


Data Mesh Implementation: A Multi-Team Case Study for Decentralized Data Excellence
Platform Category: Data Architecture Paradigm
Core Technology/Architecture: Domain-Oriented Decentralized Ownership, Data as a Product, Self-Serve Data Platform, Federated Computational Governance
Key Data Governance Feature: Federated Computational Governance
Primary AI/ML Integration: Enables decentralized ML model development by providing access to domain data products
Main Competitors/Alternatives: Centralized Data Warehouse, Centralized Data Lake
Data Mesh Implementation represents a significant architectural and organizational shift towards decentralized data ownership and consumption, promising greater agility, scalability, and data quality. Many organizations today grapple with the complexities of transforming their monolithic data systems into domain-oriented data products. Our recent multi-team case study provides invaluable insights into a practical approach for navigating these challenges and successfully realizing the promised benefits of a true data mesh architecture within a diverse corporate environment, underscoring that successful Data Mesh Implementation is as much a cultural journey as it is a technical one.
Introduction: Unlocking Agility with Decentralized Data Architecture
The relentless growth of data volumes and the increasing demand for real-time insights have pushed traditional centralized data architectures to their limits. Monolithic data lakes and warehouses, while foundational, often become bottlenecks for innovation, leading to slow data delivery, unclear ownership, and a lack of data trustworthiness. In response, the concept of the Data Mesh has emerged as a revolutionary Data Architecture Paradigm, advocating for a decentralized approach that treats data as a product and empowers domain teams. This article delves into a comprehensive multi-team case study, exploring the practicalities, challenges, and profound benefits observed during a large-scale Data Mesh Implementation. Our objective is to provide a detailed roadmap and critical lessons learned for organizations contemplating or currently undertaking their own journey towards a more agile, scalable, and domain-driven data ecosystem.
Core Breakdown: Deconstructing the Data Mesh Implementation
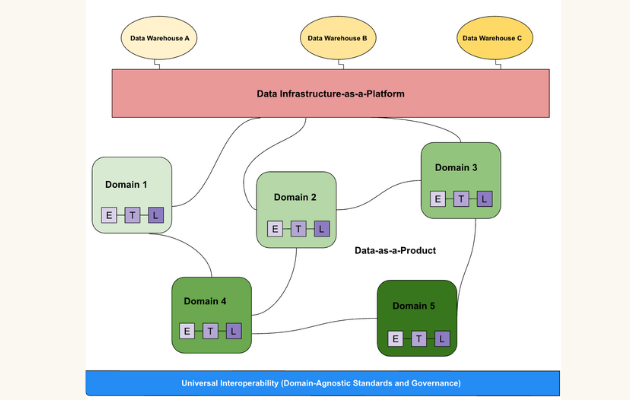
At its heart, a successful Data Mesh Implementation redefines how organizations manage, share, and consume data. It moves away from the traditional, centralized model where a single data team is responsible for all data ingestion, transformation, and serving. Instead, it proposes four foundational principles: domain-oriented decentralized ownership, data as a product, a self-serve data platform, and federated computational governance. Understanding and meticulously implementing each of these pillars is paramount to achieving the architectural shift and the associated business value.
Domain-Oriented Decentralized Ownership
This principle dictates that ownership and accountability for data should reside with the business domains that produce or primarily consume the data. For instance, a “Customer” domain team would own customer data, ensuring its quality, accuracy, and availability. This shift fundamentally alters organizational structures, moving from a central data team managing everything to autonomous, cross-functional teams embedded within specific business areas. These teams, comprising data engineers, analysts, and domain experts, become fully responsible for the entire lifecycle of their data – from source to consumption. This ensures deep domain expertise is directly applied to data stewardship, leading to higher quality and more relevant data assets. In our case study, this meant reorganizing existing teams and establishing new ones, each with clear mandates over specific data domains, fostering a stronger sense of ownership and responsibility.
Data as a Product
Central to the Data Mesh philosophy is the idea of treating data itself as a product. This means data is not just a raw input or an output of a process, but a well-defined, discoverable, addressable, trustworthy, self-describing, and secure entity that meets the needs of its consumers. Each domain team is tasked with designing, building, and maintaining data products that are easy to consume, well-documented, and adhere to established quality standards. For example, a “Sales Performance” data product might offer curated sales metrics, customer segmentations, and regional performance trends, all packaged for easy access by marketing, finance, or executive teams. This product-centric mindset encourages domain teams to consider their data consumers’ needs from the outset, leading to more valuable and reliable data assets. Our multi-team approach focused heavily on defining clear data product specifications and ensuring these products were continuously improved based on user feedback.
Self-Serve Data Platform
To enable decentralized ownership and data-as-a-product, a robust self-serve data platform is indispensable. This platform provides the underlying infrastructure, tools, and capabilities that allow domain teams to autonomously create, publish, monitor, and consume data products without constant reliance on a central IT team. Components of such a platform typically include automated data ingestion pipelines, data transformation tools, data cataloging services for discoverability, metadata management systems, access control mechanisms, and monitoring tools. The platform abstracts away infrastructure complexities, allowing domain teams to focus on their data and business logic. In our case study, building this self-serve layer was a significant undertaking, requiring a dedicated platform team to develop and maintain generic capabilities that could be leveraged by all domain teams, fostering rapid data product development and deployment.
Federated Computational Governance
While decentralization is key, it does not imply anarchy. Data Mesh necessitates a new approach to governance: federated computational governance. Instead of a single, monolithic governance body, a federated model allows a small central team to define global, high-level policies (e.g., security, privacy, interoperability standards), while individual domain teams are responsible for implementing and enforcing these policies within their specific data products. This governance is “computational” in that it leverages automation, policy-as-code, and embedded checks within the self-serve platform to ensure compliance. This balances autonomy with necessary control, ensuring consistency and security across the entire data ecosystem without stifling innovation. Our experience showed that establishing a lean, empowered governance council with representatives from various domains was critical for defining shared standards and resolving cross-domain issues, ensuring that the Data Mesh Implementation remained cohesive and secure.

Challenges and Barriers to Adoption
Despite its promise, Data Mesh Implementation is far from straightforward. Organizations often encounter significant hurdles, both technical and organizational. A primary challenge is the **cultural and organizational shift** required. Moving from a centralized mindset to one of decentralized ownership demands extensive change management, training, and overcoming resistance to new ways of working. Skill gaps within existing teams, especially regarding data product management and modern data engineering practices, can be substantial barriers. Another significant challenge lies in **interoperability and standardization**. Ensuring that data products from disparate domains can seamlessly interact and be combined effectively requires robust standards for data formats, APIs, and metadata, which are often complex to define and enforce across multiple independent teams. The **maturity of the self-serve data platform** is also a critical factor; an immature platform can hinder adoption and force domain teams back into reliance on central IT. Finally, implementing **federated computational governance** effectively without creating a “wild west” scenario or, conversely, overly bureaucratic processes, requires careful design and continuous iteration. Balancing autonomy with necessary global constraints is a delicate act.
Business Value and ROI of Data Mesh Implementation
The investment in a Data Mesh Implementation yields substantial business value and a compelling return on investment (ROI) by addressing the limitations of traditional data architectures. One of the most immediate benefits is **accelerated data product delivery**. By empowering domain teams with autonomy and self-serve capabilities, the time it takes to develop, test, and deploy new data products is drastically reduced, leading to faster time-to-insight and quicker innovation cycles. Secondly, there is a marked **improvement in data quality and trust**. When domain experts are directly accountable for their data products, they are inherently motivated to ensure accuracy, completeness, and reliability, fostering greater confidence in data assets across the organization. This increased trust translates into better decision-making. Furthermore, Data Mesh enhances **organizational agility and scalability**. Decoupling data ownership allows different domains to evolve their data products independently and in parallel, avoiding central bottlenecks and enabling the organization to scale its data efforts horizontally. This also fosters **increased data literacy and innovation**, as data becomes more accessible, understandable, and trusted, empowering more users to explore and derive value from it. Ultimately, the ROI is realized through more efficient data operations, better decision-making, and a more adaptive, data-driven enterprise capable of responding rapidly to market changes.
Comparative Insight: Data Mesh vs. Traditional Data Architectures
To fully appreciate the transformative power of Data Mesh Implementation, it’s essential to compare it with its predecessors: the centralized Data Warehouse and the Data Lake. These traditional architectures, while having served organizations well for decades, present inherent limitations that Data Mesh seeks to overcome.
Centralized Data Warehouse
A Data Warehouse typically consolidates structured data from various operational systems into a single, optimized repository for reporting and analysis. Its strengths lie in providing a “single source of truth” and ensuring high data quality for predefined analytical needs. However, Data Warehouses are often characterized by:
- Centralized Ownership: A single IT team is responsible for all ETL (Extract, Transform, Load) processes, schema design, and data delivery, leading to bottlenecks and slow response times for new data requests.
- Schema-on-Write: Data must conform to a predefined schema upon ingestion, making it rigid and less adaptable to evolving business needs or new data sources.
- Limited Scalability: Scaling a central team to meet the diverse and rapidly changing data demands of numerous business units is challenging.
- Data as an Asset: Data is primarily viewed as an asset owned by IT, rather than a product served to business domains.
Centralized Data Lake
Data Lakes emerged to address some of the inflexibility of Data Warehouses by storing raw, unstructured, and semi-structured data at scale, often with a “schema-on-read” approach. This allowed for greater agility in data ingestion and supported big data analytics and machine learning. Yet, Data Lakes still suffer from:
- Centralized Ingestion: While data storage is flexible, the ingestion and curation often remain centralized, leading to similar bottlenecks as Data Warehouses.
- Data Swamps: Without strong governance and domain ownership, Data Lakes can quickly become “data swamps” – repositories of uncurated, untrustworthy, and undiscoverable data.
- Complex Data Governance: Governing raw, diverse data centrally without domain expertise becomes an overwhelming task, leading to poor data quality and security issues.
- Technical Debt: The flexibility of schema-on-read can lead to significant technical debt as data transformation logic often resides in complex, ad-hoc scripts rather than managed data products.
Data Mesh: A Paradigm Shift
In stark contrast, Data Mesh fundamentally shifts the paradigm:
- Decentralized Ownership: Domain teams own their data products end-to-end, fostering accountability and expertise. This is the cornerstone of effective Data Mesh Implementation.
- Data as a Product: Data is treated as a high-quality product, designed for discoverability, usability, and trustworthiness by its consumers.
- Self-Serve Platform: A shared platform empowers domain teams to autonomously build, deploy, and manage their data products, accelerating delivery.
- Federated Computational Governance: Global policies are defined centrally, but their implementation and enforcement are distributed and automated within domains, ensuring consistency without sacrificing agility.
- Scalability: The architecture scales horizontally with the organization, as new domains can independently develop and offer data products without overwhelming a central team.
This decentralization alleviates central bottlenecks, increases data quality through domain expertise, and fosters a culture of data literacy and innovation across the enterprise, providing a far more agile and resilient data ecosystem than its centralized predecessors.
World2Data Verdict: Embracing Data Mesh as the Future of Enterprise Data
The multi-team case study unequivocally demonstrates that Data Mesh Implementation is not merely an architectural trend but a strategic imperative for organizations striving for true data-driven agility and innovation. While the journey presents significant challenges, particularly in cultural transformation and the development of a robust self-serve platform, the benefits in accelerated data product delivery, enhanced data quality, and improved organizational scalability are profound and tangible. World2Data.com advises enterprises to approach Data Mesh not as a single project, but as an evolutionary organizational transformation. Prioritize executive sponsorship, invest heavily in training and upskilling your teams, and build your self-serve platform incrementally, focusing on reusable capabilities. The future of enterprise data lies in this decentralized, product-centric model, empowering every business domain to become a data innovator. Organizations that embrace the principles of Data Mesh today will be exceptionally positioned to harness their data’s full potential for competitive advantage tomorrow.

{kind=link}