


Mastering Flink Stream Processing: A Deep Dive into Real-time Data Architectures for the Modern Enterprise
In the rapidly evolving landscape of data management, the ability to process and analyze data in real-time has become a critical differentiator. Apache Flink has emerged as a pioneering framework, fundamentally transforming how organizations approach continuous data streams. This powerful open-source technology, designed for high-throughput and low-latency operations, allows businesses to extract immediate insights, making it indispensable for modern, data-driven applications. This article provides a comprehensive exploration of Flink Stream Processing, dissecting its core capabilities, architectural nuances, and strategic importance in building resilient real-time data pipelines.
Introduction: The Imperative of Real-time Flink Stream Processing
The digital era generates data at an unprecedented velocity, often in continuous streams. From IoT devices and financial transactions to user interactions on web platforms, the value of this data diminishes rapidly with time. Traditional batch processing systems, while effective for historical analysis, fall short when immediate action or insight is required. This is where Flink Stream Processing becomes not just an advantage, but a necessity. It empowers enterprises to react to events as they happen, enabling instantaneous decision-making and enhancing operational responsiveness.
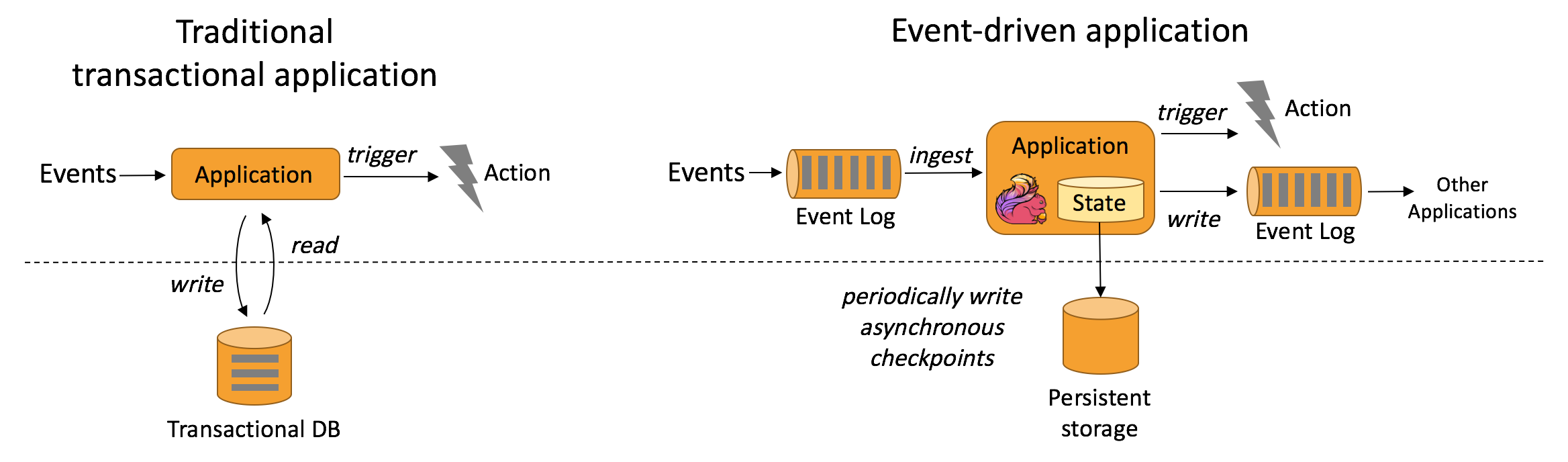
Apache Flink, categorized as a Stream Processing Framework, offers a robust and versatile solution. Its core technology is an Open Source, Distributed Stateful Stream Processing engine. This design allows Flink to handle complex, stateful computations reliably and efficiently, processing unbounded data streams with precision and fault tolerance. A key strength lies in its state management capabilities and unique checkpointing mechanism, which together guarantee exactly-once processing semantics and consistent results, even in the face of system failures.
Beyond its core processing power, Flink integrates seamlessly into broader data ecosystems. For data governance, it facilitates integration with external data catalogs like Hive Metastore, allowing for centralized metadata management and schema evolution tracking. Furthermore, its relevance extends into the realm of artificial intelligence and machine learning; Flink offers a built-in FlinkML library, supporting stream-based machine learning for real-time model training and inference. While platforms like Apache Spark Streaming, Apache Kafka Streams, and Apache Beam serve as Main Competitors/Alternatives, Flink’s distinct approach to true stream processing and state handling often positions it as the preferred choice for mission-critical, low-latency applications.
Core Breakdown: Architectural Pillars and Business Impact of Flink Stream Processing
The efficacy of Flink Stream Processing stems from a meticulously designed architecture that prioritizes efficiency, accuracy, and reliability. Understanding its core components is crucial to leveraging its full potential.
Architectural & Core Components of Flink
- Event-Time Processing: A cornerstone of Flink’s accuracy, event-time processing ensures that computations are based on when events actually occurred, not when they were received. This is critical for applications where data arrival order or processing delays can skew results, such as financial transaction analysis or sensor data aggregation. Flink manages event time via watermarks, which are logical time progress indicators within the data stream.
- State Management: Flink is renowned for its powerful and flexible state management. Unlike stateless processors, Flink operators can maintain state across events, allowing for complex computations like aggregations, joins, and pattern matching over vast periods. This state can be managed in various state backends (e.g., in-memory, RocksDB), offering trade-offs between performance and durability.
- Checkpointing and Fault Tolerance: Flink achieves exactly-once processing semantics through its robust asynchronous checkpointing mechanism. Periodically, the entire state of a Flink application is captured and persisted to durable storage. In case of a failure, the application can be restored from the latest successful checkpoint, guaranteeing no data loss and consistent results.
- Windowing: For analyzing unbounded streams, Flink provides flexible windowing mechanisms. These allow operations to be performed on finite “windows” of data, defined by time (tumbling, sliding, session windows) or count. This is essential for use cases like aggregating metrics over specific intervals or detecting patterns within a burst of events.
- Connectors: Flink boasts a rich ecosystem of connectors to various data sources and sinks, including Apache Kafka, Apache Kinesis, file systems (HDFS, S3), relational databases, and NoSQL stores. This extensive connectivity ensures that Flink applications can easily integrate into existing data infrastructures.
- APIs: Flink offers several high-level APIs, including the DataStream API for fine-grained control over stream processing logic and the Table API & SQL for declarative stream and batch processing, appealing to data analysts and engineers familiar with SQL.
Challenges and Barriers to Adoption
Despite its powerful capabilities, adopting Flink Stream Processing is not without its hurdles. One significant challenge is the inherent complexity of designing and managing stateful computations, especially for those new to stream processing paradigms. Correctly handling state, watermarks, and windowing requires a deep understanding of Flink’s internals to avoid subtle bugs or performance bottlenecks.
Operational overhead is another consideration. Deploying, monitoring, and debugging distributed stream processing applications can be complex. While Flink offers tools and metrics, ensuring high availability, optimal resource utilization, and swift recovery from failures demands specialized operational expertise. The learning curve for developers and operations teams can be steep, as it requires a shift in mindset from traditional batch processing to continuous, event-driven architectures. Debugging in a distributed, asynchronous environment also presents unique difficulties, as tracing events across multiple operators and machines can be challenging. Finally, ensuring proper data governance and handling schema evolution in continuously flowing data requires careful planning and robust tooling, as changes to data formats can break downstream applications.
Business Value and ROI of Flink Stream Processing
The investment in Flink Stream Processing yields substantial business value and a compelling return on investment across numerous industries.
- Real-time Insights & Faster Decision-Making: Flink enables businesses to gain immediate insights from data, facilitating instantaneous responses. This translates to quicker fraud detection in financial services, personalized recommendations for e-commerce customers, real-time anomaly detection in IoT environments for predictive maintenance, and dynamic pricing adjustments in response to market conditions.
- Operational Efficiency & Automation: By enabling continuous ETL pipelines, Flink streamlines data ingestion, transformation, and loading processes. This reduces the latency and resource consumption associated with traditional batch jobs, automating data flows and ensuring that downstream systems always have access to the freshest data.
- Enhanced Customer Experience: Real-time processing allows for highly personalized and responsive customer interactions. From instant alerts and tailored promotions to immediate feedback on service usage, Flink helps create more engaging and satisfactory customer journeys.
- Reduced Total Cost of Ownership (TCO): By optimizing data processing pipelines, reducing latency, and enabling efficient resource utilization, Flink can lead to significant cost savings. Its fault-tolerant nature also minimizes downtime and data reprocessing costs.
- High-Quality Data for AI/ML: Flink provides a robust foundation for real-time machine learning. By delivering clean, transformed, and timely data, it feeds MLOps pipelines with the high-quality input needed for real-time model training, serving, and continuous re-training, ensuring AI models are always current and effective.
Comparative Insight: Flink vs. Traditional and Contemporary Alternatives
To fully appreciate the significance of Flink Stream Processing, it’s essential to compare its capabilities against both traditional data architectures and other modern stream processing frameworks.
Flink vs. Traditional Data Warehouses and Data Lakes
Traditional data warehouses and data lakes are designed primarily for data at rest. They excel at storing vast amounts of historical data and performing complex analytical queries over batch-processed datasets. However, their fundamental architecture is not suited for real-time processing of continuous data streams. Data must be ingested, transformed, and loaded in batches, leading to inherent latency that can range from minutes to hours.
Flink, conversely, operates on data in motion. It processes events as they arrive, enabling immediate computations and actions. While data warehouses provide historical context for long-term strategic decisions, Flink provides immediate operational intelligence, allowing businesses to react tactically in the moment. Flink complements these traditional systems by pre-processing and enriching data streams before they land in a data lake or warehouse, or by feeding real-time insights derived from streaming data back into operational systems. The paradigm shift is from “storing to analyze” to “analyzing as it arrives.”
Flink vs. Modern Stream Processing Competitors
The landscape of stream processing includes several powerful alternatives, each with its own strengths and niches.
- Apache Spark Streaming: Often considered a direct competitor, Spark Streaming operates on a micro-batch model. It divides continuous streams into small batches, which are then processed using Spark’s batch engine. While highly scalable and fault-tolerant, this micro-batch approach introduces inherent latency compared to Flink’s true record-at-a-time processing. Flink generally offers lower latency and more sophisticated event-time processing and state management capabilities, making it superior for applications requiring millisecond-level responsiveness and complex stateful computations.
- Apache Kafka Streams: Kafka Streams is a client library for building applications and microservices that process data stored in Kafka. It’s tightly integrated with Kafka and offers a lightweight, embedded solution for stream processing within a single application. While excellent for Kafka-centric use cases and simpler stream processing tasks, Flink is a full-fledged distributed stream processing engine, offering more advanced features like complex windowing, custom state backends, and broader connector support beyond Kafka. Flink can also serve as a more powerful processing layer on top of Kafka.
- Apache Beam: Apache Beam provides a unified programming model for both batch and stream processing, allowing developers to write pipelines that can be executed on various distributed processing backends, including Flink, Spark, and Google Cloud Dataflow. While Beam offers an abstract API that promotes portability, Flink serves as a powerful “runner” for Beam pipelines. If the primary need is for the best performance and deepest control over stream-specific features, directly using Flink’s APIs might be preferred, especially for complex stateful applications where Flink’s native capabilities shine.
In summary, while alternatives exist, Flink’s true stream processing capabilities, sophisticated state management, and robust event-time semantics position it as a leader for mission-critical, low-latency, and highly accurate real-time applications.
World2Data Verdict: The Strategic Imperative of Flink Stream Processing
As the volume, velocity, and variety of data continue their exponential growth, the strategic importance of real-time data processing can no longer be understated. World2Data’s analysis indicates that Flink Stream Processing is not merely an optional enhancement but a foundational technology for enterprises striving for true competitive advantage in the digital economy. Its unparalleled ability to process continuous data streams with high throughput, low latency, and exactly-once semantics makes it indispensable for building responsive, intelligent, and resilient applications. We recommend that organizations prioritize the adoption and mastery of Flink, particularly those in sectors requiring immediate insights for fraud detection, personalized customer experiences, IoT analytics, and sophisticated MLOps workflows. The future of data lies in its immediate utility, and Flink stands as a pivotal enabler of this real-time paradigm. Embracing Flink today will unlock transformative capabilities, driving innovation and empowering data-driven decisions at the speed of business.

{kind=link}