


Metadata Management: Mastering Control and Organization of Enterprise Data for AI & Analytics
Platform Category: Metadata Management Platform, Data Catalog, Data Governance Tool, Data Discovery Platform
Core Technology/Architecture: Knowledge Graph, Automated Metadata Discovery, Machine Learning for Tagging and Classification, Cloud-native, Graph Database
Key Data Governance Feature: Data Lineage, Business Glossary, Data Cataloging, Role-Based Access Control (RBAC), Data Quality Integration, Policy Enforcement
Primary AI/ML Integration: Automated Metadata Tagging, Intelligent Data Discovery and Recommendations, Anomaly Detection for Data Quality, Semantic Search capabilities, Integration with ML pipelines
Main Competitors/Alternatives: Collibra, Informatica Enterprise Data Catalog, Alation, Atlan, IBM Watson Knowledge Catalog, Microsoft Purview
In today’s data-driven landscape, the sheer volume and diversity of information within organizations demand more than mere storage; they require intelligent organization and meticulous control. Metadata Management stands as the lynchpin for achieving this, providing the crucial context needed to transform raw data into actionable intelligence. It’s an indispensable discipline that underpins robust data governance, fuels advanced analytics, and ensures operational efficiency across the entire enterprise, making it a strategic imperative for any forward-thinking business.
Introduction: Unlocking the Value of Enterprise Data with Metadata Management
The digital age has amplified the critical challenge facing modern businesses: effectively controlling and organizing vast quantities of enterprise data. Without a structured approach, data quickly becomes a liability rather than an asset, residing in silos, lacking context, and hindering informed decision-making. This is where Metadata Management emerges as an essential discipline, providing the framework to understand, locate, and govern every piece of data an organization possesses. Our objective in this deep dive is to explore the intricacies of metadata management, its architectural components, the strategic advantages it confers, and how it compares to traditional data approaches, ultimately revealing its transformative power for modern data ecosystems.
Core Breakdown: The Architecture of Effective Metadata Management
Effective Metadata Management involves a sophisticated interplay of technologies and processes designed to collect, store, integrate, and maintain metadata throughout its lifecycle. It moves beyond simple descriptive tags to encompass a dynamic system that provides a 360-degree view of all data assets.
Understanding Metadata Fundamentals
Defining Metadata’s Role: Metadata, quite simply, is “data about data.” It serves as the foundational layer that describes, categorizes, and organizes all data assets within an organization. This encompasses three primary types:
- Technical Metadata: Describes the structure and characteristics of data, such as schema definitions, data types, table names, file formats, and storage locations. It’s crucial for data engineers and IT professionals.
- Business Metadata: Provides context for business users, defining data terms, glossaries, ownership, business rules, and how data relates to business processes and objectives. This helps bridge the gap between technical data and business understanding.
- Operational Metadata: Captures information about data’s journey and usage, including creation dates, modification logs, access patterns, data refresh schedules, and data quality metrics. It’s vital for monitoring and auditing.
By unifying these perspectives, metadata explains not just what data is, but also where it comes from, who owns it, how it changes over time, and how it is used across various applications and analytical models. This comprehensive understanding is paramount for leveraging data effectively and responsibly.
Advanced Components and Technologies Driving Modern Metadata Management
Modern Metadata Management Platforms leverage cutting-edge technologies to automate and enhance traditional metadata practices.
- Automated Metadata Discovery & Profiling: This core capability uses machine learning (ML) algorithms to automatically scan and ingest metadata from diverse data sources—databases, data lakes, cloud storage, applications—without manual intervention. Data profiling analyzes the content and structure of data to infer data types, patterns, quality issues, and relationships, significantly reducing the effort required for initial cataloging.
- Data Cataloging & Business Glossary: The data catalog acts as a centralized inventory of all data assets, making them easily discoverable through search and browse functionalities. It integrates technical, business, and operational metadata. A business glossary provides standardized definitions for key business terms, ensuring a common language across the enterprise and eliminating ambiguity. ML often enhances semantic search and provides intelligent recommendations for relevant datasets.
- Data Lineage & Impact Analysis: Data lineage visually maps the journey of data from its origin to its consumption point. It shows how data is transformed, moved, and used across systems. This is indispensable for root cause analysis of data errors, understanding the impact of changes, and ensuring compliance. Graph databases are often employed here to efficiently store and query complex lineage relationships.
- Data Quality Integration: Metadata management solutions often integrate with data quality tools to monitor and report on data accuracy, completeness, consistency, and timeliness. Anomalies detected by ML models can automatically trigger alerts or remediation workflows, ensuring the reliability of data used for critical business functions and AI models.
- Knowledge Graphs & Graph Databases: These technologies are at the heart of advanced metadata management. Knowledge graphs represent metadata as a network of interconnected entities and relationships, allowing for complex queries, inferencing, and semantic understanding of data. Graph databases provide the underlying storage and processing power for these graphs, enabling rapid traversal and analysis of relationships like data lineage or business hierarchies.
- Role-Based Access Control (RBAC) & Policy Enforcement: Integral to data governance, RBAC allows organizations to define granular access permissions based on user roles. Metadata platforms can enforce data access policies, ensuring that sensitive data is only visible to authorized personnel, supporting compliance with regulations like GDPR or CCPA.
The Imperative for Data Control
Beyond mere organization, Metadata Management provides the necessary controls to manage data effectively and responsibly.
- Ensuring Data Quality and Accuracy: Robust metadata management directly contributes to higher data quality. By documenting data definitions, data types, validation rules, and acceptable ranges, organizations can proactively identify and rectify inconsistencies. Metadata-driven data quality checks ensure that data entering and flowing through systems meets predefined standards, resulting in more reliable datasets for analytics and operational processes. This proactive approach prevents erroneous data from propagating, saving significant resources on data cleansing down the line.
- Compliance and Regulatory Adherence: Controlling enterprise data through comprehensive metadata is vital for meeting stringent regulatory requirements across industries (e.g., GDPR, CCPA, HIPAA, SOX, BCBS 239). Metadata provides an auditable trail of data usage, ownership, sensitivity classifications, and privacy attributes, simplifying compliance efforts. It allows organizations to quickly demonstrate where sensitive data resides, how it is processed, and who has accessed it, mitigating legal and reputational risks associated with data breaches or non-compliance. Policy enforcement mechanisms, driven by metadata, ensure that data handling practices align with legal mandates.
Challenges and Barriers to Adoption
Despite the clear benefits, implementing a comprehensive Metadata Management strategy can face significant hurdles:
- Data Silos and Integration Complexity: Enterprises often have data scattered across numerous disparate systems, legacy databases, cloud platforms, and third-party applications. Integrating metadata from these diverse sources, each with its own format and semantics, is technically challenging and time-consuming. Lack of standardized APIs or common data models can exacerbate this issue.
- Lack of Standardization and Data Governance Maturity: Many organizations lack mature data governance frameworks, leading to inconsistent data definitions, naming conventions, and quality standards. Without a clear governance structure, the metadata itself can become fragmented and unreliable, undermining the very purpose of metadata management.
- Cultural Resistance and Skill Gaps: Successful metadata management requires a shift in organizational culture, fostering a data-centric mindset where everyone understands the value of documenting and maintaining metadata. Resistance to change, lack of executive sponsorship, and insufficient training can impede adoption. Furthermore, there’s often a skill gap in areas like data architecture, data governance, and specialized metadata tool usage.
- Scalability and Performance Issues with Growing Data Volumes: As data volumes and the number of data sources proliferate, the metadata repository itself can become massive. Ensuring that the metadata platform can scale efficiently to ingest, process, and query metadata in a timely manner, without impacting performance, is a significant technical challenge, especially for real-time analytics and AI applications.
Business Value and ROI
The strategic investment in robust Metadata Management yields substantial returns across various business functions.
- Powering Advanced Analytics & AI/ML: High-quality, well-understood metadata is the backbone of advanced analytics and machine learning initiatives. It ensures that analytical models are built on reliable, consistent, and contextually rich data. Data scientists spend significantly less time on data discovery, cleaning, and preparation when comprehensive metadata is available, accelerating model development and deployment. This leads to more accurate predictions, more insightful discoveries, and ultimately, more effective AI solutions.
- Improving Business Decision-Making: By providing a clear, unified understanding of data assets and their relationships, metadata empowers business leaders to make informed decisions with confidence. It eliminates ambiguity, provides transparency into data origins and quality, and ensures that everyone is working from the same “single version of truth.” This fosters a data-driven culture, leading to better strategic planning, operational adjustments, and competitive advantage.
- Accelerating Data Discovery and Time-to-Insight: A well-organized metadata repository, acting as a central data catalog, allows analysts, data scientists, and business users to quickly discover relevant data assets. Intuitive search capabilities, business glossaries, and data lineage maps drastically reduce the time spent searching for and understanding data. This accelerates the path from raw data to actionable insights, enabling faster response to market changes and new business opportunities.
- Reducing Operational Costs and Risks: By streamlining data integration, improving data quality, and enhancing compliance, metadata management significantly reduces operational costs associated with data errors, redundant data efforts, and manual data governance processes. It also mitigates risks associated with poor data quality, regulatory non-compliance, and data breaches, protecting the organization’s reputation and financial health.
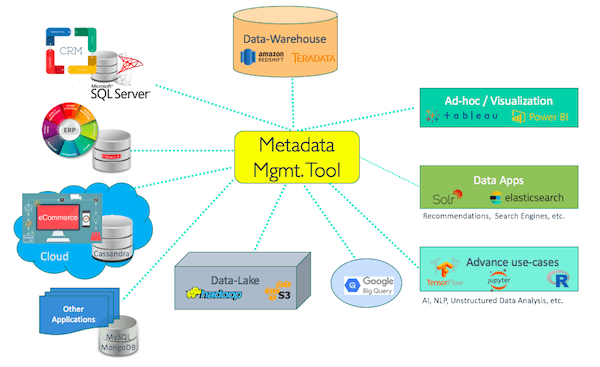
Comparative Insight: Metadata Management in the Modern Data Landscape vs. Traditional Approaches
The evolution of data management has seen significant shifts, with Metadata Management emerging as a distinct and crucial discipline that fundamentally alters how organizations interact with their data. Historically, data management revolved around traditional data lakes and data warehouses, which primarily focused on storage and structured querying, respectively.
Traditional Data Lakes/Warehouses: In a traditional setup, data lakes were excellent for storing vast amounts of raw, unstructured, or semi-structured data, while data warehouses provided structured environments for reporting and analytics. However, both often suffered from significant metadata deficiencies. Data lakes could easily devolve into “data swamps” due to a lack of descriptive metadata, making data discovery and understanding incredibly difficult. Users struggled to find relevant datasets, understand their meaning, or trust their quality. Similarly, while data warehouses imposed some schema on data, the business context, lineage beyond the immediate ETL process, and broader data relationships were often poorly documented or confined to disparate spreadsheets and tribal knowledge. Data governance was often reactive and manual, making compliance a laborious task.
The Modern Metadata Management Platform: Modern Metadata Management Platforms and data catalogs represent a paradigm shift. Instead of merely storing data, these platforms focus on understanding and governing it. They act as an intelligent layer above diverse data storage solutions, whether they be on-premise data warehouses, cloud data lakes, streaming platforms, or SaaS applications. Key differences include:
- Automated Discovery vs. Manual Efforts: Modern platforms leverage AI/ML for automated metadata harvesting and profiling, drastically reducing the manual effort required in traditional approaches.
- Unified Context vs. Fragmented Understanding: They create a holistic, interconnected view of data (often using knowledge graphs) that spans technical, business, and operational aspects, overcoming the fragmented understanding prevalent in older systems.
- Proactive Governance vs. Reactive Compliance: With features like automated data lineage, data quality monitoring, and policy enforcement, modern platforms enable proactive data governance, simplifying compliance and reducing risk.
- Enhanced Data Democratization vs. Bottlenecks: By making data easily discoverable, understandable, and trustworthy through data catalogs and semantic search, metadata management democratizes data access. This empowers a broader range of users – from business analysts to data scientists – to find and utilize data without relying on a central IT bottleneck, contrasting sharply with the often-restricted access and siloed knowledge of traditional environments.
- AI/ML Readiness: Critically, robust metadata management is foundational for AI and machine learning initiatives. It ensures that the training data for ML models is high-quality, relevant, and understood, a capability largely absent in traditional data storage solutions.
In essence, while traditional systems focused on storing and processing data, modern metadata management platforms focus on making data intelligent, governable, and accessible, unlocking its true potential for advanced analytics and strategic decision-making in the digital era.
World2Data Verdict: The Unifying Force for Data-Driven Enterprises
The future of data-driven enterprises is intrinsically linked to the maturity of their Metadata Management capabilities. World2Data’s verdict is clear: organizations must elevate metadata management from an optional technical task to a core strategic imperative. We predict an acceleration in the adoption of AI-powered metadata platforms that not only automate discovery and classification but also intelligently recommend data assets, proactively identify quality issues, and dynamically enforce governance policies. Investing in a robust, cloud-native metadata management solution, underpinned by knowledge graph technology, is no longer a luxury but a fundamental requirement for achieving true data literacy, ensuring regulatory compliance, and unlocking the full transformative power of data for advanced analytics and artificial intelligence. Companies that fail to establish a comprehensive metadata strategy risk falling behind, drowning in their own data deluge.


{kind=link}