


Data Mesh: Revolutionizing Data Ownership and Decentralized Architecture for Modern Enterprises
The concept of Data Mesh is rapidly redefining how organizations approach data architecture and management, shifting from monolithic systems to a decentralized, domain-oriented paradigm. This innovative approach champions data as a product, fostering enhanced data ownership and accountability directly within the business domains that generate and consume data. As a cutting-edge data architecture paradigm, Data Mesh leverages decentralized domain-oriented data products, a self-service data infrastructure, and federated computational governance to tackle the scalability and agility challenges inherent in traditional data systems. It fundamentally reconfigures data governance by establishing domain ownership over data quality and access, positioning data products as first-class citizens. Crucially, Data Mesh facilitates advanced AI and ML model development by ensuring the availability of discoverable, high-quality, and trustworthy data products from independent domains, offering a compelling alternative to monolithic Data Warehouses, Centralized Data Lakes, and traditional ETL pipelines.
Unpacking the Paradigm Shift: Why Data Mesh Matters
In today’s data-intensive landscape, the demand for timely, high-quality, and contextually rich data is paramount for driving business intelligence, operational efficiency, and advanced analytics, including sophisticated AI and Machine Learning initiatives. Traditional data architectures, often characterized by centralized data lakes or monolithic data warehouses, have increasingly struggled to keep pace with the exponential growth of data sources, the diversity of data types, and the dynamic needs of various business units. These centralized models frequently lead to bottlenecks, siloed expertise, and a lack of accountability for data quality, ultimately hindering agility and innovation.
The Data Mesh paradigm emerges as a powerful response to these systemic challenges. Conceived by Zhamak Dehghani, Data Mesh proposes a fundamental shift in how enterprises organize around and interact with data. It moves away from a centralized model where a single data team is responsible for all data pipelines and governance, towards a decentralized framework. At its core, Data Mesh is not merely a technological solution but a socio-technical transformation built upon four foundational principles: domain-oriented decentralized data ownership, data as a product, a self-serve data platform, and federated computational governance. This article will delve into each of these pillars, explore the significant benefits and challenges associated with its adoption, draw comparisons with conventional data architectures, and provide a World2Data.com verdict on its transformative potential.
The Four Pillars of a Robust Data Mesh Architecture
The strength and effectiveness of a Data Mesh architecture lie in its four interconnected pillars, each contributing to a more scalable, agile, and trustworthy data ecosystem.
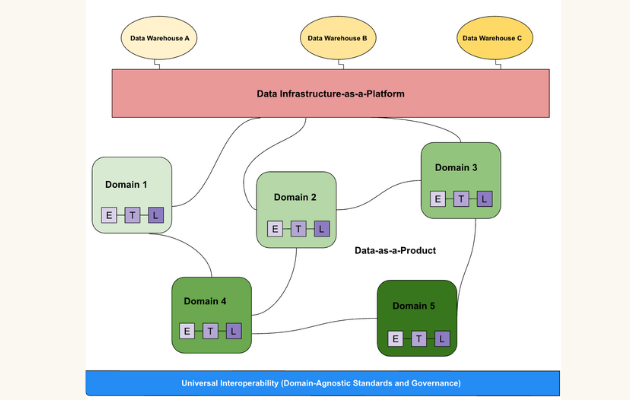
Domain-Oriented Decentralized Data Ownership
The first and arguably most revolutionary pillar of Data Mesh is the shift from a centralized, monolithic data team to decentralized, domain-oriented data ownership. In this model, cross-functional teams responsible for specific business domains (e.g., customer, product, finance) are also made fully accountable for the data within their domain. This means they own the entire lifecycle of their operational data, from ingestion and processing to serving and quality assurance. This distributed ownership model fosters a much deeper understanding of the data’s context, semantics, and intrinsic value, leading to significantly higher data quality and trust. Instead of data becoming a byproduct of operational systems that is then handed off to a central team, it becomes an integral asset managed with precision by those who understand it best. This organizational realignment addresses the traditional problem of data teams becoming bottlenecks, as data pipelines no longer need to pass through a single, overstretched central authority. The primary keyword, Data Mesh, inherently links to this decentralization of data stewardship, promoting a culture where data responsibility is pervasive rather than concentrated.
Data as a Product: The Foundation of Trust and Usability
Building on the principle of domain ownership, the second pillar dictates that data should be treated as a product. Just like any successful software product, a data product must be discoverable, addressable, trustworthy, self-describing, and secure. This means that data produced by a domain isn’t just raw output; it’s a carefully curated, well-documented, and easily consumable asset designed with its users (other domains, analytics teams, ML engineers) in mind. For instance, a “customer” domain would create a “customer data product” that provides a unified, clean, and reliable view of customer information, complete with clear APIs or interfaces for consumption. This focus on user experience and quality transforms the relationship between data producers and consumers, ensuring that data assets consistently meet high standards of reliability and usability. This paradigm directly counters the “data swamp” phenomenon often observed in traditional data lakes, where raw, uncurated data accumulates without proper governance or context, making it unusable for critical applications or high-quality AI/ML models. By emphasizing data products, Data Mesh guarantees that the data fueling ML model development is readily available and trustworthy.
Self-Serve Data Platform: Enabling Autonomy at Scale
To empower domain teams to independently create and manage their data products, the third pillar introduces the concept of a self-serve data platform. This platform acts as an underlying infrastructure that provides generic capabilities and tooling, abstracting away the complexities of data ingestion, storage, transformation, serving, and monitoring. Essentially, it offers a standardized set of tools and services that domain teams can utilize to build their data products without needing deep specialized data engineering expertise for every task. This could include automated data pipeline orchestration, schema management tools, data cataloging features, access control mechanisms, and monitoring dashboards. The self-serve aspect is crucial for scalability, as it removes the dependency on a central data engineering team for every new data product or modification. It accelerates time to value, enabling domains to experiment, innovate, and deploy data products more rapidly, supporting agile development cycles for both traditional analytics and machine learning applications. This self-service capability is a cornerstone of an effective Data Mesh implementation.
Federated Computational Governance: Balancing Autonomy with Interoperability
While the Data Mesh advocates for decentralization and autonomy, it does not imply anarchy. The fourth pillar, federated computational governance, establishes a framework for global policies and standards that ensure consistency, interoperability, and compliance across the decentralized landscape. A federated governance model involves a governing body (a council of representatives from different domains and central data specialists) that defines common rules and standards for data product interoperability, security, privacy, and quality. Crucially, these policies are then enforced computationally by the self-serve platform. For example, a global policy might mandate specific metadata standards for all data products, or define how data access control should be implemented consistently across different domains. This approach ensures that while domain teams have autonomy over their data products, these products remain discoverable, usable, and compliant throughout the organization. It strikes a delicate balance between local domain autonomy and global organizational cohesion, preventing the creation of new data silos and ensuring the integrity of the overall Data Mesh ecosystem.
Challenges and Barriers to Data Mesh Adoption
While the promises of Data Mesh are compelling, its adoption is not without significant hurdles. One of the primary barriers is the profound organizational and cultural shift required. Moving from a centralized mindset to one of decentralized data ownership demands new skill sets, changes in team structures, and a fundamental re-evaluation of data roles and responsibilities. Resistance to change, particularly concerning ownership and accountability, can impede progress. The initial investment in building a robust self-serve data platform can also be substantial, requiring careful planning and resource allocation. Defining clear, logical domain boundaries can be complex, often requiring deep business analysis and consensus across multiple departments to avoid ambiguity or overlap. Furthermore, ensuring consistent data product quality across diverse, autonomous teams, without a single point of control, necessitates strong governance and cultural buy-in. Challenges like data discoverability at scale without a traditional central catalog, and managing potential MLOps complexity in a decentralized environment (where models might rely on multiple, independently managed data products), also need careful consideration to prevent issues like data drift from undermining model performance.
Business Value and Return on Investment (ROI) of Data Mesh
Despite the challenges, the business value and ROI of adopting Data Mesh can be transformative. By empowering domain teams and fostering a product mindset around data, organizations experience significantly faster time to insight and accelerated innovation. Data quality and trust improve dramatically as domain experts become directly responsible for their data products, leading to more reliable analytics and more robust AI/ML models. The decentralized nature of Data Mesh inherently enhances agility and scalability, allowing enterprises to adapt quickly to new data sources and business requirements without overwhelming a central team. It reduces bottlenecks in data access and provisioning, enabling data consumers to find and use the data they need with greater efficiency. Crucially, for AI and ML initiatives, Data Mesh provides discoverable, high-quality, and trustworthy data products, which are foundational for developing, training, and deploying effective machine learning models, simplifying the feature engineering process. Improved compliance and governance, embedded within the federated computational framework, also mitigate risks and ensure adherence to regulatory standards, delivering tangible returns through reduced compliance costs and enhanced data security.
Comparative Insight: Data Mesh vs. Traditional Data Architectures
Understanding the unique value proposition of Data Mesh requires a clear comparison with the traditional data architectures it seeks to replace or augment. The primary alternatives often considered are the monolithic Data Warehouse, the Centralized Data Lake, and the conventional ETL (Extract, Transform, Load) pipelines.
- Centralization vs. Decentralization: The most striking difference lies in the organizational principle. Traditional Data Warehouses and Data Lakes are inherently centralized, with a single team managing data ingestion, storage, and transformation for the entire enterprise. Data Mesh, conversely, is built on a decentralized model, distributing data ownership and responsibility to business domains.
- Ownership Model: In traditional setups, a central data team is typically responsible for data quality and governance, often leading to a lack of deep domain context and accountability. Data Mesh shifts this to domain teams, embedding data quality and context directly at the source, fostering a stronger sense of ownership and accountability for data products.
- Data Quality and Trust: While traditional systems aim for high data quality, the centralized approach can lead to “data swamps” in Data Lakes, where raw, uncurated data makes it difficult to ascertain reliability. Data Mesh’s “data as a product” principle ensures that data is curated, well-documented, and trustworthy by design, improving overall data quality for AI initiatives.
- Scalability and Agility: Monolithic Data Warehouses and Data Lakes often face scalability challenges as data volume and variety grow, leading to bottlenecks in data pipeline development and maintenance. Data Mesh’s distributed nature and self-serve platform offer superior scalability and agility, allowing multiple domain teams to innovate concurrently without being constrained by a central bottleneck.
- Data Silos: Paradoxically, centralized Data Lakes can become large, unmanageable data silos due to a lack of proper governance and discoverability. While Data Mesh decentralizes, its federated computational governance and “data as a product” principles aim to prevent new silos by ensuring interoperability, discoverability, and adherence to common standards across domains.
- ETL Complexity: Traditional ETL pipelines are often complex, brittle, and time-consuming to build and maintain, especially in large enterprises with diverse data sources. Data Mesh aims to reduce this complexity through a self-serve platform that abstracts infrastructure concerns and promotes standardized, productized data interfaces, making data consumption simpler and more efficient.
- Governance: Centralized governance in traditional systems can become a bottleneck, delaying data access and innovation. Data Mesh employs federated computational governance, balancing global standards with domain autonomy, ensuring consistency without sacrificing agility.

World2Data Verdict: Embracing a Future of Data Empowerment
The Data Mesh paradigm represents more than just an architectural pattern; it signifies a profound socio-technical shift towards empowering business domains to take full ownership of their data assets. For organizations grappling with the complexities of big data, the demands of real-time analytics, and the insatiable appetite for high-quality data to fuel advanced AI and machine learning initiatives, Data Mesh offers a compelling vision. It moves beyond merely managing data to fostering a culture where data is treated as a strategic product, meticulously crafted and responsibly governed by those who understand its deepest context.
At World2Data.com, our analysis concludes that while the implementation of Data Mesh demands significant organizational transformation, cultural change, and investment in a robust self-serve platform, its long-term benefits far outweigh the initial hurdles. We strongly recommend that enterprises consider a phased, incremental adoption strategy, focusing first on well-defined domains and iteratively expanding. Success hinges on strong executive sponsorship, continuous education, and a willingness to redefine traditional roles and responsibilities. By embracing Data Mesh, organizations can unlock unprecedented value from their distributed data landscapes, achieve superior data quality and trust, accelerate innovation, and build a truly agile, scalable, and data-driven culture that is future-proofed for the era of pervasive AI. The future of data management is undoubtedly decentralized, and Data Mesh provides the blueprint for this crucial evolution.

{kind=link}