


Data Pipeline Essentials: Building Reliable Data Flows for Modern Analytics
A robust data pipeline is the pulsating heart of any data-driven organization, meticulously channeling information from myriad sources to the crucial analytical tools and decision-makers who depend on it. This intricate circulatory system ensures that raw data is not only collected but also transformed, cleansed, and delivered efficiently, powering everything from business intelligence dashboards to advanced machine learning models. Understanding and mastering the art of building reliable data pipelines is no longer optional; it’s a fundamental requirement for maintaining a competitive edge in today’s fast-evolving digital landscape.
Introduction: The Imperative for Seamless Data Flow
In an era defined by overwhelming data volumes and ever-increasing velocity, the ability to effectively manage and leverage information is paramount. A well-architected data pipeline ensures that an organization can harness the full potential of its data assets, transforming raw, disparate data into actionable insights. This article delves into the core principles, architectural components, and best practices essential for constructing dependable data pipelines that not only meet current demands but are also future-proofed against evolving challenges. We will explore how these pipelines serve as the backbone for critical operations, ensuring data quality, consistency, and timely delivery for all analytical and operational needs.
Core Breakdown: Architecture and Components of a Reliable Data Pipeline
Building reliable data pipelines involves a meticulous orchestration of various components and adherence to robust architectural principles. These pipelines facilitate critical functions within the data ecosystem, serving as the foundational layer for Data Integration, ETL/ELT processes, and even advanced Stream Processing Platforms.
Key Architectural Components and Principles:
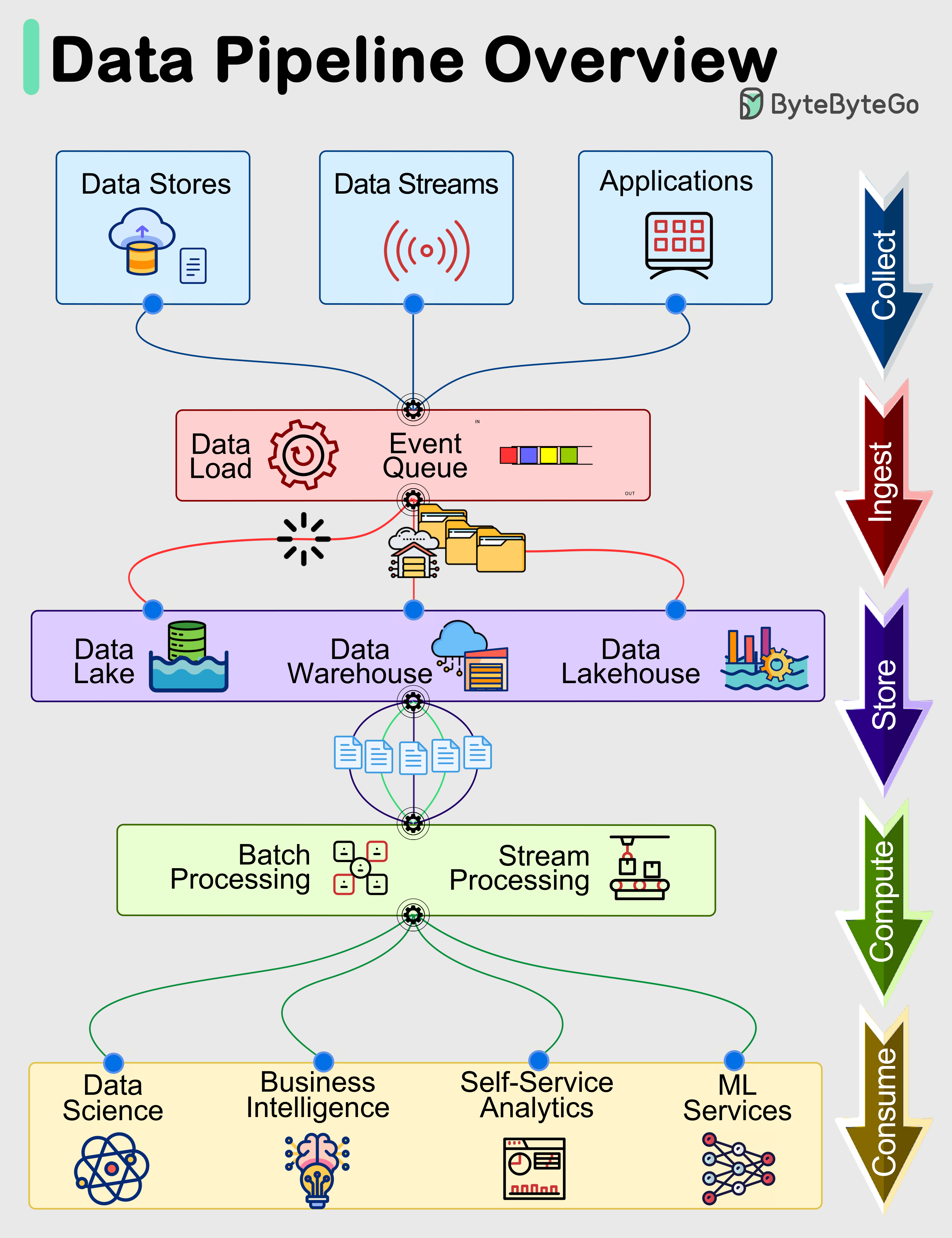
- Data Ingestion: This initial stage focuses on collecting data from diverse sources, which can range from transactional databases and application logs to IoT devices and third-party APIs. Technologies enabling this include batch processing for large historical datasets and real-time processing platforms like Apache Kafka for continuous data streams. The choice depends on the data’s latency requirements and volume.
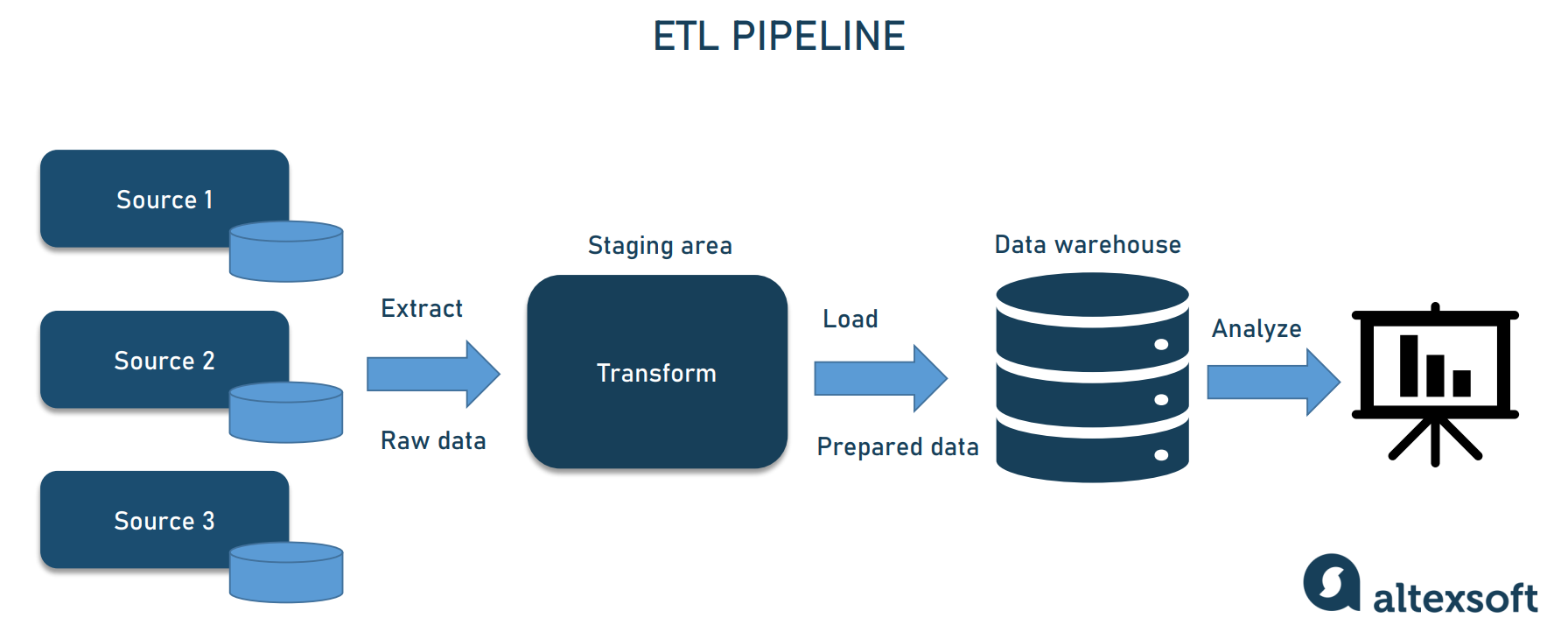
- Data Transformation and Processing: Once ingested, raw data often requires significant cleansing, enrichment, aggregation, and restructuring to make it suitable for analysis. This is where ETL/ELT Tools come into play. ETL (Extract, Transform, Load) involves transforming data before loading it into a destination, while ELT (Extract, Load, Transform) loads raw data first, often into a data lake, and then transforms it in place using powerful computing resources.
- Data Storage and Delivery: The final processed data must be stored in an optimized format and delivered to its intended consumers. This could involve loading into a Data Warehouse for structured analytical queries, a Data Lake for diverse data types, or directly into dashboards, reporting tools, or machine learning models.
Core Technology and Architecture Principles:
Reliable data pipelines are built upon a foundation of critical technological principles:
- Event-driven Architecture: For real-time processing, pipelines often adopt an event-driven model, reacting instantly to data changes or events, crucial for applications requiring low-latency insights.
- Distributed Systems: To handle vast data volumes and high processing loads, pipelines leverage distributed systems that can scale horizontally, processing data across multiple nodes.
- Batch and Real-time Processing: Modern pipelines are often hybrid, combining batch processing for large, less time-sensitive data loads with real-time stream processing for immediate insights.
- Idempotency: A critical design principle ensuring that an operation can be applied multiple times without changing the result beyond the initial application. This is vital for fault tolerance and recovery, preventing data duplication or corruption during retries.
- Fault Tolerance: The ability of the pipeline to continue operating correctly even when parts of it fail. This is achieved through redundancy, error handling, and robust recovery mechanisms.
- Scalability: The capacity of the pipeline to handle increasing data volumes and processing demands efficiently, often achieved through cloud-native architectures and containerization.
- Observability: The capability to understand the internal state of the pipeline from its external outputs. This includes comprehensive logging, metrics, and tracing, which are crucial for effective monitoring and debugging.
Orchestration tools like Apache Airflow play a pivotal role in managing the complex dependencies and scheduling of tasks within these pipelines, ensuring that data flows predictably and efficiently. Other significant players in this space include Fivetran, Stitch Data for automated data integration, and enterprise solutions like Talend and Informatica PowerCenter for robust ETL capabilities. Cloud-native services such as Google Cloud Dataflow, AWS Glue, and Azure Data Factory offer managed services that abstract much of the underlying infrastructure complexity.
Challenges and Barriers to Adoption:
Despite their critical importance, building and maintaining reliable data pipelines presents significant hurdles:
- Data Drift and Schema Evolution: Upstream data sources frequently change their schemas, leading to data drift that can break downstream pipelines. Managing these evolving schemas without causing disruptions is a continuous challenge.
- MLOps Complexity: Integrating data pipelines with Machine Learning Operations (MLOps) adds layers of complexity, requiring seamless coordination to provide clean and timely data for ML model training and inference. Ensuring data consistency between training and production environments is crucial.
- Scalability and Performance: As data volumes and velocity grow exponentially, ensuring pipelines can scale efficiently without compromising performance or incurring excessive costs is an ongoing battle.
- Data Quality and Validation: Maintaining high data quality is paramount. Pipelines must incorporate robust Data Quality Monitoring and Data Validation mechanisms to identify and rectify errors early, preventing corrupted data from propagating.
- Error Handling and Alerting: Failures are inevitable. Implementing sophisticated Error Handling and Alerting systems is essential for quick detection and resolution of issues, minimizing downtime and data loss.
Business Value and ROI:
The investment in building robust data pipelines yields substantial returns, directly impacting an organization’s bottom line and strategic capabilities:
- Faster Model Deployment: By providing clean, consistent, and timely data, data pipelines significantly accelerate the development and deployment of machine learning models. This is crucial for integrating with major ML platforms and supporting feature stores, which depend on high-quality, pre-processed data.
- Improved Data Quality for AI: High-quality data is the lifeblood of AI and ML. Pipelines ensure data integrity, reducing bias and improving the accuracy and reliability of AI systems.
- Enhanced Decision-Making: Reliable data flows provide decision-makers with accurate, up-to-date insights, enabling more informed and agile strategic choices.
- Operational Efficiency: Automation of data ingestion, transformation, and delivery reduces manual effort, human error, and operational costs.
- Compliance and Governance: Features like Data Lineage Tracking and Metadata Management are built into robust pipelines, ensuring transparency and aiding compliance with regulatory requirements. This helps organizations understand data origins, transformations, and usage.
Comparative Insight: Data Pipelines vs. Traditional Data Lakes/Warehouses
While often discussed in conjunction, it’s crucial to understand the distinct yet complementary roles of data pipelines and traditional data repositories like Data Lakes and Data Warehouses. A common misconception is to view them as alternatives; in reality, a robust data architecture leverages all three in a symbiotic relationship.
Data Warehouses are optimized for structured, cleaned, and aggregated data, designed to support business intelligence and reporting with high-performance querying. They enforce strict schemas and data governance rules. Data Lakes, on the other hand, are repositories for raw, unstructured, semi-structured, and structured data, stored in its native format. They offer immense flexibility for exploratory analytics, machine learning, and storing diverse data types without predefined schemas.
Where do data pipelines fit into this? They are the essential conduits that *feed* both Data Lakes and Data Warehouses. Without effective data pipelines, these repositories would remain stagnant or filled with unusable, untrustworthy data. Pipelines perform the critical functions of:
- Ingestion: Moving data from source systems into the Data Lake (raw zone) or directly into a Data Warehouse (if pre-transformed).
- Transformation: Taking raw data from the Data Lake, cleaning it, enriching it, and transforming it into a structured format suitable for loading into a Data Warehouse or for specific analytical applications within the lake itself (e.g., creating curated zones).
- Orchestration: Managing the complex workflows between different zones of a Data Lake (raw, refined, curated) and ensuring data consistency when moving data to a Data Warehouse.
- Real-time Updates: For scenarios requiring immediate insights, pipelines handle stream processing, updating Data Lakes or Data Warehouses with near real-time data, something traditional batch-oriented systems struggled with.
- Schema Evolution: Pipelines are equipped to handle changes in source schemas, applying necessary transformations before data lands in a Data Warehouse, or managing schema-on-read for Data Lakes.
In essence, Data Lakes and Data Warehouses provide the storage and analytical engines, but it is the data pipeline that provides the lifeblood, ensuring data flows correctly, is of high quality, and is ready for consumption. A well-designed pipeline makes a Data Lake truly useful by moving data through its various stages of refinement, and it keeps a Data Warehouse updated with fresh, validated data. They are not competing technologies but rather interdependent components of a holistic data management strategy, with the data pipeline being the active, dynamic element that enables the static storage solutions to deliver value.
World2Data Verdict: Pioneering Data Agility with Resilient Pipelines
The fundamental role of a robust data pipeline cannot be overstated in today’s data-intensive world. World2Data believes that organizations must shift their focus from merely collecting data to architecting intelligent, resilient, and observable data flows. The future demands pipelines that are not just efficient but are intrinsically designed for fault tolerance, idempotency, and seamless schema evolution, especially given the rapid pace of change in data sources and analytical requirements. Investing in advanced Workflow Orchestration tools and embracing cloud-native solutions that offer managed services for stream and batch processing will be key differentiators. Ultimately, companies that prioritize the construction of agile, self-healing data pipelines will be best positioned to unlock unparalleled insights, drive innovation, and maintain a decisive competitive advantage in the decade ahead.

{kind=link}