


Applying GPUs to Accelerate Big Data: A Paradigm Shift for Modern Analytics
In an era defined by an exponential surge in data, the ability to process, analyze, and extract insights rapidly has become a critical competitive differentiator. Applying GPUs to Accelerate Big Data represents a profound paradigm shift, moving beyond the inherent limitations of traditional CPU-centric architectures. This deep dive explores how GPU Big Data Acceleration is not just enhancing, but revolutionizing, the landscape of data processing frameworks, offering unparalleled speed and efficiency for the most demanding workloads.
Introduction: The Imperative for GPU Big Data Acceleration
The volume, velocity, and variety of big data continue to escalate at an unprecedented rate. From real-time IoT streams to petabyte-scale data lakes, organizations are grappling with the challenge of deriving timely value from their information assets. Traditional CPU-based systems, while versatile, often struggle to keep pace, encountering bottlenecks when faced with highly parallelizable computational tasks inherent in big data analytics. This is where GPU Big Data Acceleration steps in, offering a transformative solution.
GPUs, or Graphics Processing Units, were originally designed for rendering graphics, a task that demands massive parallel computation. This fundamental architectural advantage—thousands of smaller, efficient cores working in unison—makes them exceptionally well-suited for a wide array of data processing challenges that extend far beyond graphical rendering. For World2Data.com, understanding and leveraging this technology is paramount, as it underpins the next generation of data processing frameworks and AI/ML capabilities. Our objective in this article is to dissect the technical underpinnings, business value, and comparative advantages of integrating GPUs into big data workflows, highlighting why GPU Big Data Acceleration is no longer a niche concept but a strategic imperative.
The core technology enabling this acceleration is Massively Parallel Processing on GPUs, often facilitated by frameworks like NVIDIA CUDA and RAPIDS. These tools allow developers and data scientists to harness the raw power of GPUs for data manipulation, machine learning model training, and complex simulations. While the primary focus of GPU acceleration is performance, its implications ripple through various aspects of data strategy, from cost efficiency to the agility of AI deployments.
Core Breakdown: The Architecture of GPU Big Data Acceleration
The efficacy of GPU Big Data Acceleration stems from its foundational architecture: massively parallel processing. Unlike CPUs, which are optimized for sequential processing with a few powerful cores, GPUs feature hundreds to thousands of smaller, specialized cores designed to handle thousands of threads simultaneously. This design is inherently advantageous for operations common in big data analytics, such as matrix multiplications, filtering, sorting, and aggregations, where the same operation needs to be applied to many data points concurrently.
The journey of data acceleration typically begins with specialized software frameworks that abstract the complexities of GPU programming. NVIDIA’s CUDA (Compute Unified Device Architecture) is the foundational platform that enables developers to write programs that leverage GPU cores directly. Building upon CUDA, the RAPIDS suite of open-source software libraries has emerged as a game-changer for data science and analytics workflows. RAPIDS provides GPU-accelerated equivalents for popular Python libraries:
- cuDF: A GPU-accelerated DataFrame library that mimics pandas, enabling fast loading, manipulation, and querying of tabular data directly on the GPU.
- cuML: A suite of GPU-accelerated machine learning algorithms, offering significant speedups for common tasks like clustering, classification, and regression compared to scikit-learn on CPUs.
- cuGraph: For network analysis and graph algorithms, bringing GPU acceleration to complex graph computations.
- Dask-GPU: Integrates with Dask to enable distributed computing across multiple GPUs and machines, extending scalability.
Beyond these, native acceleration for popular ML/DL libraries like TensorFlow and PyTorch is a primary driver for GPU adoption in AI. GPUs dramatically reduce the time required to train deep neural networks on vast datasets, transforming training cycles from days or weeks to hours or minutes. This allows for more experimentation, faster model iteration, and ultimately, more robust and performant AI models.
Challenges and Barriers to Adoption
Despite the clear advantages, the widespread adoption of GPU Big Data Acceleration faces several challenges:
- Programming Complexity: While frameworks like RAPIDS simplify the process, optimizing code for GPUs still requires a different mindset and skillset than traditional CPU programming. Data scientists and engineers need to understand concepts like memory hierarchies, data transfer, and kernel execution.
- Data Transfer Bottlenecks: The speed of data transfer between CPU memory (host) and GPU memory (device) can become a bottleneck if not managed carefully. Efficient data loading and keeping data on the GPU for as long as possible are crucial for maximizing performance gains.
- Cost of Hardware: High-performance GPUs represent a significant upfront investment compared to commodity CPUs. While cloud providers offer GPU instances, continuous usage can still be costly.
- Ecosystem Maturity: While rapidly evolving, the GPU ecosystem, particularly for big data processing beyond deep learning, is still maturing compared to the decades-old CPU-based distributed computing landscape (e.g., Apache Spark). Not all libraries or tools have direct GPU equivalents.
- Scalability: Scaling GPU workloads across multiple machines efficiently requires sophisticated orchestration and distributed computing frameworks (e.g., Dask, Spark on Kubernetes with GPUs), adding complexity to infrastructure management.
- Data Governance Integration: While GPUs accelerate processing, they don’t inherently provide data governance features. These capabilities, such as access control, data lineage, and compliance auditing, must be managed by the overarching data platform. Ensuring that accelerated data pipelines adhere to organizational governance policies requires careful integration with existing data security and management layers.
Business Value and ROI
The return on investment (ROI) from implementing GPU Big Data Acceleration is multifaceted and often significant:
- Faster Time to Insight: Dramatically reduced processing times mean businesses can analyze larger datasets more frequently, enabling real-time analytics, faster fraud detection, and quicker market trend identification.
- Accelerated AI/ML Development: For AI-driven organizations, faster model training and inference cycles lead to quicker deployment of new AI applications, improved model accuracy through more iterations, and enhanced competitiveness. This directly translates to faster product innovation and improved customer experiences.
- Cost Efficiency (Total Cost of Ownership – TCO): While GPUs have higher upfront costs, their superior processing speed often means fewer machines are needed to complete a given workload within a specified timeframe. This can lead to lower operational costs (less power, cooling, fewer licenses) and a smaller data center footprint over time, especially for highly demanding tasks.
- Enhanced Data Quality for AI: The ability to process more data and run more complex feature engineering pipelines rapidly allows for richer, higher-quality datasets to feed AI models, leading to better model performance and reliability.
- Competitive Advantage: Organizations that can extract insights faster and deploy AI solutions more rapidly gain a significant edge in dynamic markets, allowing them to respond to changes, personalize offerings, and innovate ahead of competitors.
Comparative Insight: GPU Big Data Acceleration vs. Traditional Data Architectures
Understanding the unique value proposition of GPU Big Data Acceleration requires a comparison with established data processing paradigms. Historically, big data analytics has relied heavily on CPU-based distributed computing frameworks like Apache Hadoop and Apache Spark, or traditional data warehouses. Each has its strengths and limitations when pitted against the parallel processing power of GPUs.
CPU-based Distributed Computing (e.g., Apache Spark)
CPU-based distributed computing, exemplified by Apache Spark, excels at processing large datasets across clusters of commodity machines. It offers excellent fault tolerance, a rich ecosystem, and flexibility for various workloads (batch processing, streaming, SQL, graph processing). However, for computationally intensive tasks—especially those involving linear algebra, complex numerical simulations, or deep learning—CPUs can become a bottleneck. Their fewer, more powerful cores are less efficient at the massive parallel operations that GPUs are built for. While Spark has made strides in supporting GPUs, the core execution engine remains CPU-centric, often requiring data transfer between CPU and GPU memory, which can negate some performance gains if not managed carefully.
Traditional Data Lake and Data Warehouse
Traditional data warehouses (e.g., Teradata, Oracle Exadata) are optimized for structured data, complex SQL queries, and reporting, offering strong ACID properties and mature governance. Data lakes, typically built on cloud object storage or HDFS, offer flexibility for unstructured and semi-structured data, acting as vast repositories. Neither of these architectures natively provides the granular, massively parallel computational power of GPUs at the processing layer. While they can store data that is later processed by GPU-accelerated systems, they are not designed for the real-time, compute-heavy transformations or AI model training that GPUs enable. Integrating GPUs with these systems usually involves offloading data to a dedicated GPU-accelerated cluster for processing, then potentially re-ingesting results.
Specialized Accelerators: TPUs and FPGAs
The landscape of hardware acceleration also includes Google’s Tensor Processing Units (TPUs) and Field-Programmable Gate Arrays (FPGAs).
- TPUs: Specifically designed by Google for accelerating machine learning workloads, particularly neural network computations. They are highly optimized for matrix operations, offering impressive performance for deep learning training and inference within specific frameworks (TensorFlow, JAX). While extremely powerful for their niche, TPUs are generally less versatile than GPUs for general-purpose big data analytics tasks outside of deep learning, and their ecosystem is less open than that of NVIDIA GPUs.
- FPGAs: Offer extreme flexibility and energy efficiency. FPGAs can be reconfigured at the hardware level to perform specific tasks, making them ideal for specialized, latency-sensitive applications like high-frequency trading or custom signal processing. However, their programming model is significantly more complex, requiring hardware description languages, and they generally lack the raw compute density and ease of programming offered by GPUs for broad big data and AI workloads.
In comparison, GPU Big Data Acceleration strikes a balance between versatility and performance. GPUs provide general-purpose parallel computing power that can be applied across a wide spectrum of big data tasks—from ETL and data cleaning to complex statistical modeling and deep learning—with a more accessible programming model than FPGAs and broader applicability than TPUs. This makes them a compelling choice for organizations seeking a unified acceleration strategy for their diverse big data and AI workloads.
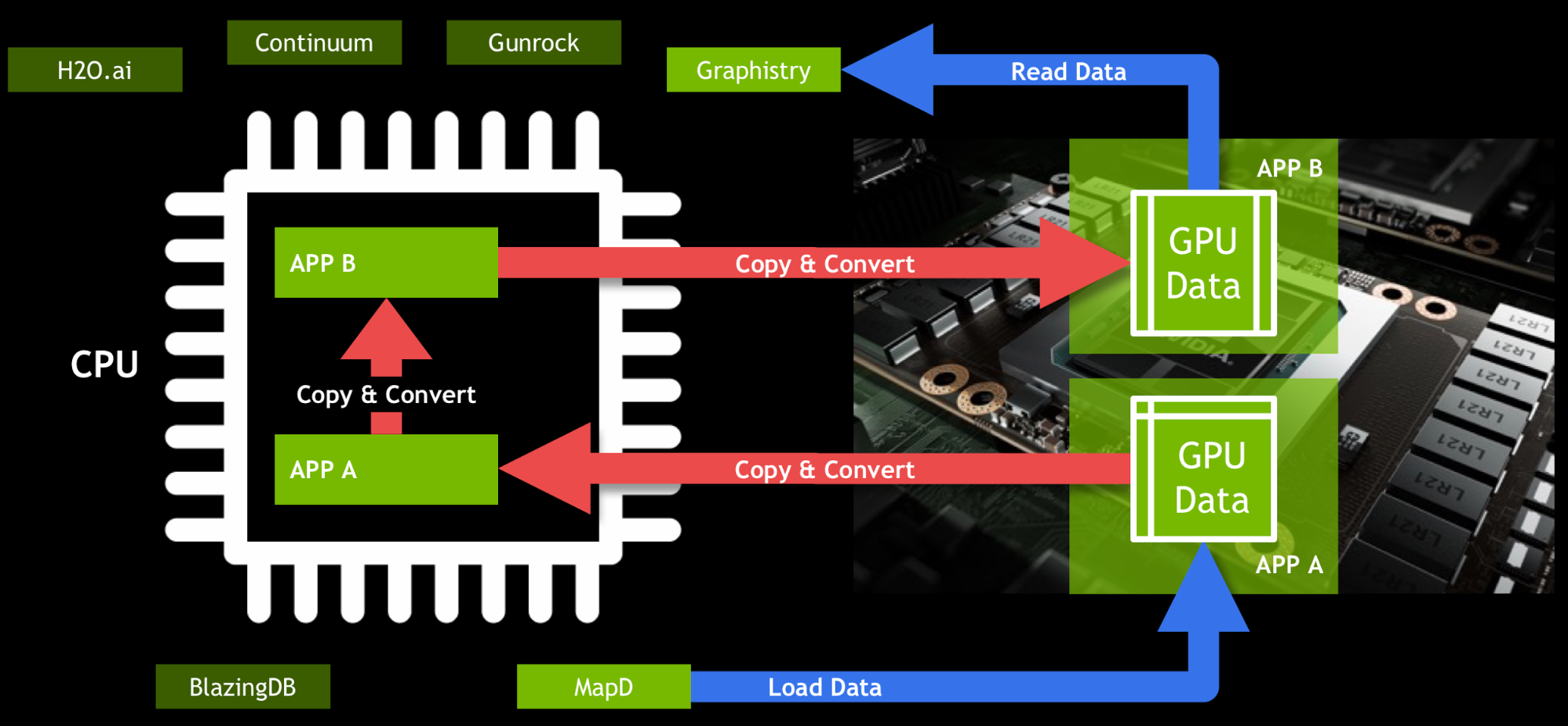
World2Data Verdict: The Future is Hybrid and Accelerated
The trajectory of data processing is unequivocally moving towards increased acceleration, and GPU Big Data Acceleration is at the forefront of this evolution. World2Data.com believes that the future of enterprise data platforms will be characterized by a hybrid approach, strategically integrating GPU-accelerated components alongside existing CPU-based distributed systems and data storage solutions.
Our recommendation is for organizations to proactively evaluate and integrate GPU acceleration into their data strategies, focusing on workloads that demand high computational throughput. This includes, but is not limited to, real-time analytics, complex feature engineering, large-scale machine learning model training and inference, and graph analytics. Begin with pilot projects using frameworks like RAPIDS to demonstrate tangible performance gains and ROI, then gradually expand integration into production pipelines.
Key to successful adoption will be investing in talent development—upskilling data scientists and engineers in GPU programming paradigms and optimizing data pipelines for efficient data transfer and processing. Furthermore, cloud providers are making GPU resources increasingly accessible and elastic, reducing the barrier to entry for many enterprises.
The continuous advancements in GPU hardware, coupled with the rapid evolution of software ecosystems like CUDA and RAPIDS, promise even greater efficiencies and broader applicability in the coming years. For any enterprise serious about maximizing value from its data assets and gaining a decisive competitive edge through AI, embracing GPU Big Data Acceleration is not merely an option, but an essential strategic imperative for innovation and sustainable growth. The era of massively parallel processing for data-intensive workloads is here, and those who harness its power will redefine the limits of what’s possible with big data.

{kind=link}