


Automated Big Data Pipeline: Powering Real-time Insights and Operational Efficiency
- Platform Category: ETL/ELT and Workflow Orchestration
- Core Technology/Architecture: Batch and Stream Processing, Serverless Computing
- Key Data Governance Feature: Automated Data Lineage Tracking
- Primary AI/ML Integration: MLOps Lifecycle Automation (e.g., automated model retraining triggers)
- Main Competitors/Alternatives: Apache Airflow, AWS Glue, Azure Data Factory, Google Cloud Dataflow, Apache Kafka
The modern enterprise thrives on data. In a world awash with information, the ability to efficiently ingest, process, and analyze massive, disparate datasets in a timely manner is no longer a luxury but a fundamental necessity for competitive advantage. An Automated Big Data Pipeline is the technological backbone that makes this possible, transforming raw data into actionable insights with minimal human intervention. This comprehensive mechanism ensures data readiness, accuracy, and accessibility, driving everything from operational efficiencies to strategic decision-making and the deployment of advanced analytics and artificial intelligence.
Introduction: The Imperative of Automated Big Data Pipelines
In the digital age, businesses face an unprecedented deluge of data from myriad sources: IoT devices, social media, transactional systems, web logs, and more. This torrent, often referred to as “big data,” is characterized by its volume, velocity, and variety. Manually managing and processing such complex data streams is not only impractical but also introduces significant delays, errors, and prohibitive costs. This is where the concept of an Automated Big Data Pipeline emerges as a critical solution.
An automated pipeline represents a sophisticated architectural pattern designed to streamline the entire data lifecycle. From the moment data is generated at its source to its ultimate transformation and delivery into a destination system for analysis or application, automation ensures a continuous, reliable, and scalable flow. This article will delve into the technical intricacies, explore the profound business value, and compare these modern systems with traditional approaches, providing a deep dive into why these pipelines are indispensable for any data-driven organization.
Core Breakdown: Architecture, Benefits, Challenges, and ROI
What is an Automated Big Data Pipeline?
An Automated Big Data Pipeline refers to a set of interconnected processes designed to move data from various sources, transform it, and load it into a destination system with minimal human intervention. This ensures data is always fresh and ready for use. It orchestrates a series of steps, including data ingestion, cleansing, transformation, enrichment, and loading, often leveraging advanced technologies to handle diverse data types and scales. The goal is to provide a consistent, high-quality data supply chain that feeds business intelligence tools, analytical dashboards, machine learning models, and operational applications.
Why Automation Matters Now
Manual processes are slow, error-prone, and unsustainable with the exponential growth of big data. Automation addresses these challenges, providing speed, consistency, and reliability across all data operations. Without automation, organizations would be bogged down in repetitive, tedious tasks, unable to keep pace with the real-time demands of the market or unlock the true potential hidden within their data assets. Automation liberates data engineers and analysts from mundane tasks, allowing them to focus on more strategic initiatives and innovation.
Key Benefits for Businesses
- Enhanced Efficiency and Speed: Automation drastically cuts down the time from data ingestion to insight, enabling faster decision-making and real-time analytics. Tasks that once took hours now complete in minutes, accelerating business processes. This velocity is crucial for use cases like fraud detection, personalized customer experiences, and dynamic pricing strategies.
- Superior Data Quality and Reliability: By standardizing processes, automated pipelines reduce human errors, leading to cleaner, more accurate, and dependable data. This improved quality is essential for critical business operations, regulatory compliance, and building trust in data-driven decisions. Automated validation rules, anomaly detection, and data reconciliation mechanisms ensure data integrity throughout its journey.
- Cost Reduction and Resource Optimization: Businesses save significant operational costs by freeing up valuable engineering resources from repetitive manual tasks. This allows teams to focus on innovation and more strategic initiatives rather than maintenance. The reduction in manual effort translates directly into lower labor costs and more efficient utilization of highly skilled personnel.
Core Components Explained
A robust Automated Big Data Pipeline is composed of several critical stages, each often powered by specialized tools and technologies:
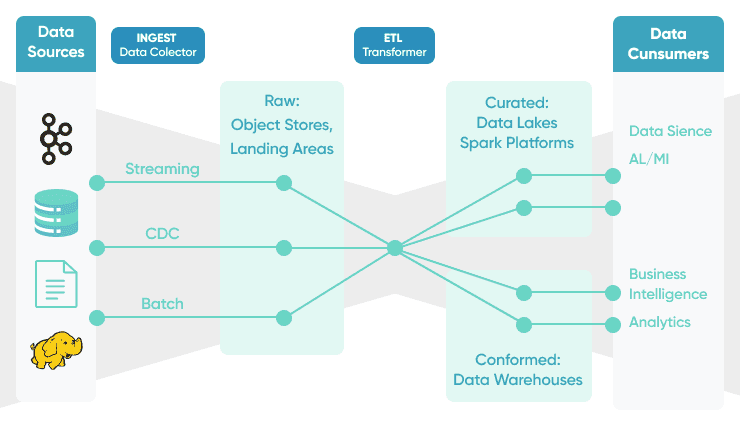
- Data Ingestion: This involves sourcing data from diverse origins like databases (relational, NoSQL), streams (Kafka, Kinesis), APIs, files (CSV, JSON, Parquet), and SaaS applications. Tools like Apache Kafka for real-time streaming, Apache Sqoop for batch transfers from relational databases, or custom API connectors are common here.
- Data Transformation: Once ingested, data often needs cleaning, structuring, and enriching into a usable format. This stage might involve data parsing, schema validation, deduplication, aggregation, joining with other datasets, and feature engineering for machine learning. Technologies such as Apache Spark, Apache Flink, or cloud-native services like AWS Glue, Azure Data Factory, and Google Cloud Dataflow are widely used. Data Build Tool (dbt) has also emerged as a powerful tool for analytics engineering and transformation within the data warehouse.
- Data Storage: Transformed data is typically loaded into optimized storage solutions. This can include data warehouses (Snowflake, Google BigQuery, Amazon Redshift) for structured analytical data, data lakes (Amazon S3, Azure Data Lake Storage, Google Cloud Storage) for raw or semi-structured data, or NoSQL databases (Cassandra, MongoDB) for specific application needs.
- Orchestration and Monitoring Tools: These components manage the workflow, schedule tasks, and provide visibility into the pipeline’s health. They ensure smooth operation, prompt issue resolution, and overall system reliability. Tools like Apache Airflow, Dagster, and Prefect enable complex dependency management, retries, and alerts. Monitoring tools integrate with these orchestrators to provide dashboards, logs, and alerts for performance, errors, and data quality issues.
Challenges and Barriers to Adoption
While the benefits of an Automated Big Data Pipeline are substantial, implementing and maintaining one presents its own set of challenges:
- Data Volume and Velocity Management: Scaling pipelines to handle petabytes of data arriving at high velocity requires careful architectural design and choice of highly scalable technologies. Over-provisioning or under-provisioning resources can lead to inefficiency or bottlenecks.
- Integration Complexity: Connecting disparate data sources, each with its own APIs, data formats, and authentication mechanisms, can be a significant hurdle. Ensuring seamless data flow across heterogeneous systems requires robust integration strategies.
- Data Quality and Governance: Maintaining high data quality throughout the pipeline is crucial. Issues like schema drift, corrupted data, or inconsistencies can propagate and undermine trust in insights. Implementing automated data quality checks, data validation rules, and comprehensive data lineage tracking is complex but essential for effective data governance.
- Skill Gap and Tool Proliferation: The ecosystem of big data tools is vast and constantly evolving. Finding professionals with the expertise in distributed systems, streaming technologies, cloud platforms, and data engineering best practices can be challenging. Managing a multitude of tools effectively also adds to operational overhead.
- Cost of Implementation and Maintenance: Initial setup costs for infrastructure, software licenses, and skilled personnel can be substantial. Furthermore, ongoing maintenance, monitoring, and adaptation to evolving business requirements or data sources require continuous investment.

Business Value and ROI of Automation
Investing in an Automated Big Data Pipeline yields significant returns across various business dimensions:
- Accelerated Time-to-Insight: By automating data preparation and delivery, organizations can move from raw data to actionable insights much faster. This agility allows businesses to respond quickly to market changes, identify new opportunities, and mitigate risks, directly impacting revenue and competitive positioning.
- Improved Data-Driven Decision Making: Consistent access to high-quality, up-to-date data empowers decision-makers with reliable information. This reduces reliance on intuition and leads to more informed, strategic choices across all departments, from marketing to product development and finance.
- Reduced Operational Overheads: The automation of repetitive tasks significantly lowers operational costs associated with manual data handling, error correction, and system maintenance. It frees up highly skilled data engineers and analysts to focus on innovation and solving complex business problems, rather than spending time on routine data plumbing.
- Enhanced Scalability and Agility: Automated pipelines are designed to scale dynamically, handling fluctuating data volumes and velocities without requiring constant manual intervention. This inherent agility allows businesses to quickly adapt to new data sources, integrate new applications, and support evolving business requirements with minimal disruption.
- Compliance and Risk Mitigation: Automated data lineage tracking and robust data governance features ensure that data flow is transparent, auditable, and compliant with regulatory standards (e.g., GDPR, CCPA). This minimizes legal and reputational risks associated with data breaches or mismanagement.
Comparative Insight: Automated Big Data Pipeline vs. Traditional Data Architectures
Understanding the value of an Automated Big Data Pipeline is enhanced by comparing it to more traditional data management architectures, primarily the Data Lake and Data Warehouse.
- Traditional Data Warehouse: Historically, data warehouses were the cornerstone of business intelligence. They are highly structured, schema-on-write systems designed for aggregated, clean, and historical data, primarily from operational databases. Data flows were typically batch-oriented ETL (Extract, Transform, Load) processes. While excellent for structured reporting and predefined queries, they struggle with unstructured data, real-time processing, and the agility required by modern analytics and machine learning.
- Traditional Data Lake: Data lakes emerged to address the limitations of data warehouses by storing raw, unstructured, and semi-structured data at scale, often with a schema-on-read approach. They provide flexibility and cost-effectiveness for storing vast amounts of diverse data. However, traditional data lakes can become “data swamps” without proper governance, metadata management, and well-defined pipelines to refine and transform the raw data into usable formats. Data movement and processing often still relied on manual scripting or less automated batch jobs.
An Automated Big Data Pipeline significantly enhances both data lakes and data warehouses, often acting as the critical connective tissue between them, or even evolving into a unified “data lakehouse” architecture. Key differences:
- Real-time vs. Batch Processing: Traditional systems are predominantly batch-oriented. Automated pipelines, especially those incorporating stream processing technologies, are designed for near real-time data ingestion and transformation, crucial for applications like live dashboards, personalized recommendations, and anomaly detection.
- Agility and Iteration: With automation and orchestration, pipelines allow for quicker changes, easier experimentation with new data sources or transformations, and faster deployment of new data products. Traditional systems often involve lengthy development cycles for schema changes or new data integrations.
- Diverse Data Types and Sources: While data lakes can store diverse data, automated pipelines provide the mechanisms to actually process and integrate that diversity, regardless of structure or origin, into cohesive datasets for analysis.
- Operational Overhead: Manual ETL/ELT processes in traditional setups demand constant attention for monitoring, error handling, and maintenance. Automated pipelines drastically reduce this operational burden, making data management more scalable and sustainable.
- AI/ML Readiness: Automated pipelines are inherently designed to prepare data for advanced analytics and machine learning. They can automatically generate features, handle data versioning, and feed clean, prepared data directly into MLOps workflows, a capability largely absent or difficult to achieve with traditional, static data architectures.
Future Trends and Impact
The evolution of the Automated Big Data Pipeline is far from complete, with several key trends shaping its future:
- AI and Machine Learning Integration: Future pipelines will increasingly incorporate AI for predictive analytics, anomaly detection, and self-optimizing data flows, making them even smarter and more proactive in managing information assets. This includes AI-powered data quality checks, automated schema inference, intelligent data routing, and self-healing capabilities that predict and prevent pipeline failures. Furthermore, automated pipelines are becoming the critical backbone for MLOps, enabling automated model retraining triggers, feature store management, and deployment of machine learning models into production environments with fresh data.
- Democratizing Data Access: Automated pipelines are empowering more users across an organization to access and derive insights from data independently. This fosters a truly data-driven culture throughout all departments and decision-making levels. With self-service data platforms built on top of automated pipelines, business users, citizen data scientists, and analysts can leverage high-quality data without deep technical expertise, fostering innovation at every level.
- Cloud-Native and Serverless Architectures: The shift towards cloud computing continues to accelerate, with automated pipelines heavily leveraging serverless functions (AWS Lambda, Azure Functions, Google Cloud Functions) and managed services (AWS Glue, Data Factory, Dataflow). This allows organizations to build highly scalable, cost-effective, and resilient pipelines without managing underlying infrastructure.
- Data Mesh and Data Fabric Integration: As organizations grow, monolithic data architectures struggle. Future pipelines will increasingly integrate with data mesh principles, promoting decentralized data ownership and domain-oriented data products, and data fabric architectures, which provide a unified, intelligent layer over disparate data sources. Automated pipelines will be crucial for delivering these data products and managing the underlying data flows across these distributed environments.
- Ethical AI and Responsible Data Use: With the growing use of AI and personalized services, automated pipelines will need to incorporate more robust mechanisms for privacy preservation, bias detection, and ethical data usage. Automated tracking of data lineage and transformations will be critical for auditing and ensuring compliance with emerging ethical AI guidelines.
World2Data Verdict
The journey towards full data maturity hinges upon the effective implementation and continuous optimization of an Automated Big Data Pipeline. For any organization aiming to harness the full power of its data assets, achieve real-time insights, fuel AI/ML initiatives, and maintain a competitive edge, investing in robust automation is not optional—it is a strategic imperative. World2Data.com recommends a phased adoption strategy, starting with critical data flows and gradually expanding, while prioritizing scalable, cloud-native solutions that support both batch and stream processing. The future of data is automated, intelligent, and real-time, and enterprises must embrace this evolution to thrive.

{kind=link}