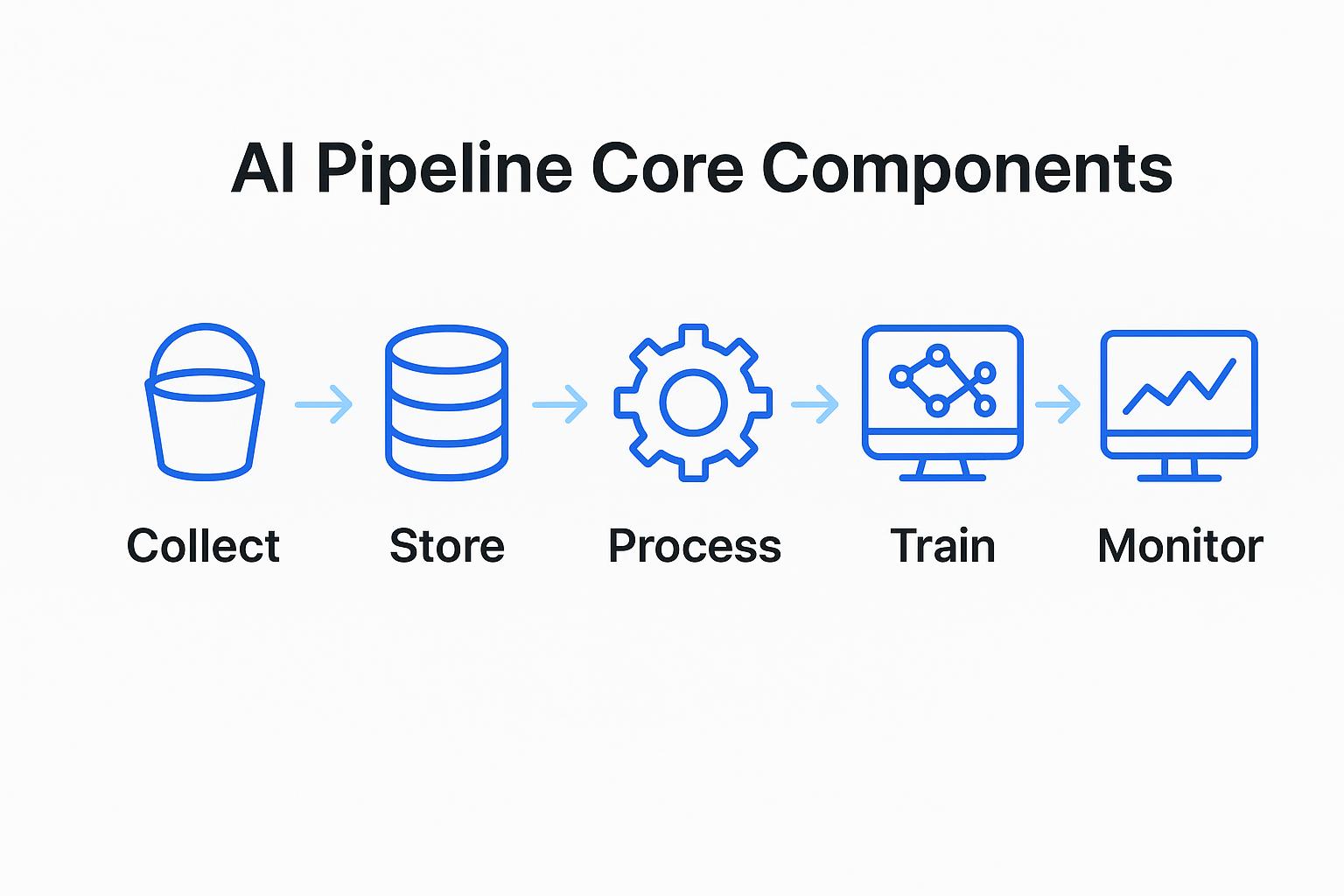
The integration of AI into data pipeline management transcends simple automation; it introduces intelligence, adaptability, and predictive capabilities across the entire data lifecycle. These advanced platforms leverage machine learning algorithms to learn from historical data, anticipate issues, and proactively optimize data flows, fundamentally altering how data is ingested, transformed, validated, and delivered.
The Evolution of Data Pipelines with AI Integration
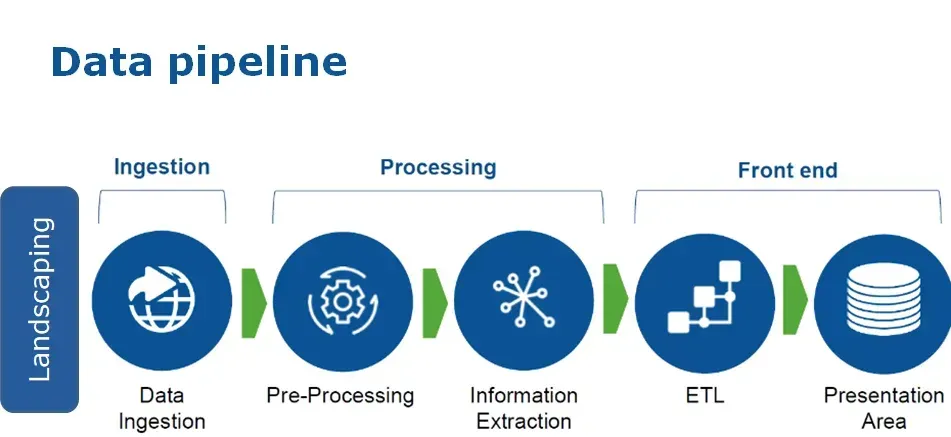
AI is fundamentally changing how data flows from source to destination. Automating mundane tasks such as data ingestion, transformation, and validation drastically reduces human effort. This integration ensures enhanced efficiency and speed across the entire data lifecycle. Beyond mere automation, AI-driven pipelines can dynamically adapt to schema changes, data volume fluctuations, and even data source availability, making them significantly more resilient and scalable than their static predecessors. For instance, intelligent data connectors can automatically detect new data formats or fields and suggest appropriate transformation rules, vastly accelerating the onboarding of new data sources.
Optimizing Performance Through Predictive Analytics
Leveraging machine learning, AI-powered systems can conduct proactive issue identification before they impact operations. They analyze patterns to predict potential failures or performance degradations. This capability also enables smart resource allocation and cost savings by optimizing infrastructure usage based on anticipated demands. Predictive analytics allows systems to anticipate bottlenecks, forecast resource requirements, and even suggest preventative maintenance, thereby minimizing downtime and ensuring continuous data availability. This proactive stance contrasts sharply with traditional reactive monitoring, where issues are only addressed after they have already impacted operations.
Improving Data Quality and Reliability
A critical aspect of effective data management is ensuring data accuracy. AI Data Pipeline Management tools offer automated error detection mechanisms, identifying anomalies and inconsistencies in real-time. This active monitoring is crucial for ensuring data integrity and trustworthiness across all systems. AI algorithms can identify subtle data drift, detect outliers that signify corrupted data, or even flag discrepancies across multiple related datasets. The continuous, intelligent validation dramatically improves the reliability of data fed into business intelligence tools, analytical models, and, crucially, machine learning systems, where data quality directly impacts model performance and trustworthiness.
Scalability and Adaptability with AI
The dynamic nature of data demands systems that can grow and change. AI algorithms facilitate handling increasing data volumes effortlessly without compromising performance. They also enable dynamic adjustments to workloads, scaling resources up or down as needed to meet fluctuating demands efficiently. This elastic scalability is vital for modern cloud-native architectures, allowing organizations to pay only for the resources they consume while maintaining optimal performance even during peak loads.
Integral Components Enhanced by AI in Data Pipelines
- Automated Data Ingestion and Transformation: AI can infer schemas, cleanse data, and suggest transformation rules automatically, reducing manual effort in ETL/ELT processes. This accelerates time-to-insight for new data sources.
- Feature Store Integration: While not a direct component of the pipeline itself, AI Data Pipeline Management ensures that the data fed into a feature store is clean, consistent, and ready for use. AI can monitor the quality of features being generated and detect feature drift, ensuring model stability. Pipelines can intelligently pre-process raw data into high-quality features, which are then stored for reuse across multiple ML models.
- Data Labeling Support and Quality Control: For data destined for machine learning, AI-driven pipelines can pre-process data to make labeling more efficient, and post-process labeled data to detect inconsistencies or errors in annotations, significantly improving the quality of training datasets. This can include automated identification of potentially mislabeled instances for human review.
- Data Observability and Monitoring: AI provides intelligent monitoring capabilities, moving beyond simple threshold alerts to predictive anomaly detection, root cause analysis, and impact assessment. It learns normal operational patterns to identify deviations that might indicate impending issues.
- Automated Schema Drift Detection: As a key data governance feature, AI-powered systems continuously monitor incoming data against expected schemas. Upon detecting discrepancies or changes (schema drift), they can automatically alert administrators, suggest schema updates, or even adapt data ingestion processes to prevent pipeline failures. This proactive management maintains data integrity and compatibility across diverse systems.
Challenges and Barriers to Adoption
Despite the immense benefits, implementing robust AI Data Pipeline Management solutions comes with its own set of hurdles:
- Data Drift and Concept Drift: While AI helps detect drift, managing its impact and adapting models/pipelines to continuously evolving data distributions remains a significant challenge. This requires continuous monitoring and retraining strategies.
- MLOps Complexity: Integrating AI into data pipelines inherently links to the broader MLOps lifecycle. Managing the deployment, monitoring, and retraining of ML models that power the pipeline (e.g., for anomaly detection or predictive optimization) adds a layer of operational complexity.
- Skill Gap: Organizations often lack the specialized talent required to implement, manage, and optimize AI-driven data pipelines, demanding expertise in both data engineering and machine learning.
- Initial Investment and Integration: The upfront cost of sophisticated AI tools and the effort required to integrate them with existing legacy systems can be substantial.
- Trust and Explainability: For critical data operations, there’s a need for transparency and explainability in AI’s decisions, especially when it automates complex tasks or flags potential issues. Building trust in these autonomous systems is paramount.
Business Value and ROI of AI Data Pipeline Management
The strategic deployment of AI Data Pipeline Management yields substantial returns:
- Faster Model Deployment and Iteration: By ensuring high-quality, reliable, and continuously available data, AI-driven pipelines significantly accelerate the development, training, and deployment cycles of machine learning models. This translates to faster time-to-market for AI-powered products and services.
- Enhanced Data Quality for AI: Consistent, clean, and validated data is the lifeblood of effective AI. AI-managed pipelines drastically reduce errors and inconsistencies, ensuring that AI models are trained on reliable data, leading to more accurate predictions and better business outcomes.
- Reduced Operational Costs: Automation of monitoring, troubleshooting, and optimization tasks minimizes manual intervention, reducing operational expenses and freeing up skilled personnel for more strategic initiatives.
- Improved Data Governance and Compliance: Automated schema drift detection, data quality monitoring, and intelligent auditing capabilities enhance data governance, helping organizations meet regulatory compliance requirements more effectively.
- Real-time Business Insights: By ensuring the continuous flow of high-quality data, organizations can leverage real-time analytics and predictive capabilities to make faster, more informed business decisions, gaining a significant competitive edge.
Comparative Insight: AI-Driven vs. Traditional Data Pipelines
The distinction between traditional data pipelines and those enhanced by AI is profound, representing a paradigm shift from reactive, manual management to proactive, intelligent autonomy. Traditional data lakes and data warehouses, while foundational for storing vast amounts of structured and unstructured data, primarily rely on human-defined rules and scheduled processes for data movement and transformation. Their pipelines are often rigid, requiring significant manual intervention for modifications, error handling, and performance tuning.
In contrast, AI Data Pipeline Management systems introduce a layer of intelligence that transcends these limitations. Where a traditional pipeline might fail due to unexpected data format changes or an unmonitored data source outage, an AI-driven pipeline can detect schema drift automatically, predict potential failures before they occur, and even suggest or implement corrective actions. Traditional systems require dedicated teams to monitor logs, write custom scripts for anomaly detection, and manually scale resources. AI-powered pipelines, through machine learning for anomaly detection and predictive optimization, autonomously handle these tasks, learning from historical data to continuously improve performance, reliability, and cost-efficiency.
For large-scale machine learning and advanced analytics workloads, the limitations of traditional pipelines become glaring. They struggle to provide the consistent, high-quality, and real-time data streams necessary for MLOps. AI-driven pipelines, however, are specifically designed to meet these demands, ensuring that features are continuously updated, data quality is maintained for model training, and data drift is mitigated. They transform a static data highway into an intelligent, self-optimizing network, capable of supporting the most demanding data-intensive applications and fostering a truly data-driven culture.
World2Data Verdict: Embracing the Autonomous Data Future
The widespread adoption of AI in data pipeline management is paving the way for smarter decision making at every level of an organization. This continuous operational improvement ensures data ecosystems remain robust, responsive, and ready for future challenges. Embracing these intelligent solutions allows companies to unlock new levels of insight and agility, truly leveraging their data for strategic advantage. World2Data.com asserts that for any organization serious about data-driven innovation and operational excellence, investing in robust AI Data Pipeline Management is not merely an enhancement but a foundational requirement. The future of data lies in autonomous, self-optimizing, and intelligently managed pipelines that proactively ensure data integrity, streamline operations, and accelerate the path from raw data to actionable intelligence. Organizations must prioritize building capabilities in this area, leveraging specialized platforms and nurturing a culture that values intelligent automation to stay ahead in the increasingly complex data landscape.

{kind=link}