


Data Mesh: Revolutionizing Data Management with a Decentralized Approach
The landscape of enterprise data management is undergoing a profound transformation, driven by the escalating demands for agility, scalability, and domain-specific data insights. Data Mesh represents a groundbreaking architectural and organizational paradigm that addresses the inherent limitations of traditional centralized data platforms. By championing decentralization, domain ownership, and a “data as a product” mindset, Data Mesh promises to unlock unprecedented value from an organization’s data assets, paving the way for more robust and responsive data strategies.
Introduction: Reshaping Data Paradigms with Data Mesh
In the digital era, data is the lifeblood of innovation and competitive advantage. Yet, many organizations find themselves grappling with monolithic data architectures like centralized data lakes and data warehouses, which, while foundational, often create bottlenecks, hinder agility, and struggle to keep pace with the sheer volume and diversity of modern data. These traditional models can lead to data swamps, slow time-to-insight, and a lack of clear ownership, making it challenging to leverage data effectively, especially for advanced analytics and Artificial Intelligence (AI).
Enter the Data Mesh – an architectural paradigm that fundamentally shifts how data is managed, organized, and consumed. Unlike its centralized predecessors, Data Mesh advocates for a decentralized, domain-oriented approach. Its core philosophy revolves around treating data not as a passive byproduct, but as a first-class product, developed and owned by the business domains that understand it best. This transformative approach is characterized by four foundational principles: domain-oriented ownership, data as a product, a self-serve data platform, and federated computational governance. World2Data.com delves into this innovative framework, exploring its core tenets, profound benefits, inherent challenges, and its pivotal role in shaping the future of enterprise data management, particularly for driving sophisticated AI and Machine Learning (ML) initiatives.
Core Breakdown: Unpacking the Data Mesh Architecture and Principles
The Data Mesh is more than just a technical architecture; it’s a socio-technical shift that impacts organizational structure, culture, and processes. Its efficacy stems from its four pillars, each designed to address the systemic challenges of centralized data management.
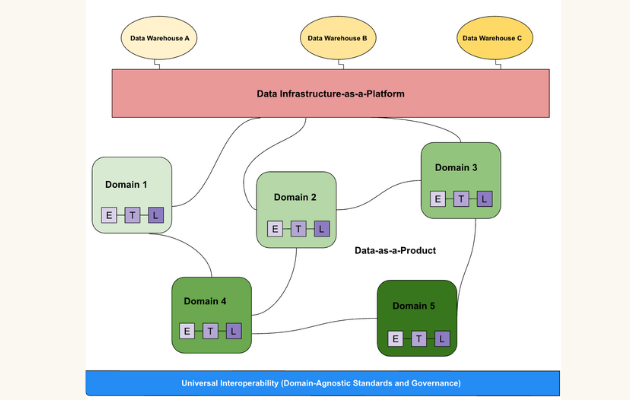
Domain-Oriented Data Ownership
At the heart of Data Mesh lies the principle of domain-oriented ownership. Instead of a central data team managing all data, responsibility is distributed to the individual business domains (e.g., Sales, Marketing, Finance, Product Development) that generate or consume specific data sets. These domains are empowered to become data providers, responsible for the entire lifecycle of their data products – from ingestion to serving.
- Empowering Business Units: By placing data ownership directly with the domain experts, the context and nuances of the data are retained and leveraged. This proximity to the data’s origin and primary use cases ensures a deeper understanding of its meaning, quality, and potential applications.
- Improving Data Quality and Discoverability: When a domain team is accountable for its data product, there’s a strong incentive to ensure its quality, accuracy, and completeness. This approach naturally fosters better data governance at the source, leading to more trustworthy and reliable data. Furthermore, domain teams are best positioned to document and describe their data products, making them highly discoverable and understandable for potential consumers across the organization.
Data as a Product Mindset
The second pillar dictates that data must be treated as a product, designed with the consumer in mind. This means data is not merely raw information but a curated, well-defined, and easily consumable asset. Each data product must meet certain quality attributes:
- Discoverable: Easily found and understood through metadata and catalogs.
- Addressable: Accessible via standardized interfaces and APIs.
- Trustworthy: Reliable, accurate, and with clear lineage and quality metrics.
- Self-describing: Contains rich metadata that explains its structure, semantics, and usage.
- Secure: Adheres to organizational security and privacy policies.
- Interoperable: Designed to be easily integrated and used by other data products or applications.
This mindset transforms data producers into product owners, fostering a customer-centric approach to data provision and significantly improving the overall data consumer experience. This is crucial for enabling advanced analytics and robust AI Data Platform capabilities, as high-quality, reliable data is the fundamental input for successful machine learning models.
Self-Serve Data Infrastructure
To enable domain teams to autonomously create, manage, and evolve their data products, a foundational self-serve data platform is essential. This platform provides the necessary tools, capabilities, and infrastructure-as-code to reduce the cognitive load on domain teams, allowing them to focus on data product development rather than operational complexities. It offers abstracted capabilities for:
- Data Ingestion and Transformation: Tools for connecting to various data sources and transforming data into desired formats.
- Data Storage and Serving: Standardized ways to store and expose data products (e.g., APIs, message queues, databases).
- Data Governance and Monitoring: Built-in mechanisms for applying global governance policies, monitoring data quality, and tracking lineage.
- Security and Compliance: Automated enforcement of security protocols and regulatory compliance.
This democratization of data access and tools empowers domain teams to operate independently, accelerating data product development and reducing reliance on central bottleneck teams. It’s a critical component for scaling a decentralized data management strategy and supports agile development workflows akin to effective MLOps practices.
Federated Computational Governance
While decentralization is key, anarchy is not the goal. Federated computational governance strikes a balance between domain autonomy and global interoperability. A small, central governance team defines global policies (e.g., data privacy, security, interoperability standards, data contract formats), but the enforcement and implementation of these policies are distributed and automated within the self-serve data platform and by the domain teams themselves. This ensures consistency and trust across the entire mesh without stifling innovation or creating new bottlenecks.
- Balancing Autonomy with Standards: Domain teams have the freedom to innovate within their boundaries, but they must adhere to common standards and protocols defined at the federation level. This prevents data silos from becoming isolated islands of data.
- Ensuring Interoperability and Security: Automated governance ensures that all data products are secure, compliant, and can seamlessly interact with each other, forming a cohesive data ecosystem. This is vital for complex analytics and cross-domain AI initiatives.
Challenges and Barriers to Data Mesh Adoption
Despite its promise, implementing a Data Mesh is not without its hurdles. It represents a significant organizational and technical undertaking that requires careful planning and execution.
- Organizational and Cultural Shift: Perhaps the most significant barrier is the necessary cultural transformation. Shifting from a centralized mindset to one of distributed ownership and accountability requires buy-in from leadership and extensive training for teams. New roles and responsibilities must be defined, and established silos need to be broken down. This change management aspect is often underestimated.
- Initial Investment and Complexity: Building a robust self-serve data platform and transitioning existing data assets into data products demands substantial upfront investment in technology, tools, and skilled personnel. The initial setup can be complex, requiring expertise in distributed systems, API design, and automated governance.
- Data Consistency and Interoperability: While federated governance aims to standardize, ensuring absolute data consistency and seamless interoperability across numerous, independently managed data products can be challenging. Defining and enforcing effective data contracts becomes paramount to prevent fragmentation and maintain a coherent view of organizational data.
- Managing Data Drift: Even with domain ownership, data drift—changes in data schema, semantics, or distribution over time—remains a persistent challenge. While domains are responsible for their data products, identifying and communicating upstream changes to dependent consumers requires robust monitoring and communication channels within the mesh.
- MLOps Complexity in a Decentralized Landscape: While Data Mesh provides high-quality, reliable data products that feed into MLOps pipelines, integrating and orchestrating MLOps workflows across multiple, distributed data products introduces its own layer of complexity. Managing model versions, feature stores (which benefit greatly from data mesh’s reliable data products), and deployment across data products demands sophisticated automation and robust data contracts.
Business Value and Return on Investment (ROI)
Overcoming these challenges yields substantial benefits, making the investment in Data Mesh a strategic imperative for many enterprises.
- Enhanced Agility and Faster Time-to-Market: By decentralizing data ownership and enabling self-serve capabilities, organizations can dramatically accelerate the development and deployment of new data products and analytical insights. Business units can respond to market changes and create innovative solutions much faster.
- Improved Data Quality and Trust: Domain experts, being closest to the data, are intrinsically motivated to ensure its quality. This leads to more reliable and trustworthy data products, which is critical for making informed business decisions and building accurate AI models.
- Scalability and Resilience: A decentralized architecture inherently offers greater scalability, as individual domains can evolve their data products independently without impacting the entire system. It also enhances resilience by reducing single points of failure.
- Fostering Innovation and Data Democratization: Empowering diverse teams with accessible, high-quality data products sparks innovation. Data democratization allows more employees to leverage data for problem-solving, leading to a data-driven culture.
- Enabling Advanced AI/ML Initiatives: Perhaps most significantly, Data Mesh provides the foundational infrastructure for a robust AI Data Platform. The “data as a product” approach ensures that ML engineers and data scientists have access to discoverable, reliable, and high-quality data products. These can then seamlessly feed into Feature Store solutions, accelerating feature engineering and management, ultimately leading to faster model deployment and more accurate, explainable AI models.
Comparative Insight: Data Mesh vs. Traditional Data Architectures
To truly appreciate the transformative potential of Data Mesh, it’s crucial to understand how it contrasts with established data management paradigms.
Traditional Data Lake and Data Warehouse
For decades, the central data warehouse served as the single source of truth, typically housing structured data optimized for reporting and business intelligence. With the explosion of diverse data types and volumes, the data lake emerged, offering scalable storage for raw, unstructured, and semi-structured data. While both have their merits, they share a fundamental flaw when scaled: a centralized, monolithic architecture and ownership model.
- Centralized Ownership & Bottlenecks: In these models, a single, often overworked, central data team is responsible for ingesting, transforming (ETL/ELT), and serving all data. This creates bottlenecks, slows down data delivery, and leads to a lack of agility as business units must constantly petition the central team for new data needs.
- Limited Agility & Scalability: Changes to data schema or the addition of new data sources often require complex, time-consuming adjustments to the central pipeline, hindering rapid iteration. Scaling a single, massive data platform to meet the needs of an entire enterprise becomes technically challenging and inefficient.
- Data Quality & Context Issues: As data moves further away from its source and original domain, contextual information can be lost, and quality issues might not be identified or addressed effectively by a distant central team. This often leads to “data swamps” in data lakes, where raw data is stored but becomes difficult to use or trust.
Data Mesh’s Distinctive Advantages
Data Mesh directly addresses these limitations by flipping the script:
- Decentralized Ownership: Instead of a central team, domain teams own and manage their data as products. This eliminates the central bottleneck and ensures data is managed by those with the most context.
- Data as a Product: Data is not just stored; it’s meticulously curated, documented, and served as a high-quality product with clear APIs and service level objectives (SLOs), fostering trust and discoverability.
- Self-Serve Capabilities: The underlying platform empowers domain teams, reducing reliance on central specialists for every operational task. This significantly boosts agility and accelerates time-to-value for data initiatives.
- Federated Governance: While decentralized, Data Mesh isn’t anarchic. Global policies ensure interoperability, security, and compliance across all data products, maintaining a cohesive enterprise data landscape.
Comparison with Data Lakehouse Architecture
The “data lakehouse” architecture attempts to bridge the gap between the flexibility of data lakes and the ACID transactions and structure of data warehouses. It often involves using technologies like Delta Lake, Apache Iceberg, or Apache Hudi on top of a data lake to bring data warehousing capabilities (e.g., schema enforcement, transactions, data versioning) to the raw data store. While a significant improvement over standalone data lakes, the data lakehouse often retains a relatively centralized ownership model.
- Centralized vs. Decentralized: A data lakehouse typically implies a single, albeit more flexible, data platform. While it might allow for some internal segmentation or virtualized views, the underlying ownership and operational model often remains centralized or managed by a smaller, specialized team. Data Mesh, in contrast, fundamentally shifts ownership and accountability to distinct business domains.
- Focus: The data lakehouse primarily focuses on technical convergence (bringing data lake flexibility and data warehouse reliability together). Data Mesh’s focus is broader, encompassing organizational structure, cultural shifts, and a product-oriented mindset for data.
- Complementary, Not Mutually Exclusive: It’s important to note that a data lakehouse can serve as an excellent underlying technology for the self-serve data platform within a Data Mesh architecture. A domain could, for instance, utilize a data lakehouse pattern to build and expose its specific data products. However, the conceptual and organizational shift of Data Mesh goes beyond merely selecting a technology stack.
World2Data Verdict: Embracing the Future of Data Management
The imperative for organizations to be data-driven has never been stronger, and traditional centralized data architectures are increasingly showing their limitations in addressing the scale, complexity, and agility required for modern enterprises. World2Data.com views Data Mesh not as a fleeting trend, but as a critical evolutionary step in data management – a paradigm shift poised to become the dominant approach for large, data-intensive organizations grappling with distributed operational data and the need for rapid analytical insights.
While the journey to a full Data Mesh implementation is demanding, requiring significant organizational change, upfront investment, and a mastery of new architectural concepts like Federated Computational Governance and Data as a Product, its benefits are profound. Organizations that successfully transition will unlock unparalleled agility, superior data quality, enhanced scalability, and a truly democratic approach to data access and utilization. The shift to domain-oriented ownership and a self-serve platform empowers teams, fosters innovation, and drastically reduces the time from data inception to actionable insight.
For World2Data.com, the future success of advanced analytics and Artificial Intelligence initiatives hinges on the reliable, accessible, and trustworthy data that a well-implemented Data Mesh provides. It directly addresses the data quality and availability challenges that often plague MLOps lifecycles, by ensuring that high-quality, domain-curated data products are readily available for model training, feature engineering, and inference. We recommend that organizations, particularly those struggling with data bottlenecks, consider a strategic, phased adoption of Data Mesh principles, starting with pilot domains. Focus on nurturing a data product mindset, investing in a robust self-serve platform, and establishing clear federated governance frameworks. The transformative potential of Data Mesh in building a resilient, adaptable, and truly data-driven enterprise is undeniable, making it an essential component of any forward-thinking digital strategy.


{kind=link}