


Microservices Architecture for Data Systems: Embracing Agility, Scalability, and Future-Proofing Data Infrastructure
1. Platform Category: Architectural Pattern
2. Core Technology/Architecture: Decoupled, independently deployable services communicating via APIs or event streams
3. Key Data Governance Feature: Federated Data Governance / Data Contracts
4. Primary AI/ML Integration: ML Model as a Service (MaaS) deployment
5. Main Competitors/Alternatives: Monolithic Architecture, Service-Oriented Architecture (SOA), Data Mesh
The landscape of enterprise data management is undergoing a significant transformation, driven by the increasing demands for real-time processing, unprecedented scalability, and rapid innovation. In this evolving environment, Microservices Architecture for Data Systems emerges as a pivotal strategy, offering a modular, agile, and resilient framework for handling complex data challenges. This deep dive explores how microservices fundamentally reshape data infrastructure, enabling organizations to move beyond the limitations of monolithic systems and embrace a future where data is a truly dynamic and accessible asset.
Introduction: The Paradigm Shift Towards Microservices Data Systems
In an era defined by data proliferation and the relentless pursuit of insights, traditional monolithic data architectures often struggle to keep pace. The rigidity, single point of failure, and slow deployment cycles inherent in these systems have become critical bottlenecks for modern enterprises. Enter Microservices Architecture for Data Systems – a disruptive yet highly effective approach that champions decentralization, independent service deployment, and clear API-driven communication. This architectural style is not merely a trend; it’s a fundamental re-imagining of how data components are built, managed, and scaled. Our objective is to unpack the core tenets of microservices within a data context, analyze its profound impact on business value, address the inevitable challenges, and provide a comparative perspective against established paradigms. Understanding this shift is crucial for any organization aiming to build a truly agile and scalable data platform.
Core Breakdown: Dissecting Microservices Architecture for Data Systems
At its heart, Microservices Architecture for Data Systems advocates for decomposing large, complex data processing applications into a collection of small, independent, and loosely coupled services. Each service is designed to perform a single business function or a small set of related functions, owning its data and communicating with others primarily through well-defined APIs or asynchronous event streams. This granular approach fosters unparalleled flexibility and resilience.
Decentralized Data Management and Service Autonomy
A cornerstone of this architecture is decentralized data management. Unlike monolithic systems where a single, often gargantuan, database serves the entire application, microservices architecture encourages each service to manage its own database. This allows teams to choose the most suitable database technology (SQL, NoSQL, graph, time-series) for a particular service’s needs, optimizing performance and scalability. This service autonomy extends beyond data stores to include independent development, testing, and deployment lifecycles. Teams can iterate on individual services without fear of destabilizing the entire data ecosystem, dramatically accelerating development and deployment cycles. This also encourages a domain-driven design approach, where data ownership and expertise are encapsulated within distinct service boundaries, leading to clearer responsibilities and higher quality data products.
API-Driven Data Access and Event Streams
Communication between these independent services is paramount. API-driven data access ensures that data consumers interact with services through explicit, versioned interfaces, promoting loose coupling and preventing direct database access. This contractual approach enhances data governance and simplifies integration, as services only expose what is necessary. For real-time data flows and asynchronous interactions, event streams (often powered by Kafka, RabbitMQ, or cloud-native messaging services) play a crucial role. Services can publish events when significant data changes occur, allowing other interested services to subscribe and react, fostering an event-driven data ecosystem that is highly responsive, scalable, and resilient to individual service failures. This pattern is particularly powerful for complex data pipelines, real-time analytics, and operational data stores.
Challenges and Barriers to Adoption in Data Microservices
Despite its compelling advantages, adopting Microservices Architecture for Data Systems is not without its complexities. One of the most significant hurdles is maintaining data consistency across services. In a distributed environment, ensuring data integrity when multiple services own different parts of a business entity requires sophisticated strategies, often involving eventual consistency models, sagas for distributed transactions, or idempotent operations. Managing these distributed transactions is inherently more complex than ACID transactions in a monolithic database, demanding careful design and robust error handling mechanisms.
Furthermore, the operational complexity can be substantial. Deploying, monitoring, logging, tracing, and debugging a system composed of dozens or even hundreds of independent services requires robust MLOps tooling, advanced observability platforms (like Prometheus, Grafana, Jaeger), and highly skilled DevOps teams. Data governance also becomes a federated concern, necessitating clear data contracts – formal agreements on data schema, quality, and semantics – and distributed metadata management across diverse service boundaries. Security also adds another layer of complexity, requiring careful consideration of authentication, authorization, and data encryption across multiple service endpoints. Overcoming these challenges demands significant investment in infrastructure, tooling, and a cultural shift towards DevOps and automation.
Business Value and ROI of Microservices Data Systems
The investment in overcoming these challenges yields substantial returns. By adopting Microservices Data Systems, organizations realize faster model deployment for AI/ML applications, as data pipelines, feature engineering services, and inference endpoints can be developed, tested, and updated independently and in parallel. The inherent fault isolation means that a failure in one data processing service won’t bring down the entire data platform, leading to significantly improved system resilience, uptime, and mean time to recovery. This modularity also grants unparalleled technology stack flexibility, allowing teams to leverage the best tools for each specific data task, from real-time stream processing with Flink to batch analytics with Spark, or specialized databases for particular data models.
Ultimately, this leads to faster feature development and quicker time-to-market for new data products, analytical capabilities, and machine learning models. Data quality for AI/ML improves as specialized services can focus on specific data transformations, validations, and enrichments with greater precision. The ability to scale individual components independently optimizes resource utilization, providing a clear path to a scalable and cost-effective data infrastructure. The ROI manifests in enhanced agility, reduced operational risk, lower total cost of ownership over the long term, and the capacity to rapidly innovate in a data-driven world, empowering data scientists and analysts with responsive and reliable data access.
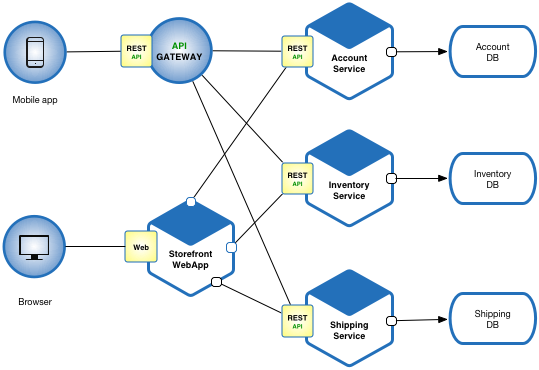
Comparative Insight: Microservices vs. Traditional Data Architectures
To fully appreciate the transformative impact of Microservices Architecture for Data Systems, it’s crucial to compare it against its predecessors and contemporaries. The most prominent comparison is with the Monolithic Architecture, where all data processing, storage, and application logic reside within a single, tightly coupled unit. While simpler to develop initially, monoliths quickly become unwieldy as data volume, user base, and functional complexity grow. Updates become risky, scaling is often all-or-nothing (scaling the entire application even if only one part is strained), and technology choices are locked in from the start. Microservices directly addresses these issues by breaking the monolith into manageable, independent services, each with its own lifecycle, technology stack, and dedicated team, leading to superior agility, resilience, and operational efficiency.
When considering data storage paradigms, the traditional Data Lake and Data Warehouse models represent centralized approaches. A Data Warehouse, optimized for structured, historical data and business intelligence, often employs a single, powerful relational database schema. Data Lakes, on the other hand, store raw, unstructured data at scale, typically in a centralized object store like HDFS or S3. While effective for their specific purposes, integrating diverse data sources and processing types in these centralized models can still lead to complex, tightly coupled ETL pipelines and a single point of failure or bottleneck in terms of data ingestion, transformation, or serving layers.
Microservices Architecture for Data Systems offers a complementary or even alternative approach to these centralized paradigms. Instead of a single, massive data lake or warehouse, microservices can manage smaller, domain-specific data stores, each feeding into a larger, federated data ecosystem. This doesn’t mean abandoning data lakes or warehouses entirely; rather, microservices can be used to build the ingestion, transformation, and consumption layers that interact with these centralized stores more flexibly and robustly. For example, a microservice could be responsible for ingesting specific IoT sensor data into a raw data lake, another for transforming a subset of that data into a curated view for a particular domain, and yet another for serving it via a dedicated API to an analytics dashboard or an ML model. This modularity enhances both the agility of data pipelines and the isolation of data domains, reducing interdependencies and accelerating data flow.
Furthermore, it’s important to distinguish Microservices Data Systems from the nascent Data Mesh concept. While both promote decentralized data ownership and domain-driven design, Data Mesh primarily focuses on organizational structure and treating data as a product, emphasizing data discoverability, quality, and governance at the domain level. Microservices, conversely, is an architectural pattern for building software systems, including data systems. A Data Mesh strategy can certainly be implemented using microservices architecture, where each “data product” is served and managed by a set of microservices. This synergy allows for the technical implementation of data products, facilitating self-service data access and federated governance. However, one could have a microservices architecture without fully adopting all principles of a Data Mesh, and vice-versa. Microservices provide the technical blueprint for the independent, autonomous data domains that a Data Mesh envisions, making them highly synergistic and often co-implemented.
The key differentiator for microservices lies in their ability to foster extreme modularity and independent evolution. This enables parallel development by multiple teams, tailored technology choices, and localized failures, significantly outperforming the architectural rigidity and development bottlenecks often associated with monolithic or purely centralized data platforms. For organizations seeking maximum agility, resilience, and the capacity for continuous innovation in their data infrastructure, microservices offer a compelling path forward, especially for complex, real-time, or rapidly evolving data requirements.
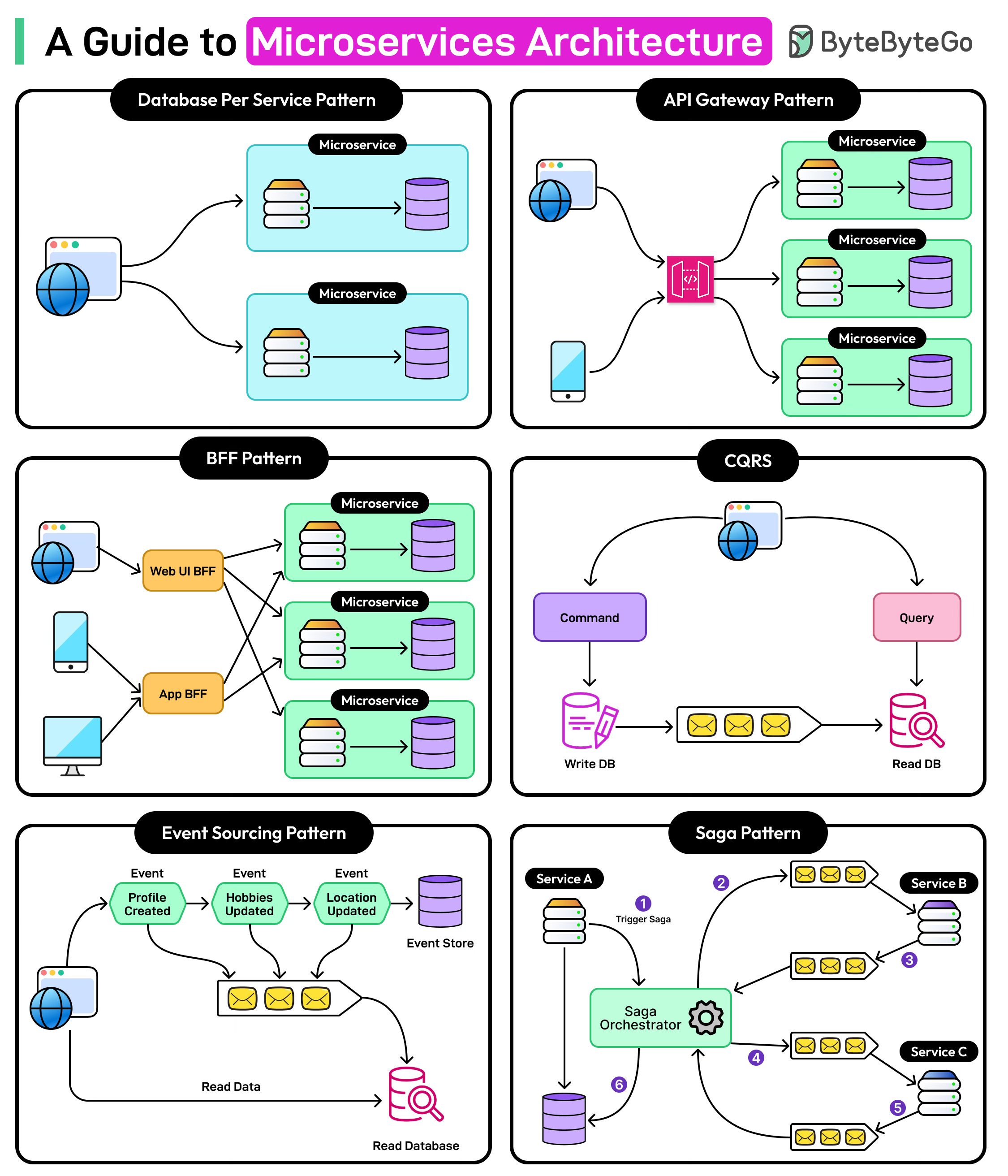
World2Data Verdict: The Imperative for Data System Modernization
The adoption of Microservices Architecture for Data Systems is no longer a luxury but an imperative for enterprises striving for true data agility and competitive advantage in a data-saturated world. World2Data.com asserts that organizations must strategically invest in migrating from monolithic data structures to a microservices paradigm, particularly for greenfield projects and critical, evolving data domains. This transition, while demanding significant investment in tooling, expertise, and cultural shifts, unlocks unparalleled scalability, resilience, and speed of innovation. We recommend focusing on a gradual, domain-by-domain migration, prioritizing robust MLOps practices, and establishing clear data contracts to effectively manage the inherent complexity. The future of data lies in federated, independently managed services that can adapt and scale on demand, empowering data-driven decisions and accelerating the deployment of AI/ML initiatives. Embracing Microservices Data Systems today ensures a future-proof foundation for tomorrow’s intelligent enterprise, capable of navigating the ever-increasing demands of data processing and analytics with agility and confidence.

{kind=link}