


Lakehouse Architecture: Revolutionizing Analytics Workloads for the Future
Platform Category: Unified Data Platform Architecture
Core Technology/Architecture: Combines features of data lakes (open formats, scalability, low cost) and data warehouses (ACID transactions, schema enforcement, data governance)
Key Data Governance Feature: ACID transactions, schema enforcement, data versioning, unified security and access control for structured and unstructured data
Primary AI/ML Integration: Direct access to raw data for ML model training, support for various ML frameworks and tools, unified data pipelines for analytics and machine learning
Main Competitors/Alternatives: Separate Data Lake and Data Warehouse, traditional Enterprise Data Warehouses, Data Hubs
The Lakehouse Architecture presents a compelling evolution in how organizations manage and leverage their data, fundamentally reshaping the landscape of data management. This innovative approach offers a revolutionary convergence of the best attributes of data lakes and data warehouses, addressing the traditional complexities and limitations faced by enterprises striving for unified data management and advanced analytical capabilities. By integrating the scalability and cost-effectiveness of data lakes with the reliability and structure of data warehouses, the Data Lakehouse promises a simplified yet powerful infrastructure, critical for driving insightful decisions and fostering innovation across diverse workloads.
Introduction: The Dawn of Unified Data Management with Data Lakehouse
In an era driven by data, organizations constantly seek more efficient, scalable, and cost-effective ways to manage their ever-growing volumes of information. Traditional architectures, often comprising distinct data lakes for raw, unstructured data and data warehouses for structured, curated insights, have presented significant challenges. These challenges include data duplication, complex ETL processes, inconsistent governance, and a fragmented view of the organization’s data assets. The emergence of the Lakehouse Architecture directly confronts these issues, proposing a single, unified platform that combines the flexibility of data lakes with the robust data management features of data warehouses. This integration empowers businesses to unlock new levels of analytical sophistication and accelerate their journey towards data-driven intelligence, making the Data Lakehouse a cornerstone for future analytics workloads and AI initiatives.
Core Breakdown: Dissecting the Lakehouse Architecture
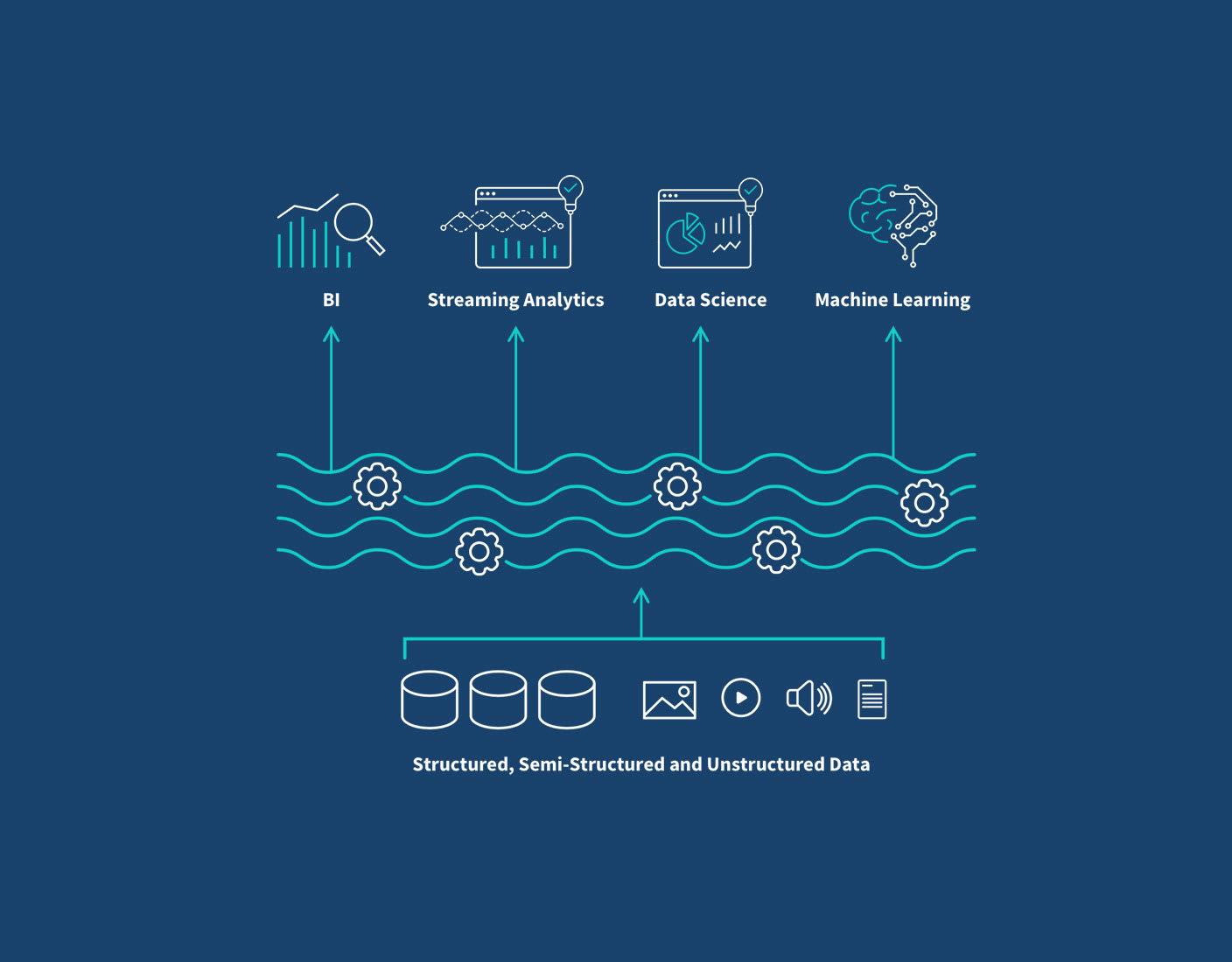
Unpacking the Data Lakehouse concept reveals its core strength: providing both the flexibility of data lakes and the robust ACID (Atomicity, Consistency, Isolation, Durability) transactions and schema enforcement of data warehouses. At its heart, a Lakehouse leverages open, standardized data formats (like Parquet or ORC) stored in low-cost object storage, which is characteristic of data lakes. However, it overlays a transactional layer that introduces ACID properties, schema enforcement, and data versioning capabilities, traditionally found in data warehouses. This allows businesses to store vast amounts of raw, unstructured data while simultaneously enabling structured querying, reliable data governance, and high-performance analytics.
Key components typically found within a robust Lakehouse Architecture include:
- Scalable Object Storage: Utilizes cloud storage solutions (e.g., AWS S3, Azure Data Lake Storage, Google Cloud Storage) for cost-effective and virtually limitless storage of raw and processed data.
- Open Data Formats: Employs formats like Parquet, ORC, and Avro to ensure interoperability and avoid vendor lock-in.
- Transactional Layer (e.g., Delta Lake, Apache Iceberg, Apache Hudi): This is the defining feature, adding ACID compliance, schema evolution, time travel (data versioning), and upsert/delete capabilities directly on the data lake.
- Metadata Management: Tools for cataloging data, managing schemas, and tracking data lineage are crucial for discoverability and governance.
- Unified Query Engines: Supports various analytical workloads, from SQL queries to machine learning computations, often through engines like Spark, Presto, or Athena.
- Data Governance Frameworks: Centralized security, access control, auditing, and compliance policies applied uniformly across all data types.
Challenges and Barriers to Adoption
Despite the immense promise of the Data Lakehouse, organizations adopting this architecture may encounter several challenges:
- Migration Complexity: Moving existing data and workloads from legacy systems or disparate data lakes/warehouses to a unified Lakehouse can be a complex and resource-intensive undertaking, requiring careful planning and execution.
- Skill Gap: Implementing and managing a Lakehouse requires a blend of skills in big data technologies, data warehousing concepts, and increasingly, MLOps practices. Finding talent with this diverse expertise can be a significant barrier.
- Data Quality and Governance Implementation: While the Lakehouse provides the tools for robust governance (ACID, schema enforcement), establishing and enforcing effective data quality standards and governance policies across diverse data types still demands a disciplined approach and organizational commitment.
- Tooling and Ecosystem Maturity: While the Lakehouse ecosystem is rapidly maturing, choosing the right combination of tools (transactional layers, query engines, governance frameworks) that seamlessly integrate can still be challenging.
- Cost Management: While object storage is cheap, the computational resources required for processing large datasets on a Lakehouse, especially for demanding analytical or machine learning workloads, can still incur significant cloud costs if not properly managed and optimized.
Business Value and ROI of a Lakehouse Architecture
The strategic advantages of adopting a Data Lakehouse translate into significant business value and a compelling return on investment:
- Faster Model Deployment: By providing a unified platform for raw data, feature engineering, and model training, the Lakehouse accelerates the entire machine learning lifecycle, enabling quicker deployment of AI models.
- Enhanced Data Quality for AI: The ACID properties and schema enforcement ensure that data used for AI/ML training is reliable and consistent, leading to more accurate and robust models.
- Reduced Data Silos and Complexity: A single platform for all data types eliminates the need for complex data movement between systems, simplifying data pipelines and reducing operational overhead.
- Cost-Effectiveness: Leveraging affordable object storage dramatically reduces infrastructure costs compared to traditional, expensive data warehouses, while still offering comparable performance for analytical workloads.
- Democratized Data Access: Business users, data analysts, and data scientists can all access and query the same consistent data through various interfaces, fostering a more data-driven culture and quicker insights.
- Real-time Analytics Capabilities: The architecture supports streaming data ingestion and processing, enabling organizations to perform real-time analytics and respond to business events with greater agility.

Comparative Insight: Lakehouse vs. Traditional Data Architectures
To fully appreciate the innovation of the Lakehouse Architecture, it’s essential to understand how it contrasts with the more traditional data management paradigms: the Data Lake and the Data Warehouse. Historically, organizations often maintained separate systems:
- Traditional Data Lake: Designed for storing vast amounts of raw, multi-structured data at low cost. It offers immense flexibility and scalability but lacks transactional capabilities, schema enforcement, and robust data governance. This often leads to “data swamps” where data quality is poor, and finding reliable information for analytics is challenging. Its strength lies in handling diverse data for exploratory analysis and machine learning, but it struggles with traditional business intelligence (BI) workloads requiring high data consistency.
- Traditional Data Warehouse: Optimized for structured, clean, and pre-processed data, supporting complex SQL queries and BI reporting with strong ACID compliance and schema-on-write principles. Data warehouses excel at providing reliable, historical insights but are typically expensive, less flexible with new data types, and struggle with the scale and variety of raw data required for modern AI and machine learning initiatives. They are often burdened by rigid schemas and high latency for real-time data ingestion.
The Data Lakehouse bridges this gap by marrying the best features of both. It maintains the cost-effectiveness and schema flexibility of a data lake, allowing for the storage of all data—structured, semi-structured, and unstructured—in open formats on cloud object storage. Crucially, it then layers on the reliability, performance, and strong governance features of a data warehouse through its transactional layer. This means:
- Unified Platform: Instead of managing two separate systems, the Lakehouse provides a single source of truth for all analytical and machine learning workloads. This eliminates data duplication, simplifies ETL pipelines, and reduces operational complexity.
- ACID Transactions on Data Lakes: This is a game-changer. It allows for reliable data updates, deletions, and inserts directly on the data lake, ensuring data consistency and integrity for critical BI reports and regulatory compliance, something traditional data lakes could not guarantee.
- Schema Enforcement & Evolution: The Lakehouse offers the flexibility of schema-on-read (like data lakes) for raw ingestion but also supports schema enforcement (like data warehouses) for curated data, enabling reliable analytics while adapting to evolving data structures.
- Cost Efficiency & Scalability: It leverages inexpensive cloud object storage for massive datasets while offering performance comparable to data warehouses through optimized query engines and metadata layers.
- Enhanced AI/ML Integration: The Lakehouse natively supports AI and machine learning workloads by providing direct access to raw, un-transformed data for model training and feature engineering, all within a governed and reliable environment. Data scientists no longer need to move data between different platforms.
In essence, while traditional architectures force a compromise between flexibility and reliability, the Data Lakehouse offers a “have your cake and eat it too” solution, delivering a superior platform for modern data analytics and machine learning at scale.
World2Data Verdict: Embracing the Data Lakehouse for Future Readiness
The evolution of data architecture is not merely about incremental improvements; it’s about fundamental shifts that empower businesses to extract unprecedented value from their data. The Lakehouse Architecture represents such a paradigm shift, moving beyond the limitations of fragmented data silos to offer a truly unified, scalable, and governed platform. World2Data.com believes that the Data Lakehouse is not just a trend but a strategic imperative for organizations aiming to remain competitive in a data-intensive world. Its ability to seamlessly blend the best aspects of data lakes and data warehouses, providing ACID transactions on open formats within affordable object storage, makes it an ideal foundation for all modern analytics workloads, from traditional BI to advanced AI and machine learning. We strongly recommend that enterprises thoroughly evaluate and strategically invest in adopting a Lakehouse approach, as it promises to future-proof their data infrastructure, simplify operations, and accelerate their journey towards becoming truly data-driven organizations.

{kind=link}