


Real-Time Data Pipeline: Powering Instant Decisions in the Modern Data Era
Platform Category: Data Integration and Streaming Platform
Core Technology/Architecture: Stream Processing, Event-driven architecture, Low-latency data ingestion, Change Data Capture CDC
Key Data Governance Feature: Real-time data quality monitoring, Schema registry, Role-based access control for streaming topics, Data lineage for stream processing
Primary AI/ML Integration: Real-time feature engineering for ML models, Real-time inference for fraud detection or recommendations, Integration with streaming ML frameworks
Main Competitors/Alternatives: Apache Kafka, Apache Flink, Apache Spark Streaming, Amazon Kinesis, Google Cloud Dataflow, Confluent Platform, StreamSets
In today’s dynamic business environment, the Real-Time Data Pipeline is fundamental for any organization embracing modern data strategies. These sophisticated pipelines are no longer an optional upgrade but a critical infrastructure component, enabling businesses to transform raw, streaming data into immediate, actionable insights that drive truly instant decisions and competitive advantage. The core of modern data operations relies heavily on the seamless flow provided by real-time pipelines, involving continuous data ingestion, immediate processing, and rapid dissemination. Such a proactive approach ensures that companies operate with the freshest intelligence, allowing for unprecedented responsiveness in highly volatile markets.
The Imperative of Real-Time Data Pipelines in Modern Data Strategies
The relentless pace of digital transformation and the exponential growth of data have elevated the Real-Time Data Pipeline from a niche technology to an essential pillar of any robust modern data strategy. Businesses across industries, from finance and retail to healthcare and manufacturing, are recognizing that traditional batch processing can no longer keep pace with the demands of an always-on, interconnected world. The ability to ingest, process, and analyze data as it’s generated is paramount for making informed, timely choices that directly impact customer satisfaction, operational efficiency, and market competitiveness.
A Real-Time Data Pipeline is an architectural construct designed to handle continuous streams of data, processing events with minimal latency. Its primary objective is to deliver insights that are current, relevant, and actionable the moment they are needed, facilitating truly instant decisions. This capability unlocks unprecedented business agility, allowing organizations to react to market shifts, capitalize on fleeting opportunities, and mitigate risks before they escalate. Imagine the power of immediate fraud detection, hyper-personalized customer experiences delivered without delay, and operational efficiencies optimized in milliseconds. This rapid feedback loop empowers enterprises to adapt swiftly, marking a significant evolution in how businesses operate and cementing the crucial role of real-time data in shaping the future of enterprise intelligence.
Anatomy of a Real-Time Data Pipeline: Architecture and Core Components
Building a resilient and efficient Real-Time Data Pipeline requires a well-orchestrated blend of technologies and architectural patterns. At its heart, these pipelines are designed for high throughput, low latency, and fault tolerance, enabling the continuous flow of information that underpins modern data ecosystems.
Core Technologies and Architecture
- Stream Processing: This is the engine of the real-time pipeline, responsible for processing data records or events as they arrive, rather than waiting for batches. Technologies like Apache Flink and Apache Spark Streaming provide powerful frameworks for complex event processing, aggregations, and transformations on unbounded data streams. They enable sophisticated analytics, filtering, and pattern matching on the fly.
- Event-Driven Architecture: Central to real-time systems, this paradigm revolves around the production, detection, consumption, and reaction to events. Platforms such as Apache Kafka, Amazon Kinesis, and Google Cloud Dataflow act as highly scalable, distributed streaming platforms that enable decoupling of data producers and consumers, ensuring reliable data delivery and flexible integration.
- Low-Latency Data Ingestion: The initial step of any real-time pipeline involves capturing data from diverse sources with minimal delay. This often leverages native connectors, APIs, or specialized ingestion tools that can handle high volumes of data from sources like IoT sensors, web applications, transactional databases, and social media feeds.
- Change Data Capture (CDC): For synchronizing operational databases with analytical systems in real-time, CDC is indispensable. It monitors and captures row-level changes (inserts, updates, deletes) in a database and streams them as events. This ensures that downstream systems always have the most current state of the data, critical for applications requiring immediate data freshness.
- Data Sources and Sinks: Real-time pipelines connect a myriad of data sources, from point-of-sale systems and application logs to manufacturing equipment. The processed data is then directed to various sinks, including real-time dashboards for operational monitoring, machine learning models for instantaneous inference, notification systems, and even back to operational databases for dynamic updates.
Data Governance in Real-Time Environments
While speed is crucial, it must not come at the expense of data quality or security. Robust data governance features are paramount for maintaining trust and compliance within a Real-Time Data Pipeline:
- Real-time data quality monitoring: Continuous validation and profiling of streaming data to detect anomalies, errors, or missing values as they occur. This allows for immediate corrective action, preventing the propagation of bad data.
- Schema Registry: A centralized repository for managing schemas of data flowing through the pipeline. It enforces schema evolution, ensuring compatibility between producers and consumers and preventing data corruption due to schema mismatches.
- Role-based access control for streaming topics: Implementing fine-grained permissions for who can produce or consume data from specific topics or streams, ensuring data security and compliance with regulations like GDPR or CCPA.
- Data lineage for stream processing: The ability to track the origin, transformations, and destinations of data as it moves through the pipeline. This provides transparency, aids in debugging, and supports audit requirements.
Real-Time AI/ML Integration
The synergy between Real-Time Data Pipelines and Artificial Intelligence/Machine Learning is profound, unlocking powerful applications for instant decisions:
- Real-time feature engineering for ML models: Instead of pre-calculating features in batch, real-time pipelines enable the computation of features (e.g., user’s last N interactions, average transaction value in the last 5 minutes) on the fly, feeding continuously updated features to ML models.
- Real-time inference for fraud detection or recommendations: Models can consume streaming data, make predictions instantaneously, and trigger immediate actions. This is critical for applications like detecting fraudulent transactions as they happen or delivering hyper-personalized product recommendations in milliseconds.
- Integration with streaming ML frameworks: Seamless connectivity with frameworks designed for machine learning on streams, allowing models to learn and adapt continuously as new data arrives, embodying the continuous intelligence paradigm.
Challenges and Barriers to Adoption
Despite their undeniable advantages, implementing and maintaining Real-Time Data Pipelines presents significant challenges:
- Complexity: Designing, deploying, and managing distributed streaming systems is inherently complex. It requires specialized skills in stream processing frameworks, distributed systems, and real-time data modeling.
- Data Quality and Consistency: Ensuring data accuracy and consistency across high-velocity, diverse streams is a formidable task. Issues like out-of-order events, duplicate data, and data drift can compromise insights if not rigorously managed.
- Latency Management: Achieving and consistently maintaining ultra-low latency requires careful architectural choices, optimized infrastructure, and continuous monitoring. Backpressure management and exactly-once processing semantics add layers of complexity.
- Cost: The infrastructure required for real-time processing (e.g., high-performance compute, fast storage, cloud services) can be substantial. Furthermore, the operational overhead and the need for highly skilled personnel contribute to the total cost of ownership.
- Operational Resilience: Real-time systems must be robust, fault-tolerant, and capable of recovering gracefully from failures. Ensuring high availability, scalability under fluctuating loads, and effective error handling are non-trivial.
- Security and Compliance: Protecting sensitive data flowing at high speeds, while adhering to evolving regulatory requirements, demands sophisticated real-time governance and security measures.
Business Value and ROI
Overcoming these challenges yields substantial returns, making the investment in Real-Time Data Pipelines highly justifiable:
- Instant Decisions & Agility: The most direct benefit is the ability to make decisions based on the freshest data, leading to faster reactions to market changes, customer behavior, and operational events. This enhances overall business agility.
- Enhanced Customer Experience: Real-time insights enable personalized experiences, immediate customer support, and tailored recommendations, significantly boosting customer satisfaction and loyalty.
- Operational Efficiency: Real-time monitoring of systems, supply chains, and IoT devices allows for predictive maintenance, proactive issue resolution, and optimization of resource allocation, leading to significant cost savings.
- Fraud Detection & Risk Management: Identifying anomalous patterns and potential threats (e.g., fraud, security breaches) instantaneously allows organizations to prevent financial losses and protect assets more effectively than batch processing ever could.
- New Revenue Streams: The capacity to generate real-time insights can lead to the creation of new data products and services, dynamic pricing models, and innovative business opportunities.
- Competitive Advantage: Companies that harness real-time data effectively gain a significant edge, outpacing competitors who rely on slower, retrospective analytics. This capability fosters a culture of continuous innovation.
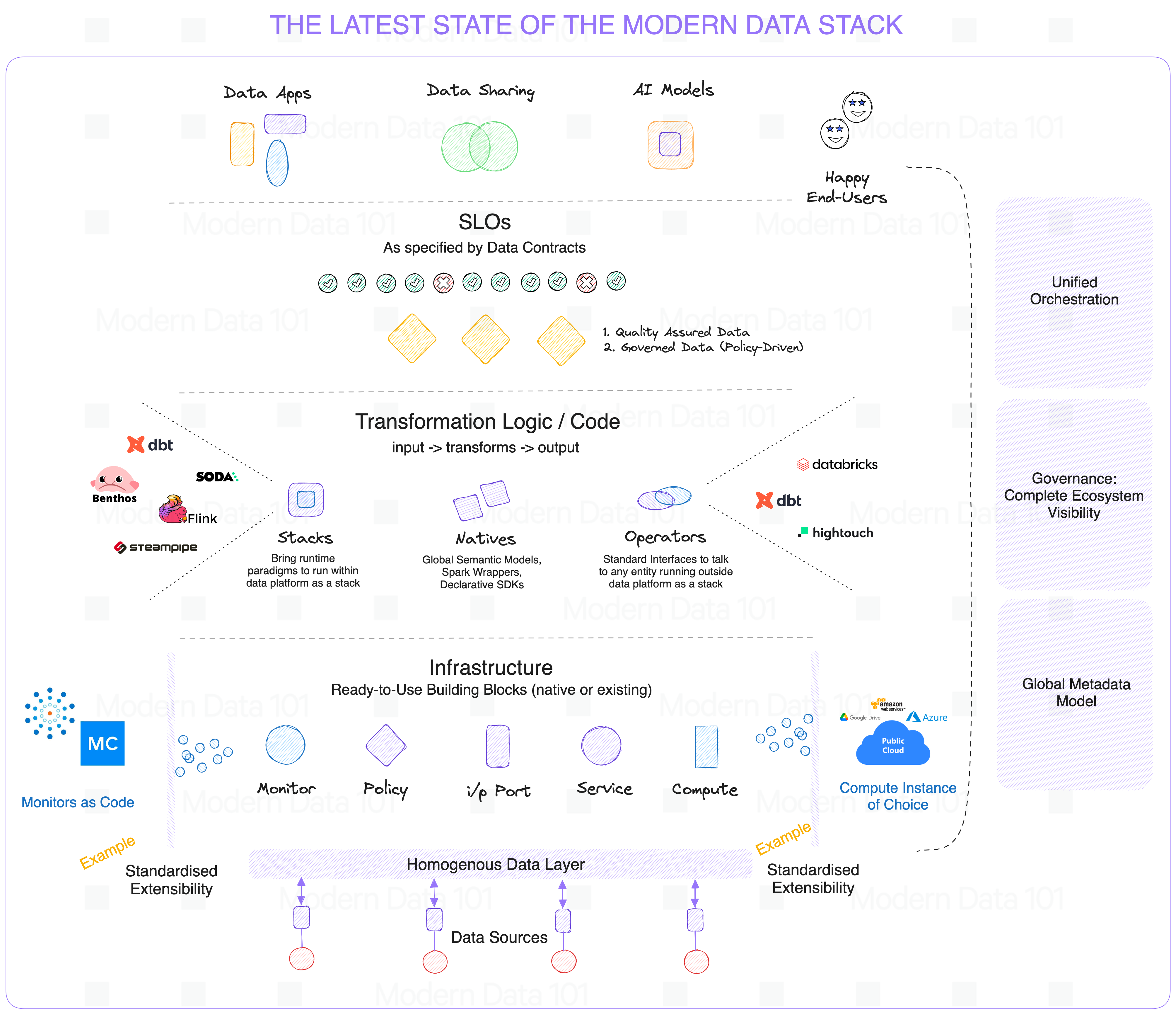
Real-Time vs. Traditional: Reshaping the Modern Data Landscape
The emergence of Real-Time Data Pipelines marks a fundamental shift from traditional data architectures such as Data Lakes and Data Warehouses. While these traditional systems have served as cornerstones for historical analysis and reporting, their inherent batch-oriented nature limits their utility for scenarios demanding immediate responsiveness. Understanding this dichotomy is key to appreciating the transformative power of a modern data approach.
Traditional Data Warehouses are optimized for structured, historical data. They excel at complex analytical queries over large datasets, providing aggregate views for business intelligence and strategic planning. Data typically undergoes significant transformation (ETL: Extract, Transform, Load) before being loaded into the warehouse, a process that can take hours or even days. This latency makes them unsuitable for operational decision-making or applications requiring immediate insights.
Data Lakes, on the other hand, store vast amounts of raw, multi-structured data, enabling schema-on-read flexibility and advanced analytics, including machine learning. While more agile than data warehouses in terms of data ingestion and variety, they often still rely on batch processing for significant analytical workloads, meaning data freshness remains a challenge for truly real-time use cases.
A Real-Time Data Pipeline fundamentally differs in its approach to latency and data freshness. Instead of storing data and then querying it, real-time pipelines process data in motion. This event-driven paradigm reduces latency to milliseconds or seconds, enabling immediate reactions. For instance, while a data warehouse might tell you what happened last quarter, a real-time pipeline tells you what’s happening right now, allowing for instant anomaly detection, personalized recommendations, or dynamic pricing adjustments.
The rise of the modern data stack often involves a hybrid approach, where these architectures complement each other. Real-time pipelines feed operational dashboards and ML models for instantaneous actions, while simultaneously populating data lakes and warehouses with enriched data for historical analysis, trend forecasting, and deeper strategic insights. This integrated approach ensures that organizations can leverage the best of both worlds: the immediate responsiveness of real-time processing and the comprehensive historical context provided by traditional systems. The evolution isn’t about replacement but about augmentation and strategic integration to serve a broader spectrum of business needs, especially those requiring instant decisions.

World2Data Verdict: The Future is Now for Real-Time Data
The journey towards a truly data-driven enterprise is intrinsically linked to the mastery of real-time data. As World2Data, we assert that the Real-Time Data Pipeline is no longer a luxury but a critical strategic imperative for any organization striving for sustained competitive advantage in the digital age. The capability to process and act on information instantaneously will differentiate market leaders, enabling a level of responsiveness and personalization previously unattainable.
For businesses embarking on or enhancing their modern data journey, our recommendation is clear: embrace real-time data with a focused, iterative approach. Identify high-impact use cases where instant decisions translate directly into measurable business value, such as fraud detection, dynamic pricing, or hyper-personalized customer engagement. Invest in robust, scalable streaming platforms like Apache Kafka or Amazon Kinesis, coupled with powerful stream processing engines such as Apache Flink or Spark Streaming. Crucially, prioritize data governance from the outset, ensuring real-time data quality, schema management, and robust access controls. The future is undeniably real-time and deeply data-driven. By strategically adopting and evolving Real-Time Data Pipelines, enterprises can cultivate an organizational culture that thrives on continuous intelligence and proactive innovation, ensuring sustained relevance and leadership in an ever-changing global landscape.

{kind=link}