


Data Lineage Explained: Tracking Data from Source to Destination for Enhanced Data Governance and AI Trust
Platform Category: Data Governance Capability
Core Technology/Architecture: Metadata management, graph-based data models, automated code parsing (SQL, ETL scripts)
Key Data Governance Feature: Transparency, compliance (GDPR, CCPA), root cause analysis, impact analysis for data changes
Primary AI/ML Integration: Automated lineage discovery using ML, understanding data flow for MLOps pipelines, auditing data used in ML models
Main Competitors/Alternatives: Data catalog tools (e.g., Collibra, Alation), metadata management platforms (e.g., Informatica Enterprise Data Catalog), ETL/ELT tools with lineage features (e.g., Talend, Azure Data Factory), custom scripting solutions
In today’s hyper-connected, data-driven landscape, understanding the journey of information from its origin to its final resting place is paramount. Data Lineage Explained: Tracking Data from Source to Destination is increasingly vital, moving from a niche concern to a foundational pillar of modern data strategy. This comprehensive article delves into the intricacies of data lineage, revealing how it underpins data governance, ensures regulatory compliance, and fuels reliable AI and machine learning initiatives by providing unparalleled transparency into data flows.
Introduction: The Imperative of Understanding Your Data’s Journey
The vast oceans of data generated daily are invaluable assets, yet their true potential can only be unlocked when their integrity and provenance are beyond doubt. This is precisely where the concept of Data Lineage steps in, offering a complete, documented, and often visual pathway of data’s lifecycle. From the moment data is created or ingested to its myriad transformations and eventual consumption, data lineage charts every step. It’s not merely about knowing where data resides, but understanding its entire evolutionary history, including who touched it, when, and how it changed. For organizations navigating complex data ecosystems and facing stringent regulatory demands, robust data lineage capabilities are no longer a luxury but a strategic necessity.
This deep dive will clarify the mechanisms behind effective data lineage, explore its practical applications across various business functions, and highlight its critical role in maintaining data quality, ensuring compliance, and building trust in the insights derived from data, especially for advanced analytics and artificial intelligence applications. Without a clear understanding of data lineage, decision-making becomes opaque, and the risk of misinterpretation or errors escalates dramatically.
Core Breakdown: Unpacking the Architecture and Value of Data Lineage
Data Lineage, at its core, is the ability to reconstruct the path of data, mapping its journey from origin to consumption. This involves a sophisticated interplay of technical and methodological components that work in concert to provide a holistic view. Defining Data Lineage is simply charting the complete lifecycle of data, from its inception to its current state. It provides a visual and documented path, revealing every transformation and movement. The Imperative for Data Transparency has never been greater, as businesses rely on accurate and traceable information for critical decisions.
The Mechanics of Tracking Data Flow
The process behind comprehensive data lineage relies on several foundational technologies and practices:
- Metadata Management: This is the bedrock of any robust lineage solution. Metadata — data about data — provides contextual information about data elements, their definitions, relationships, and technical characteristics. Modern lineage tools automatically collect metadata from diverse sources, including databases, data warehouses, data lakes, ETL tools, BI reports, and custom applications. This metadata is then cataloged and stored, forming a knowledge graph that describes the entire data landscape.
- Graph-Based Data Models: Representing data lineage effectively often requires graph databases or graph-based modeling. Unlike relational databases, graphs are exceptionally adept at showing relationships between entities (nodes) and the connections (edges) that link them. In data lineage, data assets, transformation processes, and systems become nodes, while the flow of data between them forms the edges, allowing for intuitive and efficient querying and visualization of complex data paths.
- Automated Code Parsing (SQL, ETL Scripts, etc.): A significant portion of data transformation occurs within code — SQL scripts, stored procedures, ETL jobs (e.g., Informatica, Talend, DataStage), Python scripts for data science, and even BI report definitions. Advanced data lineage solutions employ parsers that can automatically scan and interpret this code, identifying input sources, output destinations, and the specific transformations applied (e.g., joins, aggregations, filtering, calculations). This automation is crucial for scalability, as manual mapping of such intricate code is often impractical.
- Data Transformation Logging: Beyond parsing static code, operational lineage often requires capturing real-time or near real-time logs of data processing. This ensures that dynamic transformations, data quality rule applications, or incremental loads are also recorded, providing a more granular and up-to-the-minute view of data changes.
- Data Labeling and Tagging: For compliance and specific use cases like AI model training, data labeling and tagging become crucial. Data lineage integrates with these practices by allowing labels (e.g., PII, sensitive, financial data) to persist or transform along with the data flow. This ensures that even after multiple transformations, the original data’s sensitivity or classification is still traceable, aiding in access control and regulatory adherence.
Challenges and Barriers to Adoption
Despite its undeniable benefits, implementing effective Data Lineage can face significant hurdles:
- Complexity of Enterprise Data Ecosystems: Modern organizations often have a sprawling landscape of legacy systems, cloud-native services, diverse databases, data lakes, streaming platforms, and countless ETL jobs. Tracing data through such a heterogeneous and dynamic environment is inherently complex.
- Manual Effort and Resource Intensity: Without robust automation, mapping data lineage across an entire enterprise can be an arduous, time-consuming, and error-prone manual task requiring specialized skills. This can quickly deplete resources and become unsustainable.
- Lack of Standardization: Different teams, departments, or even individual developers may use varying naming conventions, coding styles, or data integration patterns, making automated parsing and consistent lineage mapping challenging.
- Dynamic Data Environments: Data schemas, transformation logic, and data pipelines are constantly evolving. Maintaining up-to-date data lineage in such dynamic environments requires continuous monitoring and re-discovery, which many tools struggle to provide seamlessly.
- Legacy Systems Integration: Older systems often lack the APIs or metadata layers necessary for automated lineage extraction, necessitating custom connectors or manual intervention.
- MLOps Complexity and Data Drift: For AI and ML models, lineage extends to tracking features, model versions, training data, and inference data. This adds another layer of complexity, especially in detecting and attributing data drift – where changes in upstream data sources impact model performance. Without clear lineage, understanding the root cause of drift is incredibly difficult, hindering MLOps efficiency.
- Cost of Specialized Tools: Comprehensive data lineage solutions can be expensive, both in terms of licensing and implementation, posing a barrier for smaller organizations or those with limited budgets.
Business Value and ROI
The return on investment (ROI) from a well-implemented Data Lineage solution is multi-faceted and significant:
- Ensuring Regulatory Compliance: This is a primary driver for robust Data Lineage practices. Regulations like GDPR, CCPA, HIPAA, BCBS 239, and industry-specific mandates demand clear accountability for data usage and proof of data integrity. Lineage provides the audit trails necessary to demonstrate compliance, avoiding hefty fines and reputational damage.
- Boosting Data Quality and Trust: By identifying data origins and transformations, organizations can pinpoint potential points of data corruption or inconsistency. This visibility enables proactive measures to improve data quality, leading to greater trust in data-driven insights.
- Expediting Problem Resolution: When data errors occur, Data Lineage helps swiftly identify the root cause, whether it’s a faulty ETL script, an incorrect data source, or a misconfigured transformation. This dramatically reduces the mean time to resolution, saving time and resources.
- Facilitating Impact Analysis for Data Changes: Before making changes to a data source, schema, or transformation logic, data lineage allows stakeholders to understand all downstream systems, reports, and AI models that would be affected. This minimizes disruption and allows for informed decision-making.
- Empowering MLOps and AI Development: For AI and machine learning, data lineage is critical for model explainability, reproducibility, and auditing. It allows data scientists and MLOps engineers to track the exact data used to train a model, understand feature derivation, and diagnose model performance issues by tracing back to the input data. This accelerates model deployment and ensures ethical AI practices.
- Streamlining Data Governance: Lineage serves as a cornerstone for effective data governance programs, providing the transparency needed for data stewardship, ownership assignment, and policy enforcement across the data lifecycle.
- Improving Business Agility and Decision Making: With transparent data flows, business users and analysts can confidently use data, understand its context, and make faster, more reliable decisions. This fosters innovation and enhances competitive advantage.
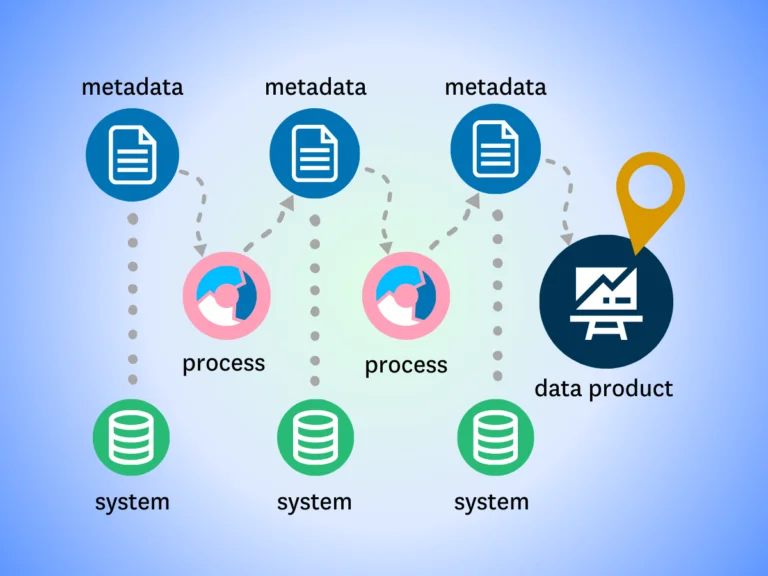
Visualizing the complex journey of data across an organization’s ecosystem is made possible through robust data lineage tools.
Comparative Insight: Data Lineage in Traditional vs. AI Data Platforms
The approach to Data Lineage has evolved significantly, particularly with the advent of modern AI Data Platforms, which offer a stark contrast to how lineage was traditionally handled in mere Data Lakes or Data Warehouses.
Traditional Data Lakes and Data Warehouses
In the era of traditional data warehousing and early data lakes, data lineage was often an afterthought, or a cumbersome manual exercise. Organizations might employ:
- Manual Documentation: Excel spreadsheets, confluence pages, or internal wikis were common, requiring significant manual effort to keep updated. This approach was prone to errors, quickly outdated, and struggled with scale.
- Fragmented Tools: Lineage might be scattered across various ETL tools, database metadata, and BI report definitions, with no single, unified view. Connecting these disparate pieces was a major challenge.
- Reactive Problem Solving: Lineage was typically invoked only when a data quality issue arose or an audit required it, making it a reactive rather than a proactive measure.
- Limited Scope: Focus often remained on structured data within the data warehouse, overlooking the vast unstructured and semi-structured data in data lakes, or the complex transformations happening outside the ETL pipeline.
- Weak AI/ML Integration: Lineage for machine learning features, training datasets, and model outputs was virtually non-existent or completely manual, hindering MLOps initiatives and increasing the risk of “black box” models.
Modern AI Data Platforms with Integrated Data Lineage
A modern AI Data Platform fundamentally shifts the paradigm for data lineage. These platforms are designed from the ground up to support end-to-end data lifecycle management, with lineage as an integral, automated capability:
- Automated and Real-time Discovery: AI Data Platforms leverage advanced ML techniques and robust parsing engines to automatically discover and map lineage across all data assets – structured, semi-structured, and unstructured – including data in lakes, warehouses, streaming platforms, APIs, and feature stores. This often happens continuously, adapting to schema changes and new pipelines.
- Holistic View with Graph Models: These platforms typically employ graph databases to store and represent lineage, offering a single, unified, and interactive view of data flow from raw ingestion to AI model deployment and operational dashboards. This includes tracing lineage through feature engineering pipelines within dedicated Feature Stores.
- Proactive Governance and Impact Analysis: Integrated lineage enables proactive data governance. Data stewards can identify data ownership, apply policies, and perform comprehensive impact analysis before any changes are made to upstream data sources or transformation logic.
- Deep MLOps Integration: For AI, lineage is extended to track specific features used in models, the datasets these features were derived from, the exact version of the model trained, and the inference data. This is crucial for model explainability, debugging, bias detection, and ensuring the reproducibility of AI outputs. It helps identify if data drift is occurring at the source, during transformation, or within the feature engineering process.
- Enhanced Data Quality and Trust for AI: By providing complete transparency into the data’s journey, AI Data Platforms foster greater trust in the data used to train and operate AI models. This directly contributes to more reliable AI outcomes and faster iteration cycles for data scientists.
- Self-Service and Collaboration: Modern platforms often provide intuitive UIs that allow various stakeholders – data engineers, data scientists, business analysts, and compliance officers – to explore data lineage easily, fostering better collaboration and data literacy across the organization.
In essence, while traditional approaches treated lineage as a burdensome, manual task, AI Data Platforms embed it as an automated, intelligent, and foundational capability, transforming it into a powerful enabler for trusted data and reliable AI.
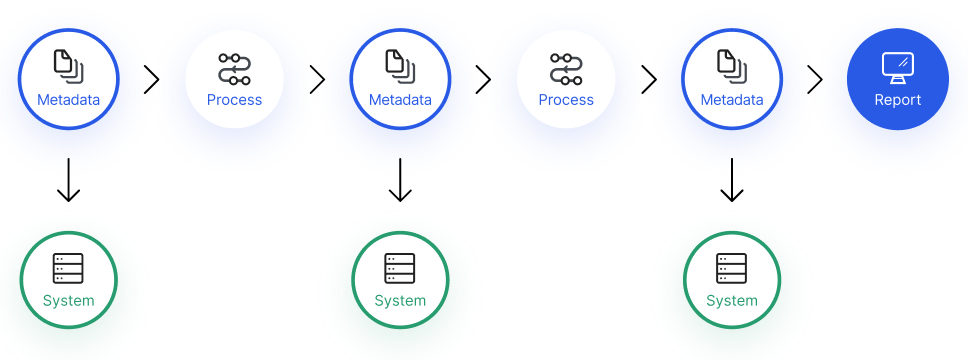
An example of end-to-end data lineage, detailing transformations and data flow across systems.
World2Data Verdict: The Indispensable Compass for Data Integrity and AI Trust
The World2Data perspective on Data Lineage is unequivocal: it is no longer merely a “nice-to-have” feature but a critical, non-negotiable component of any robust data strategy, especially for organizations leveraging AI and advanced analytics. As data ecosystems grow in complexity and regulatory pressures intensify, the ability to instantly and accurately trace data from source to destination becomes the bedrock of data integrity and business trust. For enterprises aiming to unlock the full potential of their data, particularly in driving reliable AI outcomes, investing in automated, comprehensive data lineage solutions is paramount.
Our recommendation is clear: organizations must prioritize the implementation of platforms that embed intelligent, automated data lineage capabilities. This includes leveraging tools that integrate seamlessly with metadata management, graph databases, and MLOps pipelines to provide end-to-end visibility. The future of data-driven decision-making, regulatory compliance, and ethical AI development hinges on absolute transparency into data’s provenance and transformations. Without a clear compass like robust data lineage, navigating the vast and often turbulent seas of enterprise data will inevitably lead to costly errors, compliance failures, and a profound erosion of trust in the very data intended to drive innovation.

{kind=link}