


Metadata Layer: The Foundation of Data Discovery: Powering the Analytics Layer
In today’s hyper-connected, data-driven world, the ability to rapidly discover, understand, and leverage data assets is not merely an advantage—it’s a fundamental necessity. The Metadata Layer stands as the invisible yet indispensable backbone of any effective data ecosystem, acting as the critical interpreter and guide. Without a robust metadata layer, the effectiveness of any Analytics Layer is severely hampered, as data assets remain undiscoverable, untrustworthy, and ultimately, underutilized.
Introduction: Unlocking Data’s Potential Through Context
The quest for data-driven insights often begins not with complex algorithms, but with a simple question: “Where is the data I need, and what does it mean?” Answering this question efficiently and accurately is the primary mission of a well-architected Metadata Layer. This foundational component transcends mere data descriptions; it encapsulates the complete lifecycle and context of every data asset, from its origin and transformations to its quality, ownership, and usage patterns. By providing this rich context, the metadata layer transforms raw, disparate datasets into discoverable, intelligible, and actionable resources, thereby directly accelerating the efficacy and reliability of the overlying Analytics Layer.
Our objective in this article is to conduct a deep dive into the technical and strategic significance of the metadata layer. We will explore its core components, its critical role in data governance and AI/ML integration, the challenges associated with its implementation, and its undeniable business value. Furthermore, we will compare its impact in modern data architectures against traditional paradigms, culminating in a World2Data verdict on its future trajectory and importance.
Core Breakdown: Architecture, Governance, and AI/ML Integration
The metadata layer is a sophisticated system designed to manage and make accessible information about an organization’s data assets. It’s not a single tool but rather a collection of technologies and processes that work in concert to provide a comprehensive view of data context. This foundational component serves as a critical enabler for a wide array of data management and analytical platforms.
Platform Categories Empowered by Metadata
A robust metadata layer is the foundational component for several critical data platforms, including:
- Data Catalogs: These tools (e.g., Collibra, Alation, Atlan) rely entirely on metadata to provide a searchable inventory of an organization’s data assets, making data discovery intuitive and efficient.
- Data Governance Platforms: Metadata provides the necessary context for enforcing policies, tracking data ownership, and managing access controls.
- Data Observability Platforms: By detailing data lineage, quality metrics, and usage patterns, metadata enables proactive identification and resolution of data issues.
- Data Lineage Tools: These specialized platforms trace the journey of data from source to consumption, a function entirely dependent on comprehensive metadata capture.
Core Technology and Architecture
At its heart, a metadata layer consists of a repository that stores metadata. This repository can be:
- Centralized or Distributed: Depending on the organizational structure and scale, metadata can be stored in a single repository or distributed across various domains, especially in data mesh architectures where it provides domain-specific metadata views.
- Graph Databases or Semantic Layers: Many modern metadata solutions leverage graph databases to represent complex relationships between data assets, enhancing lineage tracking and impact analysis. Semantic layers further enrich this by providing business-friendly definitions.
- API-Driven: Effective metadata layers are highly interoperable, utilizing APIs for seamless metadata extraction from various sources (databases, data lakes, applications) and ingestion into the central repository. This ensures real-time updates and broad applicability.
- Support for Data Mesh Architectures: In a data mesh, the metadata layer is crucial for linking disparate data products, enabling cross-domain discovery, and maintaining a consistent understanding of data across decentralized teams.
Key Data Governance Features
The metadata layer is not just about discovery; it’s the bedrock of effective data governance:
- Comprehensive Data Lineage Tracking: It meticulously records the origin, transformations, and movements of data, providing an auditable trail essential for compliance and troubleshooting.
- Data Quality Monitoring: By linking contextual information (e.g., schema, data types, business rules) with data assets, the metadata layer facilitates proactive identification of data quality issues.
- Role-Based Access Control (RBAC): Enriching data definitions with ownership and sensitivity labels allows for precise, role-based access control, ensuring only authorized users can access specific datasets.
- Compliance Auditing: For regulations like GDPR, CCPA, or HIPAA, the metadata layer provides the necessary documentation and traceability for compliance audits.
- Consistent Data Definitions: It serves as a single source of truth for business terms and technical definitions, fostering a common understanding across the organization and preventing semantic inconsistencies.
Primary AI/ML Integration
For organizations leveraging AI and Machine Learning, the metadata layer is an indispensable tool:
- Data Discovery for ML Engineers: ML engineers can quickly find relevant datasets, features, and pre-processed data crucial for model training and experimentation.
- Feature Store Management: Metadata helps track feature definitions, transformations, and usage across different models, enhancing the reusability and consistency of features. It’s vital for knowing which features have been used, how they were engineered, and their performance.
- Model Lineage and MLOps: In MLOps workflows, the metadata layer manages model metadata (e.g., training data, hyperparameters, version, performance metrics, deployment status), providing critical context for model governance, reproducibility, and debugging.
- Enriching Data for Training and Validation: By adding contextual information such as business definitions, data quality scores, and ethical considerations, metadata enriches the understanding of data used for AI, leading to more robust and fair models. This also includes metadata on Data Labeling activities, detailing who labeled what, when, and under what guidelines, which is crucial for supervised learning.

Figure 1: Conceptual Framework Highlighting the Analytics Layer’s Reliance on Underlying Data Structures.
Challenges/Barriers to Adoption
Despite its profound benefits, implementing and maintaining a robust metadata layer comes with its own set of challenges:
- Data Volume and Variety: The sheer volume and diversity of data sources (structured, semi-structured, unstructured) make comprehensive metadata extraction and cataloging a complex task. Maintaining up-to-date metadata across a vast, constantly evolving data landscape is a significant operational challenge.
- Integration Complexity: Integrating metadata from disparate systems (databases, APIs, streaming platforms, cloud services) often requires custom connectors and continuous maintenance, leading to high initial setup costs and ongoing overhead.
- Lack of Standardization: Different data sources often use varying naming conventions and definitions, making it difficult to achieve consistent metadata. Establishing organizational-wide standards and enforcing them can be a cultural and technical hurdle.
- Maintaining Relevance and Accuracy: Metadata can quickly become stale if not regularly updated. Manual processes are unsustainable, necessitating automated tools that can detect schema changes, data transformations, and usage patterns.
- Addressing Data Drift and MLOps Complexity: For AI/ML, the metadata layer must dynamically capture changes in data distribution (data drift) and model performance. In complex MLOps environments, managing metadata for hundreds or thousands of models, experiments, and features adds significant complexity. Without automated metadata capture, these challenges become insurmountable.
- Organizational Buy-in and Expertise: Implementing a metadata strategy requires clear ownership, dedicated resources, and buy-in from various stakeholders, including data owners, engineers, and business users. Lack of understanding or perceived value can hinder adoption.
Business Value and ROI
The return on investment (ROI) of a well-implemented metadata layer is multifaceted and substantial:
- Faster Data Discovery and Time-to-Insight: By providing a searchable catalog, metadata drastically reduces the time data professionals spend looking for data, directly accelerating analytical projects and decision-making processes.
- Improved Data Quality for AI: Contextual metadata about data quality, lineage, and definitions directly translates to higher quality data for training AI models, leading to more accurate predictions and reliable AI applications.
- Enhanced Data Governance and Compliance: Automation of lineage tracking, access controls, and policy enforcement simplifies compliance efforts, reduces regulatory risk, and builds trust in data.
- Increased Data Literacy and Collaboration: A comprehensive metadata layer democratizes data access and understanding, empowering more employees to use data effectively and fostering a data-driven culture.
- Reduced Operational Costs: By streamlining data discovery, preparation, and governance, organizations can reduce manual effort, eliminate redundant data preparation tasks, and lower overall operational expenses.
- Faster Model Deployment: For MLOps, metadata accelerates the feature engineering process, simplifies model monitoring, and enables quicker deployment of robust AI models into production.
Comparative Insight: Metadata in Modern vs. Traditional Data Architectures
The importance and role of the metadata layer have evolved significantly with changes in data architecture. Historically, in traditional data warehouse (DW) environments, metadata management was often a more centralized and somewhat static process, primarily focused on schema definitions, ETL mappings, and report structures. While critical, its scope was often limited to well-defined, structured data within a controlled environment.
In a traditional DW, metadata would typically describe:
- Source system details and table structures.
- ETL (Extract, Transform, Load) job definitions and mappings.
- Dimensions, facts, and aggregate structures within the DW.
- Business glossaries tied to DW tables and columns.
The metadata was largely technical and static, updated infrequently, and often managed through proprietary tools tightly coupled with the DW platform.
The advent of big data brought forth the data lake concept, which promised flexibility and storage of raw, multi-structured data. However, early data lakes often became “data swamps” due to a lack of robust metadata management. Without proper cataloging, lineage, and contextual information for the vast, unrefined data, discovery became nearly impossible. This exposed a critical gap: simply storing data isn’t enough; you need to know what you have and what it means.
Today, the modern data architecture, often influenced by the principles of an AI Data Platform, places the metadata layer at its very heart. It’s no longer an afterthought but a central nervous system that stitches together diverse components like data lakes, data warehouses, streaming platforms, feature stores, and machine learning platforms. In this paradigm, the metadata layer is dynamic, intelligent, and pervasive.
A modern metadata layer:
- Is Active and Automated: It continuously scans, profiles, and extracts metadata from all data sources, including real-time streams and unstructured data.
- Supports Diverse Data Types: It handles schema-on-read scenarios, tagging unstructured data, and linking complex relationships across semi-structured data.
- Integrates with AI/ML Workflows: It provides crucial context for feature engineering, model training, and MLOps, including tracking model artifacts and experiment metadata.
- Enables Self-Service: By providing intuitive data catalogs and semantic layers, it empowers a wider range of users, from data scientists to business analysts, to discover and utilize data independently.
- Drives Data Governance: It serves as the single source of truth for policies, access controls, and compliance requirements across the entire data estate, making it far more agile than traditional governance models.
In essence, while traditional systems treated metadata as a descriptive afterthought for structured data, modern AI Data Platforms elevate the metadata layer to an operational component, an active agent for data discovery, governance, and the very functioning of AI/ML pipelines. This shift is critical for building scalable, trustworthy, and intelligent data ecosystems.
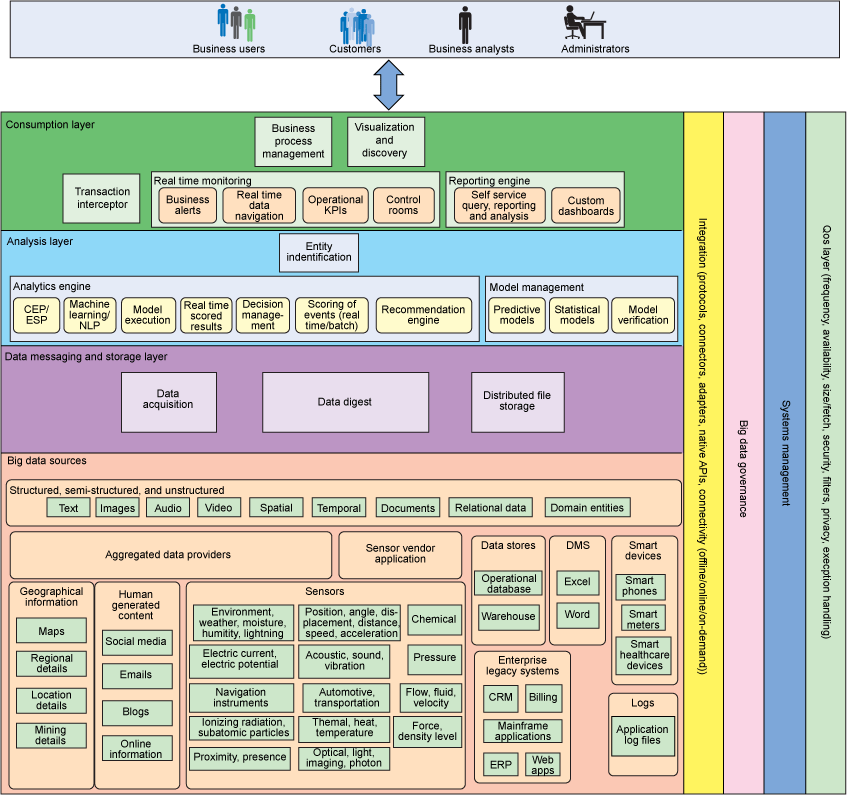
Figure 2: An Example of a Metadata Management Architecture.
World2Data Verdict: The Future is Metadata-Driven
The role of the Metadata Layer is undeniably transitioning from a mere technical necessity to a strategic business imperative. For organizations aspiring to harness the full power of their data, especially within an advanced Analytics Layer and burgeoning AI/ML initiatives, investing in a robust, automated, and intelligent metadata layer is no longer optional—it is critical. World2Data.com asserts that future-proof data strategies will be those that prioritize and embed metadata management as a central pillar, fostering data literacy, accelerating innovation, and ensuring compliance.
Our recommendation is clear: organizations must move beyond passive data cataloging towards active metadata management. This involves leveraging technologies like graph databases for rich relationship mapping, integrating AI-powered metadata extraction and quality checks, and fostering a culture where metadata creation and consumption are integral to every data-related process. As data volumes explode and AI becomes ubiquitous, the ability to find, understand, and trust data will hinge entirely on the sophistication and pervasiveness of the metadata layer. It is the silent hero making data truly discoverable and analytically valuable.

{kind=link}