


Data Lake Explained: How Modern Companies Store Big Data
In the era of unprecedented data growth, understanding effective data management strategies is paramount for competitive advantage. A Data Lake represents a revolutionary approach, moving beyond traditional constraints to offer a scalable, flexible, and cost-efficient solution for storing and processing vast quantities of information. This isn’t merely a storage repository; it’s a strategic asset designed to unlock profound insights, fuel advanced analytics, and underpin the most ambitious AI and Machine Learning initiatives.
Modern companies are leveraging Data Lakes to consolidate diverse data types, break down silos, and establish a unified foundation for data-driven decision-making, transforming raw digital footprints into actionable intelligence. This deep dive will explore the intricacies of Data Lake technology, its architectural prowess, and its indispensable role in today’s data-centric economy.
Introduction: Embracing the Deluge with a Data Lake
The digital age has ushered in an era where data is generated at an exponential rate, encompassing everything from transactional records and customer interactions to sensor readings and social media feeds. This “big data” is characterized not just by volume, but also by velocity, variety, and veracity. Traditional data storage systems, often designed for highly structured data with predefined schemas, struggle to cope with this complexity.
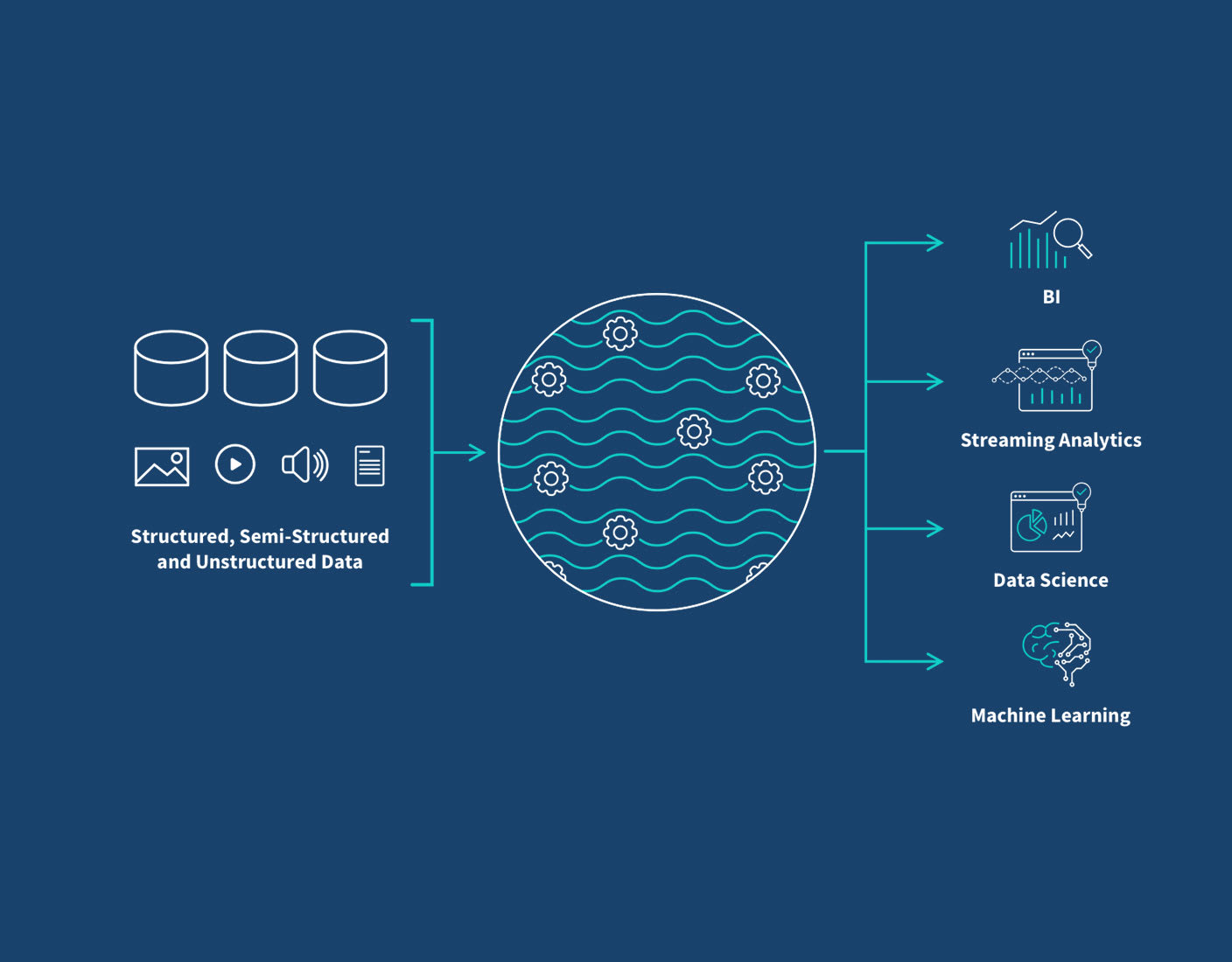
Enter the Data Lake. At its core, a Data Lake is a centralized repository that allows you to store all your structured, semi-structured, and unstructured data at any scale. Unlike conventional databases or data warehouses that require data to be structured and transformed before storage, a Data Lake ingests data in its native format. This “schema-on-read” approach defers the application of a data model until the data is actually queried or analyzed, offering unparalleled flexibility. It’s a concept that significantly simplifies data ingestion and empowers organizations to capture every piece of data, postponing the decision of how to use it until business needs become clear. For any modern enterprise looking to harness the full power of its information assets, understanding and implementing a robust Data Lake strategy is no longer optional, but essential.
Core Breakdown: Architecture, Components, and Strategic Value of a Data Lake
The essence of a successful Data Lake lies in its architecture and the strategic components that enable it to handle diverse data workloads efficiently. From raw ingestion to sophisticated analytics, each layer plays a critical role in transforming vast quantities of raw data into actionable intelligence.
Understanding the Data Lake Architecture
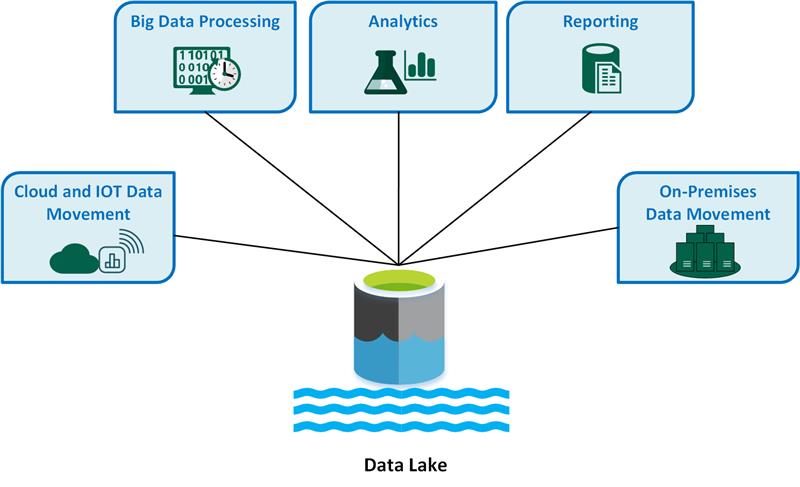
A typical Data Lake architecture comprises several logical layers, each with distinct functions:
- Ingestion Layer: This layer is responsible for collecting data from various sources. It supports both batch processing (e.g., ETL jobs for historical data from relational databases, enterprise applications, or flat files) and real-time streaming (e.g., IoT device data, clickstreams, social media feeds, logs) using technologies like Apache Kafka, Apache Nifi, AWS Kinesis, or Azure Event Hubs.
- Storage Layer: This is the foundation where raw, untransformed data resides. Core technologies here include distributed file systems like Hadoop HDFS (on-premises) or highly scalable, cost-effective cloud object storage services such as Amazon S3, Azure Data Lake Storage (ADLS), or Google Cloud Storage (GCS). These systems are designed for massive scalability, durability, and fault tolerance, supporting petabytes of data at minimal cost per gigabyte. The schema-on-read principle is fundamental here, meaning data is stored without a predefined schema.
- Processing/Refinement Layer: Once ingested, data often needs to be cleaned, transformed, and enriched before it’s ready for analytical consumption. This layer uses powerful processing engines like Apache Spark, Apache Flink, or Hadoop MapReduce to perform operations such as data cleansing, deduplication, format conversion (e.g., to Parquet or ORC for optimized query performance), and feature engineering. Data is often moved through different zones – from raw to bronze, silver, and gold – representing increasing levels of refinement and structure.
- Consumption Layer: This layer enables users and applications to access and analyze the processed data. It integrates with various analytical tools and services, including SQL query engines (e.g., Presto, Apache Hive, AWS Athena, Azure Synapse SQL), business intelligence (BI) tools (e.g., Tableau, Power BI, Qlik Sense), and machine learning platforms (e.g., Apache Spark MLlib, AWS SageMaker, Azure ML).
Key Data Governance Features for a Robust Data Lake
While the flexibility of a Data Lake is a major advantage, it also necessitates robust data governance to prevent it from becoming a “data swamp.” Key governance features include:
- Metadata Management and Data Cataloging: Tools like Apache Atlas, AWS Glue Data Catalog, or Azure Data Catalog provide a centralized repository for metadata, enabling users to discover, understand, and trust the data assets within the lake. They describe data types, schemas (when applied), lineage, and ownership.
- Access Control Lists (ACLs) and Role-Based Access Control (RBAC): Essential for ensuring data security and privacy. These mechanisms dictate who can access what data, at what level (read, write, execute), and under what conditions. Integration with enterprise identity management systems is crucial.
- Data Quality and Lineage: Implementing processes and tools to monitor, measure, and improve data quality throughout its lifecycle. Data lineage tracking helps understand the origin, transformations, and destinations of data, which is vital for compliance and debugging.
Primary AI/ML Integration: Powering Intelligent Applications
The true power of a Data Lake for modern enterprises lies in its ability to serve as the bedrock for Artificial Intelligence and Machine Learning initiatives. Its capacity to store vast amounts of raw, diverse data makes it an ideal environment for:
- ML Model Training: Providing the raw, extensive datasets necessary to train robust and accurate machine learning models across various domains, from recommendation engines to fraud detection.
- Feature Engineering: Data scientists can easily access and experiment with raw data to create new features that enhance model performance, leveraging the lake’s flexibility to iterate quickly.
- Experimentation and Sandbox Environments: Data Lakes offer cost-effective storage for creating multiple datasets and data versions, allowing data scientists to experiment without impacting production systems.
- Integration with MLOps Platforms: Seamlessly connecting with MLOps tools and platforms (like MLflow, Kubeflow, or cloud-specific services) to streamline the entire ML lifecycle, from data preparation to model deployment and monitoring.
Challenges and Barriers to Data Lake Adoption
Despite its numerous advantages, implementing and managing a Data Lake comes with its own set of challenges that organizations must proactively address:
- Data Swamps: Without proper governance and metadata management, a Data Lake can quickly devolve into a “data swamp”—a repository of ungoverned, uncataloged, and useless data. This makes data discovery and usability nearly impossible.
- Data Quality Issues: Storing raw data means inheriting its quality issues. Without rigorous data cleansing and validation processes, analytical outputs can be unreliable, leading to flawed insights.
- Security and Compliance: Protecting sensitive data in its raw form across a vast, flexible storage system is complex. Ensuring compliance with regulations like GDPR, CCPA, or HIPAA requires robust access controls, encryption, and auditing capabilities.
- Skill Gap: Managing and extracting value from a Data Lake requires specialized skills in areas like distributed computing, big data technologies (Spark, Hadoop), cloud infrastructure, and data science. A shortage of these skills can hinder adoption and effectiveness.
- Cost Management: While object storage is cost-effective, processing large volumes of data can incur significant compute costs. Optimizing storage formats, query patterns, and resource allocation is crucial to control operational expenses.
Business Value and ROI of a Data Lake
When implemented correctly, the return on investment (ROI) from a Data Lake can be substantial, driving significant business value:
- Faster Time to Insight: By reducing the need for extensive upfront data modeling, organizations can ingest and analyze data much more quickly, accelerating discovery and decision-making.
- Enhanced Business Agility: The flexibility to store any data type and apply schemas on-read allows businesses to adapt rapidly to new data sources and analytical requirements without re-architecting their entire data infrastructure.
- Democratization of Data: A centralized Data Lake breaks down data silos, making diverse datasets accessible to a broader range of users, including data scientists, analysts, and business users, fostering a data-driven culture.
- Fueling Innovation with AI/ML: Provides the foundation for advanced analytics, machine learning, and artificial intelligence, enabling the development of predictive models, personalized experiences, and new data products.
- Cost-Effectiveness: Storing raw data on inexpensive object storage significantly reduces the cost per terabyte compared to traditional data warehouses, especially for very large datasets that may not have immediate, well-defined use cases.
- Comprehensive Customer View: By integrating data from all touchpoints, businesses can build a 360-degree view of their customers, leading to more targeted marketing, improved service, and better product development.
Comparative Insight: Data Lake vs. Traditional Data Warehouse and the Rise of the Lakehouse
Understanding the value of a Data Lake often comes into sharper focus when compared to its predecessors and successors in the data management landscape. Traditionally, the Data Warehouse has been the cornerstone of enterprise analytics, while the emerging Data Lakehouse seeks to combine the best of both worlds.
Data Lake vs. Data Warehouse
The distinction between a Data Lake and a Data Warehouse is crucial for selecting the right tool for specific analytical needs:
- Data Type & Structure: A Data Lake stores raw, untransformed data of all types (structured, semi-structured, unstructured). It uses a “schema-on-read” approach, applying structure only when data is accessed. A Data Warehouse, conversely, stores highly structured, processed data, typically from operational systems, adhering to a predefined schema (schema-on-write).
- Purpose & Use Cases: Data Lakes are ideal for exploratory analytics, data science, machine learning, and storing data for future, undefined uses. They cater to data scientists and advanced analysts. Data Warehouses are optimized for traditional reporting, structured queries, and business intelligence, serving business analysts and executives who need clean, consistent data for well-defined questions.
- Data Quality & Governance: Data in a Warehouse is typically highly curated, clean, and governed, making it reliable for critical business decisions. Data in a Data Lake, being raw, may have varying quality, necessitating robust governance frameworks to manage potential “data swamps.”
- Cost & Performance: Storing data in a Data Lake is generally more cost-effective due to the use of inexpensive object storage for raw data. However, querying raw data can sometimes be slower and more complex. Data Warehouses often involve higher storage costs but offer superior performance for structured, complex SQL queries.
Often, a hybrid approach is adopted where a Data Lake acts as the landing zone for all raw data, which is then processed, cleaned, and refined. A subset of this processed data, optimized for specific business questions, is then loaded into a Data Warehouse for traditional BI and reporting, illustrating a complementary relationship rather than a competitive one.
The Rise of the Data Lakehouse
Recognizing the strengths and weaknesses of both Data Lakes and Data Warehouses, the “Data Lakehouse” architecture has emerged as an evolutionary step. A Lakehouse attempts to combine the low-cost storage and flexibility of a Data Lake with the data management features (like transactions, schema enforcement, data quality, and governance) traditionally found in a Data Warehouse. Technologies like Delta Lake, Apache Iceberg, and Apache Hudi are critical enablers for Lakehouse architectures, allowing users to perform ACID transactions on data stored in object storage, enforce schemas, and manage data versions effectively. This hybrid model aims to offer the best of both worlds: raw data flexibility for AI/ML alongside robust governance and performance for BI.
World2Data Verdict: The Indispensable Role of the Modern Data Lake
For World2Data.com, the verdict is clear: the Data Lake is no longer just an option for organizations grappling with big data; it is a foundational, strategic imperative. Its ability to ingest and store data at any scale, in any format, provides unparalleled agility and a future-proof data infrastructure. While challenges around governance and quality persist, advances in metadata management, automated data quality tools, and the emergence of the Lakehouse architecture are actively addressing these concerns.
We believe that enterprises aiming for true data-driven transformation, especially those heavily investing in AI, Machine Learning, and real-time analytics, must embrace a well-architected Data Lake. It serves as the single source of truth for all data, empowering innovative applications, fostering deeper insights, and ultimately driving a significant competitive edge. The future of data management is undeniably centered around robust, governed Data Lake environments that can evolve with an organization’s analytical ambitions and the ever-changing landscape of data itself. Ignoring its potential is to risk being left behind in the race for data supremacy.

{kind=link}