


Kafka and the Streaming Data Ecosystem: Powering Real-time Analytics and Event-Driven Architectures
- Platform Category: Distributed Event Streaming Platform
- Core Technology/Architecture: Open Source, Distributed Commit Log Architecture
- Key Data Governance Feature: Schema Registry for Schema Enforcement and Evolution
- Primary AI/ML Integration: Integration with ML frameworks (e.g., TensorFlow, Spark MLlib) for real-time feature engineering and model serving
- Main Competitors/Alternatives: Amazon Kinesis, Google Cloud Pub/Sub, Azure Event Hubs, Apache Pulsar, Redpanda
Apache Kafka has become the cornerstone of modern data infrastructures, fundamentally transforming how organizations manage and process information. As the leading distributed event streaming platform, Kafka provides an unparalleled backbone for real-time data flow, powering applications that demand instantaneous insights and continuous data processing. This article delves into the architecture, components, and profound impact of the Kafka Streaming Data Ecosystem, exploring its pivotal role in enabling scalable, fault-tolerant, and high-performance data pipelines.
Introduction: The Ascendance of Real-time Data with Kafka
In an era defined by data immediacy, the ability to process and react to information in real time is no longer a luxury but a strategic imperative. Traditional batch processing systems, while effective for historical analysis, often fall short in meeting the demands of modern applications that require instant insights, continuous feedback loops, and dynamic decision-making. This critical gap has propelled Apache Kafka to the forefront of data architecture. Originating at LinkedIn, Kafka was designed from the ground up to handle high-volume, low-latency data streams reliably and at scale. It offers a robust, fault-tolerant, and highly performant platform for publishing, subscribing to, storing, and processing streams of records. As enterprises increasingly shift towards event-driven architectures and real-time analytics, understanding the depth and breadth of the Kafka Streaming Data Ecosystem becomes paramount for any organization aiming to harness the full potential of its data assets.
This article aims to provide a comprehensive analysis of Kafka’s core functionalities, its expansive ecosystem components, the challenges organizations might face during its adoption, and the significant business value it delivers. We will also draw a comparison between Kafka’s capabilities and traditional data warehousing and data lake paradigms, culminating in World2Data’s expert verdict on its future trajectory and strategic importance.
Core Breakdown: Apache Kafka’s Architecture and the Streaming Data Ecosystem
At its foundation, Kafka operates as a distributed commit log, designed for high-throughput, low-latency messaging, ensuring both message durability and guaranteed order within partitions. This unique architecture positions Kafka as the central nervous system for data streams, seamlessly integrating data from diverse sources and acting as a real-time data pipeline.
Understanding Apache Kafka’s Core Functionality
The core of Kafka is built upon several fundamental concepts:
- Brokers: Kafka clusters consist of one or more servers (brokers) that store data. Each broker manages partitions of topics and handles requests from producers and consumers.
- Topics: Streams of records are organized into topics. Topics are analogous to tables in a database or folders in a file system, categorizing different types of data streams.
- Partitions: Topics are divided into partitions, which are ordered, immutable sequences of records. Each record in a partition is assigned a sequential ID number called an offset. Partitions enable parallelism and scalability.
- Producers: Applications that publish (write) data to Kafka topics. Producers decide which partition a record belongs to, often using a key for consistent assignment.
- Consumers: Applications that subscribe to (read) data from Kafka topics. Consumers read data from specific partitions within a topic and keep track of the offset of the last record consumed.
- Consumer Groups: For scalability and fault tolerance, consumers typically operate within consumer groups. Each message in a topic partition is delivered to only one consumer instance within a consumer group, allowing for parallel processing of data streams.
- Replication: Kafka provides fault tolerance by replicating topic partitions across multiple brokers. If a broker fails, Kafka can automatically failover to a replica, ensuring data availability and durability.
Key Components of the Expanded Kafka Streaming Data Ecosystem
The strength of Kafka lies not only in its core but also in its rich and evolving ecosystem:
- Kafka Connect: A framework for connecting Kafka with external systems such as databases, key-value stores, search indexes, and file systems. Connectors simplify the integration of Kafka into existing data infrastructures, enabling scalable and reliable data import and export. It supports both source connectors (importing data into Kafka) and sink connectors (exporting data from Kafka).
- Kafka Streams API: A client-side library for building sophisticated stream processing applications and microservices directly within Kafka. It allows developers to perform real-time transformations, aggregations, joins, and windowing operations on data stored in Kafka topics, providing capabilities for both stateful and stateless processing.
- ksqlDB: An event streaming database that allows you to build real-time applications and microservices using a familiar SQL-like interface. With ksqlDB, users can perform complex stream processing tasks, create materialized views, and build event-driven applications without writing extensive code. It democratizes access to stream processing for a broader audience.
- Schema Registry: A crucial component for data governance within the Kafka Streaming Data Ecosystem. Schema Registry stores a versioned history of schemas for Kafka topics, allowing producers and consumers to validate data against a predefined schema. This ensures data quality, compatibility, and evolutionary resilience, preventing issues like data drift and enabling graceful schema evolution.
- ZooKeeper / Kraft: Historically, ZooKeeper served as the distributed coordination service for Kafka, managing broker membership, topic configuration, and controller election. More recently, Kafka has introduced the Kafka Raft (KRaft) protocol, aiming to remove the ZooKeeper dependency and simplify Kafka deployments by integrating metadata management directly into Kafka brokers.
Challenges and Barriers to Adoption
While the benefits are significant, adopting Kafka presents several challenges:
- Operational Complexity: Deploying, managing, monitoring, and scaling a Kafka cluster can be complex, especially for large-scale, production environments. This often requires specialized expertise in distributed systems.
- Data Governance and Schema Management: Although Schema Registry helps, establishing robust data governance policies and managing schema evolution across numerous topics and applications requires careful planning and enforcement. Without it, data quality issues can quickly arise.
- Debugging and Troubleshooting: Diagnosing issues in a distributed streaming system like Kafka, with multiple producers, brokers, and consumers, can be challenging due to the asynchronous nature of message flow and potential for network latency.
- Resource Management and Cost Optimization: Running Kafka at scale can be resource-intensive, requiring careful consideration of CPU, memory, and storage. Optimizing cluster configuration to balance performance and cost is a continuous effort.
- Integration with Legacy Systems: While Kafka Connect simplifies many integrations, connecting with highly custom or archaic legacy systems can still pose significant engineering challenges.
- Data Latency vs. Throughput Trade-offs: Configuring Kafka for optimal performance often involves trade-offs between end-to-end latency and overall throughput, requiring fine-tuning based on specific use cases.
Business Value and Return on Investment (ROI)
Despite the challenges, the ROI from implementing Kafka is often substantial:
- Real-time Analytics and Decision-Making: Kafka enables organizations to capture, process, and analyze data as it’s generated, facilitating immediate insights for fraud detection, anomaly detection, personalized recommendations, and dynamic pricing strategies. This directly translates to faster, more informed business decisions.
- Powering Event-Driven Microservices: Kafka serves as an ideal backbone for event-driven architectures, allowing microservices to communicate asynchronously through events. This improves system resilience, scalability, and modularity, leading to more agile development cycles and easier maintenance.
- Streamlined Data Pipelines: By acting as a central hub for all data streams, Kafka simplifies data ingestion and distribution, reducing the complexity of traditional ETL processes and replacing batch-oriented data movement with real-time flows. This minimizes data latency and improves operational efficiency.
- Foundation for AI/ML Real-time Capabilities: Kafka is instrumental in building real-time feature engineering pipelines for machine learning models. It can feed fresh, high-quality data to AI models for continuous learning and real-time inference, significantly enhancing the accuracy and responsiveness of predictive analytics. This integration with ML frameworks for real-time feature engineering and model serving is a primary advantage.
- Enhanced Customer Experience: Real-time processing of customer interactions allows businesses to deliver personalized experiences, dynamic content, and immediate support, significantly improving customer satisfaction and loyalty.
- Operational Efficiency and Resilience: Kafka’s fault-tolerant and scalable architecture ensures continuous data availability and processing, minimizing downtime and improving the overall reliability of data infrastructure.
Comparative Insight: Kafka vs. Traditional Data Lakes and Data Warehouses
While Kafka, data lakes, and data warehouses all play crucial roles in an organization’s data strategy, they serve distinct purposes and operate on different paradigms. Understanding these differences is key to designing a holistic data architecture.
- Traditional Data Warehouses: These systems are optimized for structured, historical data analysis and reporting. They typically involve batch ETL processes to load data into a schema-on-write model, focusing on OLAP (Online Analytical Processing) queries. Data warehouses excel at complex analytical queries over large historical datasets, but their batch nature makes them ill-suited for real-time insights.
- Traditional Data Lakes: Data lakes store vast quantities of raw data in its native format, regardless of structure, using a schema-on-read approach. They are highly flexible and cost-effective for storing diverse data types, often serving as a staging ground for big data analytics. While they can handle varied data, data lakes primarily support batch processing for analytics, making real-time analysis challenging without additional tools.
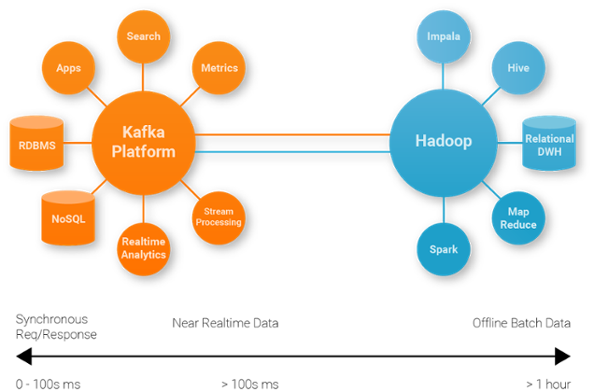
- Kafka’s Distinct Role: Kafka, in contrast, focuses on data in motion – it’s an event streaming platform designed for real-time data ingestion, processing, and distribution. Its primary strength lies in handling high-velocity, high-volume data streams with low latency. Kafka provides the immediate backbone for operational analytics, event-driven applications, and feeding real-time data to other systems. It is not inherently designed for long-term historical storage or complex ad-hoc querying of large historical datasets like data warehouses or data lakes.
Rather than being competitors, these technologies are often complementary. Kafka frequently serves as the real-time ingestion layer, acting as a conduit that streams data into data lakes for long-term storage and historical analysis, or into data warehouses for structured reporting. In modern data architectures, Kafka often feeds real-time stream processing engines (like Kafka Streams or ksqlDB) for immediate operational insights, while simultaneously populating data lakes and warehouses for comprehensive analytical workloads. This hybrid approach leverages the strengths of each platform, creating a powerful, multi-modal data infrastructure capable of supporting both real-time operational needs and deep historical analytics.
World2Data Verdict: The Unyielding Momentum of Kafka in Real-time Enterprises
The journey through the intricate architecture and expansive functionalities of Apache Kafka clearly underscores its status as an indispensable technology for any organization striving for data-driven excellence. World2Data.com views Kafka not merely as a messaging queue, but as the foundational element of modern enterprise data fabric, enabling a paradigm shift from static, batch-oriented processes to dynamic, event-driven operations. Its unparalleled scalability, fault tolerance, and rich ecosystem components – from Kafka Connect for seamless integration to Kafka Streams and ksqlDB for powerful in-stream processing – position it as the go-to solution for real-time data challenges.
Looking ahead, we predict that Kafka’s role will only expand. As cloud-native patterns become dominant and serverless computing gains traction, Kafka will continue to be the bridge, connecting disparate services and data sources in real time. Its integration with advanced AI and machine learning initiatives, facilitating real-time feature stores and continuous model retraining, will be a critical differentiator for competitive enterprises. For organizations serious about leveraging their data for immediate business advantage, investing in and mastering the Kafka Streaming Data Ecosystem is not just a technological choice, but a strategic imperative that promises sustained innovation, superior customer experiences, and robust operational resilience in an increasingly real-time world.

{kind=link}