


Lakehouse vs Warehouse: A Deep Dive into Modern Data Architectures
The debate of Lakehouse vs Warehouse represents a pivotal discussion in modern data management, driven by the escalating demands for flexible, scalable, and AI-ready data infrastructures. Organizations grappling with diverse data types and complex analytical workloads are increasingly evaluating these two powerful paradigms. Understanding the fundamental differences and respective strengths of the Lakehouse vs Warehouse model is crucial for making informed strategic decisions that impact an enterprise’s ability to derive timely and actionable insights from its ever-growing data assets.
Introduction: Navigating the Evolving Data Landscape
In today’s data-driven world, the ability to efficiently store, process, and analyze vast quantities of data is paramount for competitive advantage. For decades, the Data Warehouse stood as the undisputed champion for structured data analysis and business intelligence (BI). However, the explosion of unstructured and semi-structured data, coupled with the rising prominence of machine learning (ML) and artificial intelligence (AI) workloads, exposed limitations in the traditional Data Warehouse architecture. This evolution spurred the development of the Data Lake, offering unparalleled storage flexibility and cost-effectiveness for raw data. Yet, Data Lakes often lacked the transactional consistency, schema enforcement, and robust governance features necessary for mission-critical BI. Enter the Data Lakehouse – an innovative architecture designed to combine the best attributes of both Data Lakes and Data Warehouses, promising a unified platform for all data types and analytical needs. This article provides a comprehensive comparison of Lakehouse vs Warehouse, dissecting their core technologies, use cases, and strategic implications for modern enterprises.
Core Breakdown: Dissecting Lakehouse and Warehouse Architectures
To fully appreciate the distinction between Lakehouse vs Warehouse, it’s essential to examine their foundational principles, technological stacks, and operational characteristics.
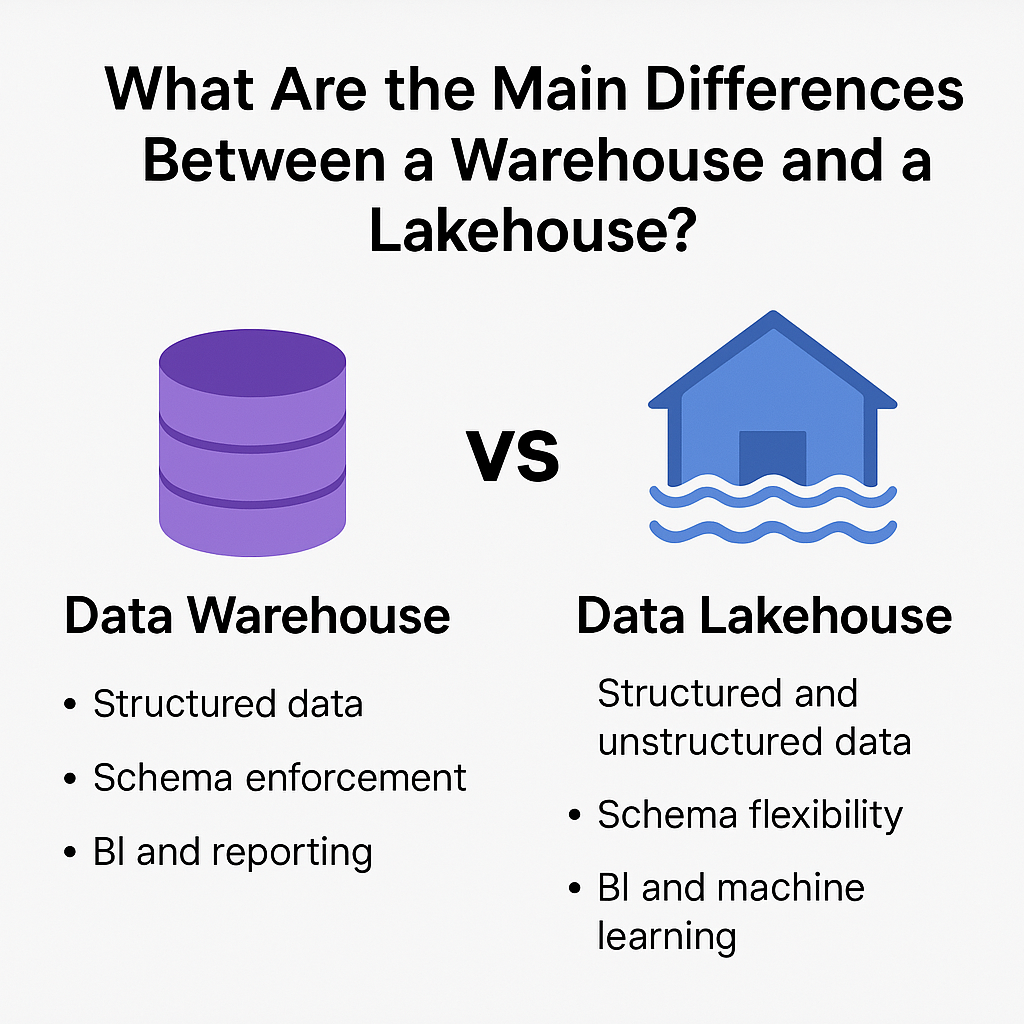
Data Warehouse: The Pillar of Structured Analytics
The traditional Data Warehouse has been the bedrock of enterprise analytics for decades, designed specifically for efficient querying and reporting on structured, clean data. Its architecture is characterized by:
- Platform Category: Data Warehouse
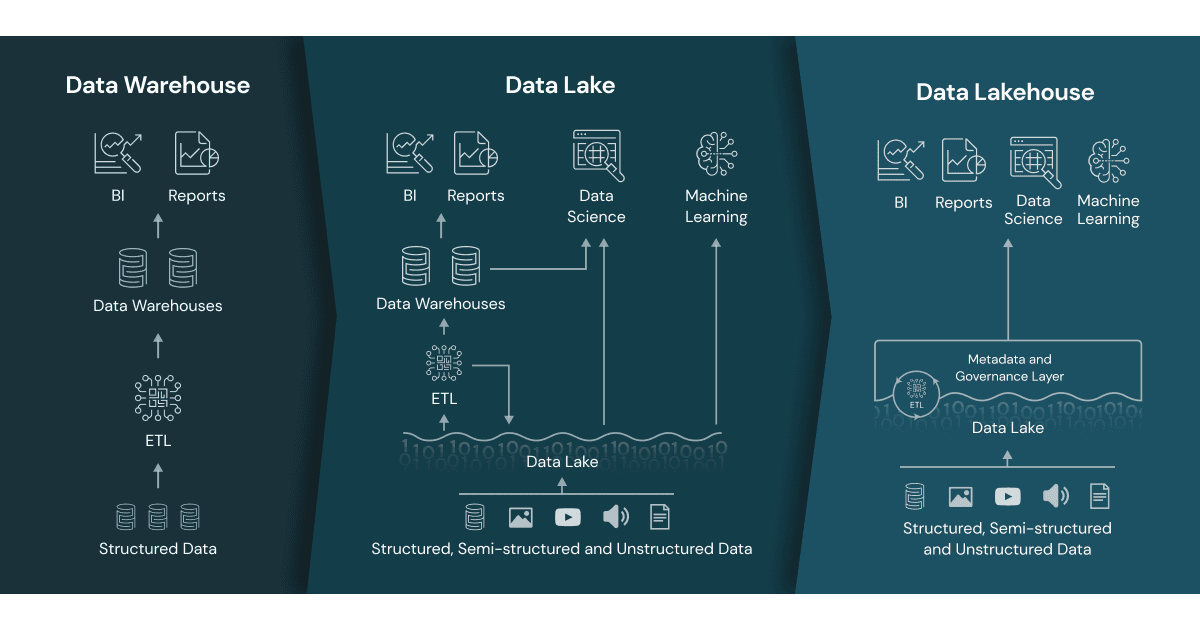
- Core Technology/Architecture: At its heart, a Data Warehouse employs Massively Parallel Processing (MPP) architectures, distributing data and query processing across multiple nodes for high performance on complex analytical queries. It operates on a schema-on-write principle, meaning data must conform to a predefined schema upon ingestion. This often involves extensive Extract, Transform, Load (ETL) processes to cleanse and structure data before it enters the warehouse. Data is typically stored in proprietary data formats optimized for columnar storage and query performance within the warehouse vendor’s ecosystem.
- Key Data Governance Feature: Data Warehouses offer robust Role-Based Access Control (RBAC) mechanisms, allowing granular control over who can access specific tables, rows, and even columns. This ensures high data integrity and compliance with regulatory requirements, making them ideal for financial reporting and sensitive data analytics.
- Primary AI/ML Integration: Historically, AI/ML integration with Data Warehouses has been challenging. Due to their structured nature and proprietary formats, Data Warehouses typically require data to be exported to separate systems (e.g., data lakes, specialized ML platforms) for ML model training and inference. This creates data silos and can introduce latency and complexity in the MLOps pipeline.
- Main Competitors/Alternatives: Data Lakehouse, Data Lake, Data Marts.
- Strengths: High performance for structured SQL queries, strong data consistency (ACID properties), mature ecosystem for BI tools, robust security and governance for structured data.
- Weaknesses: High cost for large volumes of data, lack of flexibility for semi-structured/unstructured data, complex and time-consuming ETL processes, poor native support for real-time data and advanced analytics/ML.
Data Lakehouse: Unifying Data and Analytics
The Data Lakehouse emerges as a next-generation architecture that attempts to bridge the gap between the flexibility of a Data Lake and the reliability of a Data Warehouse. It aims to provide a single platform for all data types and workloads, from traditional BI to advanced AI/ML. Key characteristics include:
- Platform Category: Data Lakehouse
- Core Technology/Architecture: The Data Lakehouse is built upon low-cost, scalable cloud object storage (e.g., S3, ADLS, GCS), leveraging open-source table formats such as Apache Iceberg, Delta Lake, and Apache Hudi. These formats add crucial data warehouse-like features directly to the data lake, including transactional capabilities (ACID), schema enforcement, schema evolution, and time travel (data versioning). It supports both schema-on-read for raw, exploratory data and schema-on-write for curated, structured data.
- Key Data Governance Feature: A major advantage of the Data Lakehouse is its ability to provide a Unified Data Catalog with ACID transactions and time travel. This allows for consistent data access, reliable updates, and the ability to revert to previous data states, significantly enhancing data quality and governance across diverse data assets.
- Primary AI/ML Integration: One of the most compelling aspects of the Data Lakehouse is its seamless integration with AI/ML workloads. It allows direct access for ML/AI model training and inference on the same single copy of data used for BI. This eliminates data movement, reduces complexity, and accelerates the MLOps lifecycle, enabling faster model deployment and iteration. The open formats also make it easy to integrate with various ML frameworks and tools.
- Main Competitors/Alternatives: Data Warehouse, Data Lake.
- Strengths: Cost-effective storage, handles all data types (structured, semi-structured, unstructured), supports BI and AI/ML workloads on a single platform, ACID transactions and schema capabilities, open formats prevent vendor lock-in, excellent scalability and flexibility.
- Weaknesses: Relative immaturity compared to Data Warehouses, requires a good understanding of underlying open-source technologies, complex to implement and manage without robust tooling, performance for highly specialized BI queries may not always match highly optimized proprietary warehouses.
Challenges and Barriers to Adoption
Adopting either a Data Warehouse or a Lakehouse architecture comes with its unique set of challenges:
- Data Warehouse Challenges:
- Scalability and Cost: Traditional Data Warehouses can become prohibitively expensive and difficult to scale linearly with increasing data volumes and users, especially for petabyte-scale analytics.
- Data Variety Limitations: They struggle with non-relational, semi-structured, and unstructured data, which is increasingly prevalent from sources like IoT, social media, and logs. This necessitates separate systems (e.g., data lakes), leading to data silos.
- ETL Complexity: The schema-on-write approach demands significant upfront ETL efforts, which can be time-consuming, resource-intensive, and prone to bottlenecks, delaying time-to-insight.
- MLOps Complexity: As noted, exporting data for ML introduces MLOps complexity, data duplication, and potential inconsistencies between analytical and ML datasets.
- Lakehouse Challenges:
- Maturity and Ecosystem: While rapidly evolving, the Lakehouse ecosystem, particularly around open table formats, is still maturing compared to the decades-old Data Warehouse industry. Tooling and vendor support are growing but may not yet be as comprehensive or deeply integrated across all facets.
- Skill Gap: Implementing and managing a Lakehouse requires expertise in distributed systems, cloud-native services, and open-source technologies (Spark, Delta Lake, Iceberg, Hudi), which can be a skill barrier for some organizations.
- Performance Tuning: While powerful, achieving optimal performance across diverse workloads (BI, ML, streaming) on a Lakehouse often requires careful tuning and optimization of underlying engines and table formats.
- Data Governance Evolution: While providing strong governance features, unifying governance across raw, refined, and curated zones in a single Lakehouse still requires robust policies and disciplined data management practices.
Business Value and ROI
Both architectures deliver significant business value, though in different ways:
- Data Warehouse ROI:
- Reliable BI and Reporting: Provides highly accurate and consistent data for critical business intelligence, financial reporting, and compliance, enabling trusted decision-making based on historical trends.
- Enhanced Data Quality: The rigorous ETL processes and schema enforcement ensure high data quality, reducing errors in reports and analyses.
- Mature Tooling: A rich ecosystem of BI and reporting tools integrates seamlessly, allowing businesses to leverage existing investments and skilled personnel.
- Lakehouse ROI:
- Accelerated Data-to-AI Lifecycle: By unifying data for BI and ML, Lakehouses significantly reduce the time and effort required to prepare data for AI models, leading to faster model deployment and iteration. This enables rapid experimentation and deployment of innovative AI applications.
- Cost Efficiency: Leveraging inexpensive cloud object storage dramatically lowers storage costs compared to proprietary warehouse solutions, especially for large volumes of cold and warm data.
- Unified Analytics Platform: Eliminates data silos, allowing data teams (BI analysts, data scientists, ML engineers) to collaborate on a single, consistent copy of data, fostering greater efficiency and agility.
- Data Quality for AI: Features like ACID transactions, schema enforcement, and time travel ensure high data quality and reliability not just for BI, but critically for training robust and accurate ML models, preventing data drift and improving model performance.
- Future-Proofing: Open formats and cloud-native architecture provide flexibility and prevent vendor lock-in, positioning organizations well for future technological advancements and data scale.
Comparative Insight: Evolving Beyond Traditional Boundaries
The fundamental distinction between Lakehouse vs Warehouse lies in their approach to data diversity and workload unification. A traditional Data Warehouse, with its schema-on-write philosophy and proprietary storage, is inherently optimized for structured data and predictable BI queries. It delivers exceptional performance and strong governance for these specific use cases but falters when faced with the unstructured deluge or the dynamic requirements of advanced analytics and machine learning. Its rigid structure and data duplication needs for AI workloads present significant operational overheads.
Conversely, the Data Lakehouse embraces all data types by building a transactional layer over open-format object storage. It offers the best of both worlds: the cost-effectiveness and flexibility of a data lake combined with the data reliability, ACID transactions, and governance typically associated with a data warehouse. This convergence means that data engineers, BI analysts, and data scientists can all work on the same data, eliminating redundant data copies and complex data pipelines. For modern organizations seeking to operationalize AI and derive insights from truly diverse datasets, the Lakehouse offers a compelling alternative to the disjointed ecosystem often found when pairing a Data Lake with a separate Data Warehouse for different workloads. While a Data Warehouse specializes, a Lakehouse generalizes effectively across a broader spectrum of data management and analytical needs, pushing the boundaries of what a single data platform can achieve.
World2Data Verdict: The Ascendancy of Unified Data Platforms
The detailed comparison of Lakehouse vs Warehouse clearly indicates a paradigm shift in data architecture. While traditional Data Warehouses will continue to hold value for specific, highly structured, and compliance-driven BI environments, the future undeniably belongs to more agile, unified platforms capable of handling the full spectrum of data and analytical workloads. The Data Lakehouse, with its ability to seamlessly integrate structured, semi-structured, and unstructured data, coupled with its robust transactional capabilities and native support for AI/ML, offers a superior foundation for data-driven innovation. World2Data.com recommends that organizations with growing data volumes, diverse data types, and an ambition to rapidly scale their AI and machine learning initiatives should prioritize a strategic move towards a Data Lakehouse architecture. This transition will not only optimize costs and simplify data management but also unlock unparalleled potential for faster insights and transformative business outcomes, making it the preferred choice for forward-thinking enterprises in the coming decade.

{kind=link}