


What is Data Sharding? Mastering Scalability Through Data Sharding Implementation
Platform Category: Database Scaling Technique
Core Technology/Architecture: Horizontal Partitioning / Shared-Nothing Architecture
Key Data Governance Feature: Shard Key Management
Primary AI/ML Integration: Backend for large-scale ML data storage (e.g., Feature Stores)
Main Competitors/Alternatives: Vertical Scaling, Replication, Vertical Partitioning
Understanding the nuances of Data Sharding Implementation is crucial for modern database architects grappling with ever-growing data volumes and user demands. Data sharding is a database architecture pattern that horizontally partitions data, distributing rows of a single logical database table across multiple separate database instances. This technique is pivotal for achieving unparalleled scalability and resilience, transforming how applications handle massive datasets and concurrent user requests.
Introduction: Unlocking Hyperscale with Data Sharding
In an era defined by explosive data growth and an insatiable demand for real-time processing, traditional monolithic database architectures often buckle under pressure. As datasets expand beyond the capacity of a single server, performance bottlenecks, increased latency, and system outages become inevitable. This is where Data Sharding emerges as a critical strategy, fundamentally altering how data is stored and retrieved. It’s a horizontal partitioning technique, central to building highly scalable and performant distributed systems.
The objective of this article is to provide a comprehensive deep dive into what Data Sharding entails, explaining its core architectural principles, when its implementation becomes not just beneficial but essential, and the intricate considerations involved in a successful Data Sharding Implementation. We will explore its advantages in terms of performance and availability, dissect the challenges it presents, and contrast it with alternative scaling methods. For any data platform analyst or architect at World2Data.com, grasping the intricacies of Data Sharding is key to future-proofing data infrastructure.
Core Breakdown: The Architecture and Mechanics of Data Sharding
At its heart, Data Sharding is about distributing data across multiple independent database servers, each holding a unique subset of the total dataset. This creates a “shared-nothing” architecture where each shard operates autonomously, eliminating single points of contention and enabling unparalleled parallel processing capabilities.
Understanding Horizontal Partitioning
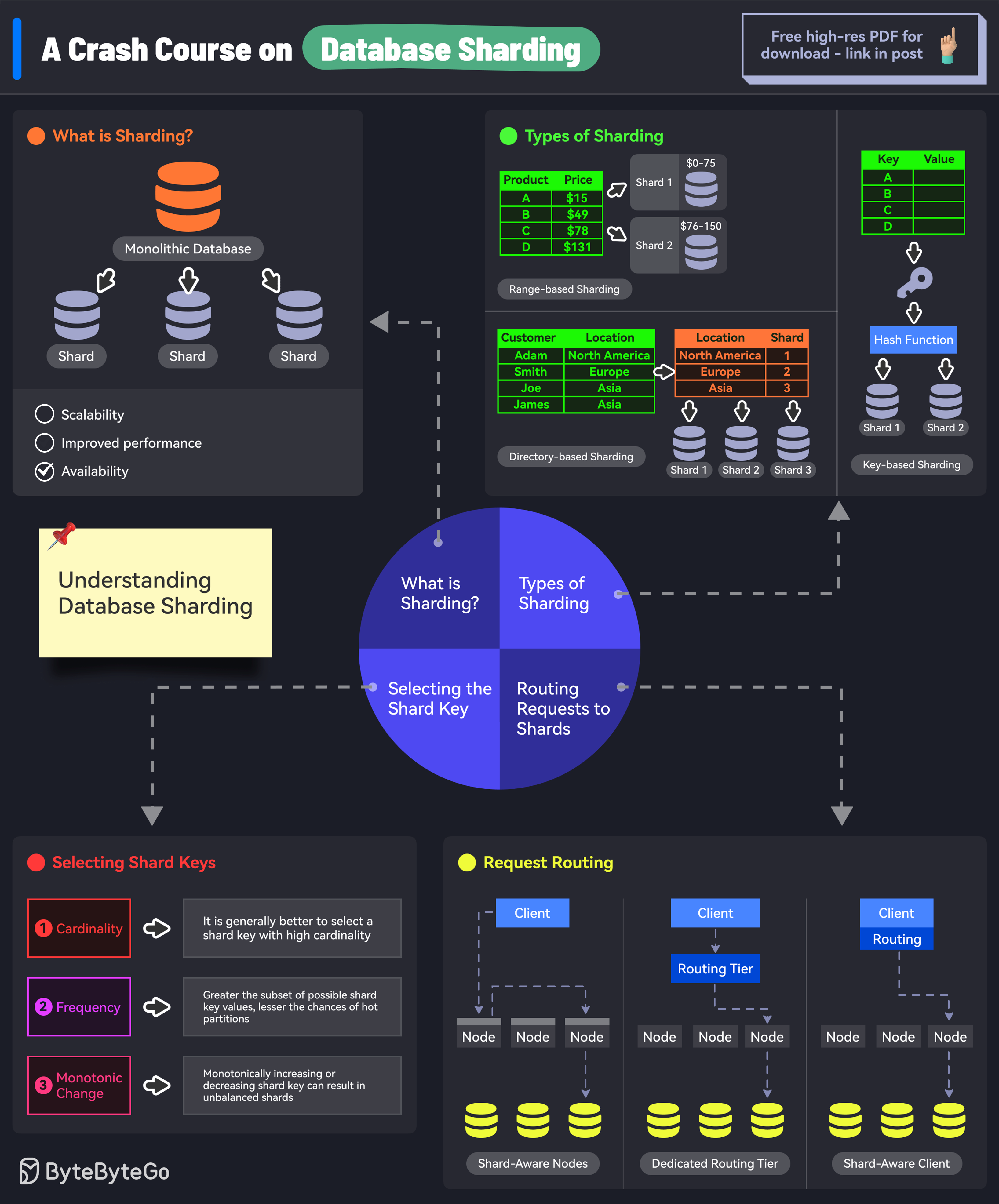
Unlike vertical partitioning, which divides tables by columns, horizontal partitioning (sharding) divides a single logical table by rows. Each row or a group of rows is assigned to a specific shard based on a predetermined sharding key. This means that a client application interacts with a logical database, but underneath, the data is spread across several physical databases, or shards. Each shard can reside on a separate server, allowing for massive scaling beyond the limits of a single machine.
Key Components and Architecture
- Shards: These are individual, independent database instances, each containing a subset of the data. From the application’s perspective, they collectively form a single, larger database.
- Sharding Key (Partition Key): This is arguably the most critical element in any Data Sharding Implementation. The sharding key is a column (or set of columns) whose value determines which shard a particular row of data will reside on. The choice of sharding key dictates data distribution, query routing, and greatly impacts performance and future scalability. Common choices include user IDs, geographical locations, or timestamps.
- Router/Query Coordinator: In a sharded system, applications typically don’t directly connect to individual shards. Instead, a routing layer or query coordinator intercepts queries, analyzes the sharding key within the query, and directs it to the appropriate shard. For queries that span multiple shards (cross-shard queries), the router aggregates results from various shards before returning them to the application.
- Metadata Management: A system needs to keep track of which data lives on which shard. This metadata can be stored in a dedicated configuration database, allowing the router to efficiently map sharding keys to physical shard locations.
Challenges and Barriers to Adoption
While the benefits of sharding are substantial, its implementation is far from trivial and introduces significant operational complexities:
- Sharding Key Selection: A poorly chosen sharding key can lead to uneven data distribution (hotspots), where one shard receives disproportionately more traffic or data than others. This negates the benefits of sharding and can create new performance bottlenecks. Changing a sharding key after initial deployment is often an extremely complex and resource-intensive operation.
- Cross-Shard Joins and Transactions: Operations that require joining data across multiple shards or executing transactions that involve data on different shards are notoriously difficult to implement efficiently. They often require complex distributed transaction protocols or careful application-level design to minimize their occurrence.
- Data Rebalancing: Over time, as data grows or usage patterns change, the initial data distribution across shards can become uneven. Rebalancing data—moving subsets of data from overloaded shards to underutilized ones—is a highly complex process that must be performed without downtime and without compromising data consistency.
- Operational Overhead: Managing a sharded database system means managing multiple database instances, each with its own backups, monitoring, and maintenance routines. This significantly increases the operational overhead and requires specialized tools and expertise.
- Application Complexity: Applications must be designed with sharding in mind, particularly concerning how queries are routed and how data is accessed. Developers need to be aware of the underlying sharding scheme, which can add complexity to application development and testing.
- MLOps Complexity (Backend for AI/ML): When sharding is used as the backend for large-scale ML data storage (e.g., Feature Stores), it introduces MLOps complexity. Ensuring feature consistency across shards, managing distributed feature computations, and handling potential data drift in a sharded environment require robust monitoring and specialized orchestration tools. The distributed nature can complicate data lineage tracking and debugging for ML pipelines.
Business Value and ROI of Data Sharding
Despite the inherent complexities, the return on investment for a well-executed Data Sharding Implementation can be immense, particularly for high-growth enterprises:
- Massive Scalability: Sharding allows databases to scale horizontally to accommodate virtually limitless data volumes and user concurrency, far beyond the capabilities of a single server. This means businesses can grow without hitting database performance ceilings.
- Improved Performance: By distributing the workload, queries target smaller datasets on individual shards, leading to significantly faster query execution times and higher transaction throughput. This directly translates to a better user experience and supports more demanding applications.
- Enhanced Availability and Resilience: Since each shard is an independent unit, an outage or performance issue in one shard typically only affects a subset of the data or users, rather than bringing down the entire system. This improves overall system resilience and availability.
- Cost Efficiency: Instead of continually upgrading to more powerful (and exponentially more expensive) single servers (vertical scaling), sharding allows businesses to scale by adding more commodity hardware. This can be a much more cost-effective approach for sustained growth.
- Optimized for AI/ML Workloads: For organizations leveraging AI and Machine Learning, sharding provides the necessary backend infrastructure for large-scale feature stores. It enables efficient storage and retrieval of billions of features, powering real-time inference and training of complex models that require vast amounts of data. Data quality for AI is maintained by isolating issues to specific shards, making them easier to identify and rectify.
- Faster Model Deployment: With data efficiently stored and accessible across shards, ML models can access necessary features quickly, accelerating the entire MLOps lifecycle from training to deployment and continuous iteration.

Comparative Insight: Sharding vs. Traditional Database Scaling
To fully appreciate the power of Data Sharding, it’s crucial to understand how it differs from and complements other common database scaling strategies, specifically vertical scaling, replication, and even traditional Data Lakes/Warehouses.
Vertical Scaling (Scaling Up)
Vertical scaling involves upgrading the hardware of a single database server—adding more CPU, RAM, or faster storage. It’s often the simplest initial scaling approach. However, it has inherent limitations: hardware upgrades eventually become cost-prohibitive and, ultimately, technologically impossible. There’s always a ceiling to how powerful a single machine can be. Data Sharding, conversely, is a horizontal scaling (scaling out) strategy, which offers virtually limitless scalability by adding more machines.
Replication (Read Scaling and High Availability)
Replication involves creating multiple copies of a database. It’s excellent for improving read performance (by distributing read queries across replicas) and enhancing high availability (by having failover replicas). However, replication doesn’t directly solve the write scalability problem of a single primary database. All writes typically still go to one master, which can become a bottleneck as write volumes increase. Sharding, by distributing writes across multiple masters (each shard being a master for its data subset), addresses write scalability directly, a feature not inherently provided by replication alone. Often, sharding is combined with replication within each shard for both write scalability and high availability.
Vertical Partitioning (Different from Sharding)
Vertical partitioning separates tables by columns, moving frequently accessed or large columns into separate tables, potentially on different storage. For example, a user table might be split into `users_core` (ID, username) and `users_profile` (biography, preferences). While it can improve performance by reducing row width and I/O for specific queries, it doesn’t distribute the *rows* of a single logical table across multiple servers, thus not directly addressing the sheer volume of data or high transaction rates in the same way horizontal partitioning (sharding) does.
Data Sharding vs. Traditional Data Lake/Data Warehouse
Traditional Data Warehouses (DW) and Data Lakes serve different primary purposes than sharded operational databases. Data Warehouses are optimized for analytical queries on structured, historical data, often involving complex joins across large datasets, typically read-heavy. Data Lakes store raw, varied data for future analysis and machine learning, also primarily analytical. While they too deal with large data volumes and can be distributed, they are not designed for the low-latency, high-throughput transactional workloads that Data Sharding addresses for operational databases. A sharded database provides the transactional backbone, feeding clean, processed data into Data Lakes or Data Warehouses for further analytical insights. For instance, a sharded database might power a real-time e-commerce platform, while a Data Lake stores all historical transaction details for business intelligence and fraud detection.
World2Data Verdict: The Imperative of Strategic Data Sharding
For organizations operating at scale or aspiring to exponential growth, Data Sharding Implementation is not merely an option but an architectural imperative. The complexities, while real, are outweighed by the profound benefits of unparalleled scalability, performance, and resilience. World2Data.com emphasizes that the future of data platforms lies in intelligent distribution, and sharding is a cornerstone of this paradigm. Successful adoption hinges on meticulous planning, especially in the selection of a robust sharding key and the development of sophisticated tools for monitoring, rebalancing, and managing cross-shard operations. Investing in a robust Data Sharding Implementation strategy today ensures that your data infrastructure can not only meet current demands but also evolve seamlessly with the unpredictable needs of tomorrow’s data-intensive applications and the burgeoning field of AI/ML. The ability to handle vast, distributed feature stores for machine learning, for instance, underscores its critical role in advanced data ecosystems. Embrace sharding, not as a quick fix, but as a foundational pillar for sustainable, hyper-scalable data architecture.

{kind=link}