


Unlocking Agility: The Data Lakehouse and its Pivotal Role in Digital Transformation
- Platform Category:
- Data Warehouse and Data Lake Hybrid
- Core Technology/Architecture:
- Open Architecture with ACID Transactions on Data Lakes
- Key Data Governance Feature:
- Unified Data Catalog with Schema Enforcement and Time Travel
- Primary AI/ML Integration:
- Direct access for ML frameworks on a single copy of data
- Main Competitors/Alternatives:
- Traditional Data Warehouse, Data Lake
The conversation around the Data Lakehouse and its Role in Digital Transformation is becoming an essential one for modern enterprises. As organizations navigate the complexities of their digital journeys, the ability to effectively manage, process, and derive insights from vast amounts of diverse data is no longer optional—it’s foundational. The Data Lakehouse architecture emerges as a pivotal solution, adept at unifying the strengths of traditional data lakes and data warehouses to accelerate critical digital initiatives and drive unparalleled business value.
This innovative architectural paradigm promises to dismantle data silos, streamline analytics workflows, and empower advanced AI and machine learning applications. By bridging the historical divide between flexibility and structure, the Data Lakehouse offers a robust, scalable, and cost-efficient foundation for any organization striving for true digital mastery. It’s a strategic imperative for those looking to convert raw data into actionable intelligence at speed and scale.
Introduction: The Imperative of Data-Driven Digital Transformation
In today’s hyper-competitive global landscape, digital transformation is not merely an IT project; it’s a fundamental shift in how businesses operate, interact with customers, and innovate. At the heart of successful digital transformation lies an organization’s ability to leverage data effectively. However, the traditional dichotomy between data lakes and data warehouses has often presented a significant impediment. Data lakes offer unparalleled flexibility for storing raw, diverse data at scale but often lack the structure, governance, and performance required for robust analytical workloads. Conversely, data warehouses provide strong schema enforcement and high-performance querying for structured data but struggle with scalability, cost-efficiency for massive datasets, and flexibility for unstructured or semi-structured data essential for AI/ML.
This is precisely where the Data Lakehouse architecture steps in, offering a transformative solution. It represents a convergence, inheriting the best attributes of both worlds: the vast, cost-effective storage and flexibility of a data lake combined with the transactional capabilities, schema enforcement, data governance, and performance of a data warehouse. For enterprises embarking on or accelerating their digital transformation journeys, the Data Lakehouse provides a unified, open, and future-proof platform. Its objective is clear: to simplify the data stack, reduce complexity, enhance data quality, and accelerate the journey from raw data to actionable insights, thereby directly fueling the core objectives of digital transformation.
Core Breakdown: Architecture, Challenges, and Business Value of the Data Lakehouse
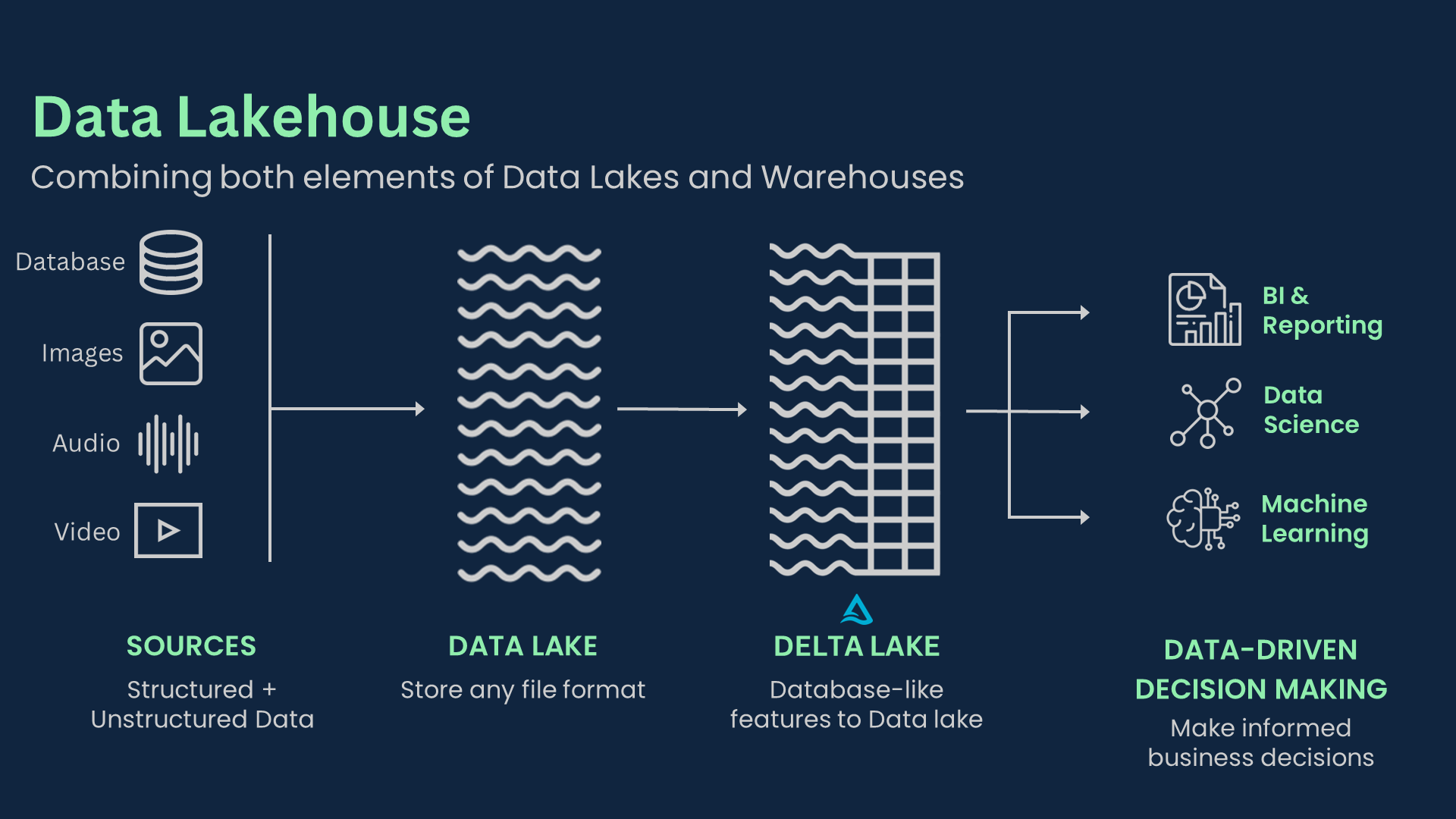
The fundamental innovation of the Data Lakehouse lies in its ability to bring data warehousing capabilities directly to a data lake. This is primarily achieved through the use of open table formats like Delta Lake, Apache Iceberg, or Apache Hudi. These formats extend standard data lake files (e.g., Parquet, ORC) with crucial features such as ACID (Atomicity, Consistency, Isolation, Durability) transactions, schema enforcement, schema evolution, time travel, and data versioning. This means that data stored in a cost-effective object storage (like Amazon S3, Azure Data Lake Storage, or Google Cloud Storage) can now support reliable, concurrent reads and writes, ensuring data integrity for both batch and streaming workloads, a critical element for any robust AI Data Platform.
Bridging the Divide: Unifying Data Architectures is a core advantage of the Data Lakehouse. Historically, companies struggled with fragmented data ecosystems, where data lakes offered raw storage flexibility but lacked structure for analytics, and data warehouses provided robust analytics but with less flexibility. The Lakehouse elegantly combines these, providing schema enforcement, transaction support, and data governance directly on open format data stored in a data lake. This unified approach simplifies data pipelines, enhances data reliability, and creates a single source of truth for all data consumers, from business analysts to data scientists and machine learning engineers. This eliminates the need for complex ETL processes to move data between disparate systems, reducing latency and operational overhead.
Challenges and Barriers to Adoption
While the benefits of the Data Lakehouse are compelling, its adoption is not without hurdles. One significant challenge lies in the **migration of existing data ecosystems**. Organizations with deeply entrenched legacy data warehouses or complex data lake setups may face substantial effort and expertise requirements to transition to a Lakehouse architecture. This often involves re-evaluating existing data pipelines, re-platforming analytics tools, and upskilling data teams.
Another barrier is **data governance and security in a unified environment**. While Lakehouses offer features like schema enforcement and data catalogs, implementing comprehensive data governance, access controls, and compliance across diverse data types and consumption patterns can be complex. Ensuring consistent data quality, managing evolving schemas, and preventing data drift in a dynamic environment demands robust MLOps practices and continuous monitoring, areas where many organizations are still maturing.
The **skill gap** also poses a challenge. While open-source technologies underpin many Lakehouse solutions, there’s a learning curve for data engineers and architects to master these new paradigms, especially around optimizing performance for varied workloads and managing the underlying infrastructure efficiently. Finally, **cost optimization** in a cloud-native Lakehouse environment requires careful planning to balance storage and compute resources, as misconfigurations can lead to unexpected expenses.
Business Value and ROI
Empowering Analytics and AI with Lakehouse capabilities fuels advanced innovation. By offering a single source of truth that supports both batch and real-time processing, the Data Lakehouse becomes the ideal foundation for machine learning, artificial intelligence, and sophisticated business intelligence tools. This enables faster development of AI models, more accurate predictive analytics, and empowers data scientists to access clean, curated data directly for their projects without complex data movement. The direct access to raw and curated data for ML frameworks significantly accelerates the MLOps lifecycle, from feature engineering to model deployment and monitoring. The ability to perform data labeling and feature engineering on the same platform where data resides dramatically reduces time-to-market for new data products and AI-powered services.
Scalability and Cost-Efficiency for Modern Enterprises are inherent benefits of adopting a Data Lakehouse. Built on scalable cloud storage and open source technologies, Lakehouses offer immense flexibility to scale compute and storage independently, significantly reducing infrastructure costs compared to monolithic data warehouse solutions. This cost-effectiveness, combined with the ability to handle diverse data types and volumes (structured, semi-structured, unstructured), makes it an attractive investment for businesses seeking to modernize their data strategy without prohibitive expenses. Organizations can pay for compute only when needed and leverage inexpensive object storage for petabytes of data, leading to a much lower Total Cost of Ownership (TCO) over time.
Accelerating Digital Transformation Initiatives is the ultimate impact of the Data Lakehouse. It provides the agility, performance, and governance needed to drive innovation, improve customer experiences, and unlock new business opportunities. Companies can make faster, more informed decisions, develop new data products quickly, and adapt to market changes with unparalleled speed. The Data Lakehouse is not just a technology; it is a strategic enabler for organizations aiming to truly thrive in today’s data-driven world, providing the robust data foundation necessary to implement real-time analytics, personalization engines, and predictive maintenance solutions that define modern digital enterprises.
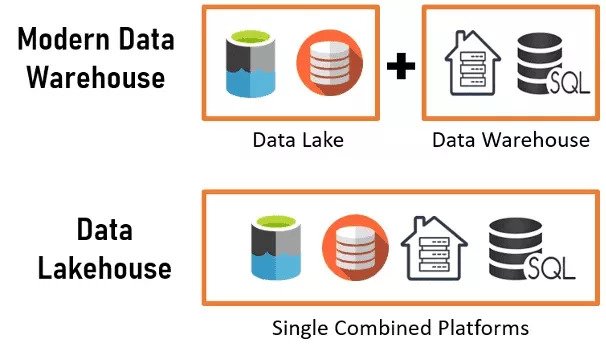
Comparative Insight: Data Lakehouse vs. Traditional Data Systems
To fully appreciate the significance of the Data Lakehouse, it’s crucial to understand its distinctions from its predecessors: the traditional data lake and the conventional data warehouse. Each architecture emerged to solve specific data challenges, but the Data Lakehouse represents an evolution that addresses their combined limitations, particularly in the context of rapid digital transformation.
Traditional Data Lake
A data lake is essentially a vast storage repository that holds raw data in its native format until it’s needed. It’s highly flexible, cost-effective for storing massive volumes of diverse data (structured, semi-structured, unstructured), and ideal for big data analytics, machine learning, and exploratory data science. However, data lakes traditionally lack critical features like schema enforcement, transactional consistency (ACID properties), and robust data governance. This often leads to “data swamps” – unmanaged lakes where data quality is poor, and finding relevant, trustworthy information becomes a monumental task. Querying performance for structured, repetitive analytical tasks can also be suboptimal without significant optimization.
Traditional Data Warehouse
A data warehouse, on the other hand, is designed for highly structured, cleaned, and transformed data. It excels at complex SQL queries, business intelligence (BI), and reporting, offering high performance and strong data integrity through predefined schemas and ACID properties. Data warehouses are the backbone of operational analytics. Yet, their rigidity makes them less suitable for unstructured data, real-time analytics, or the iterative, experimental nature of machine learning. They can also be expensive to scale, especially for petabyte-scale data volumes, and require extensive ETL processes to load data, leading to latency and higher operational costs.
The Data Lakehouse Difference
The Data Lakehouse bridges this gap by marrying the best of both worlds. It offers:
- Unified Storage: Uses inexpensive cloud object storage, similar to a data lake, for all data types.
- ACID Transactions: Brings transaction support directly to the data lake, ensuring data reliability and consistency, which was traditionally exclusive to data warehouses.
- Schema Enforcement & Evolution: Provides mechanisms for defining and evolving schemas directly on the data lake, enabling data quality and governance without sacrificing flexibility.
- Unified Processing: Supports both batch and streaming data processing on the same data, eliminating the need for separate systems for real-time and historical analysis.
- Open Formats: Built on open data formats (e.g., Parquet with Delta Lake, Iceberg, Hudi) preventing vendor lock-in and promoting interoperability with various analytical engines.
- Performance: Delivers optimized query performance for analytical workloads, comparable to data warehouses, while also supporting exploratory data science and machine learning directly on raw data.
This convergence means organizations no longer need to choose between flexibility and structure, or between cost-efficiency and performance. The Data Lakehouse provides a single platform for all data needs, simplifying architecture, reducing data movement, and significantly accelerating the journey from raw data ingestion to advanced analytics and AI applications. This foundational shift is what makes it an indispensable component for any organization seriously pursuing a data-driven digital transformation strategy.
World2Data Verdict: Embracing the Future of Unified Data Platforms
The rise of the Data Lakehouse is not merely a technological trend; it’s a strategic imperative for organizations aiming to truly leverage data as a competitive advantage in their digital transformation journeys. World2Data believes that the Data Lakehouse represents the future of enterprise data architecture, providing an unparalleled blend of flexibility, governance, performance, and cost-efficiency. Its ability to unify diverse data workloads—from raw data ingestion and feature engineering to advanced analytics and machine learning—on a single, open platform dramatically simplifies the data landscape and accelerates innovation. For businesses struggling with data silos, high infrastructure costs, or the complexity of managing disparate data systems for AI, the Data Lakehouse offers a clear, actionable path forward.
Our recommendation is for organizations to strategically evaluate and adopt Data Lakehouse architectures as the cornerstone of their modern data strategy. Focus on solutions built on open-source foundations (like Delta Lake, Apache Iceberg, or Apache Hudi) to ensure future-proofing and avoid vendor lock-in. Prioritize investing in the necessary skills and MLOps practices to effectively manage data quality, governance, and schema evolution within this unified environment. The Data Lakehouse isn’t just about combining technologies; it’s about fostering a culture of data-driven decision-making and innovation that is agile enough to navigate the complexities of the digital age. Embracing this paradigm is key to unlocking the full potential of your data and securing a resilient, innovative future.

{kind=link}