


Open Data: Unlocking Innovation Through Public Data Access
Open Data genuinely represents a transformative shift in how information can drive progress. The very essence of Open Data, which advocates for making public sector datasets freely available, fosters unparalleled opportunities for innovation across industries, ensuring greater transparency and catalyzing fresh solutions for complex global challenges. This democratized access to information is not merely a policy trend but a fundamental enabler for a more informed, efficient, and innovative society.
Introduction to Open Data’s Transformative Power
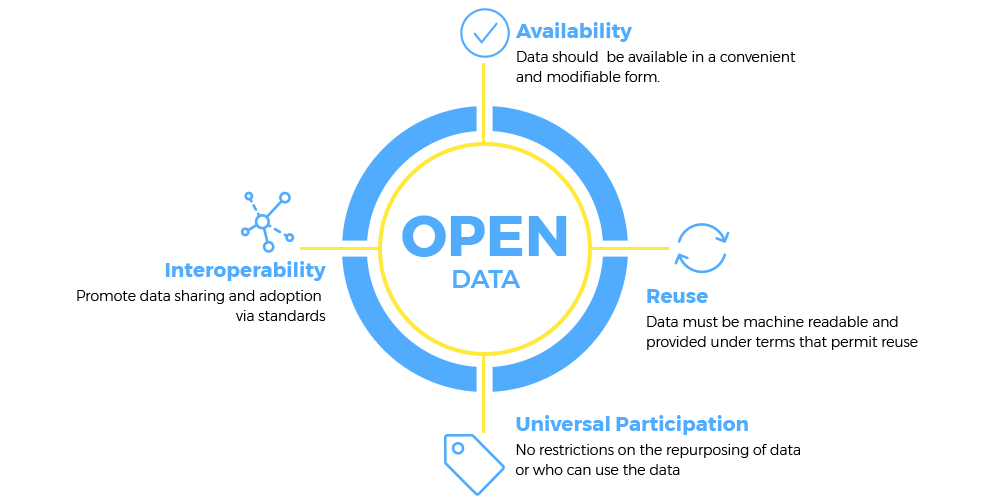
In an increasingly data-driven world, the availability and accessibility of information are paramount for progress. Open Data stands as a foundational concept, advocating for the release of public sector data in machine-readable, open formats, free of charge, and without restrictions on reuse. This initiative, often championed through dedicated Open Data Portals, Public Data Catalogs, and Data Repositories, aims to empower citizens, researchers, businesses, and governments alike. The objective of this deep dive is to explore the technical underpinnings, the immense societal and economic value, the inherent challenges, and the future trajectory of Open Data, highlighting its indispensable role in fostering innovation and transparency across the globe.
Core Breakdown: Architecture, Governance, and Value of Open Data
The operationalization of Open Data involves a sophisticated ecosystem designed to maximize accessibility, usability, and impact. Understanding its core components, governance frameworks, and integration points with advanced technologies like AI/ML is crucial.
Technical and Architectural Foundations
At its heart, the infrastructure supporting Open Data is built for discoverability and programmatic access. Key elements include:
- APIs for Programmatic Access: Data portals often expose Application Programming Interfaces (APIs), allowing developers and automated systems to directly query and retrieve datasets without manual intervention. This facilitates dynamic data integration into applications, dashboards, and research tools, driving efficiency and real-time insights.
- Standardized Data Formats: To ensure interoperability and ease of use, data is typically published in widely accepted, machine-readable formats such as CSV (Comma Separated Values), JSON (JavaScript Object Notation), and XML (Extensible Markup Language). These formats enable diverse software applications to parse and process the data effectively.
- Metadata Schemas for Discoverability: Comprehensive metadata—data about data—is vital. Standardized metadata schemas describe the content, source, quality, update frequency, and licensing terms of each dataset. This rich descriptive information helps users quickly find relevant data, understand its context, and assess its suitability for their needs.
- Cloud-Based Hosting: Many Open Data initiatives leverage cloud-based hosting solutions for scalability, reliability, and cost-effectiveness. Cloud platforms enable the storage and distribution of vast amounts of data, ensuring high availability and robust performance for users worldwide. This architecture supports the growing demand for public data access efficiently.
Key Data Governance Features for Trust and Usability
Effective governance is central to the success and sustainability of Open Data initiatives. It ensures that data is reliable, ethically managed, and legally compliant.
- Data Licensing Frameworks: Clear and permissive data licensing frameworks, such as Creative Commons (CC) licenses (e.g., CC BY, CC BY-SA) and Open Data Commons (ODC) licenses (e.g., ODC-BY, ODC-ODbL), define how data can be used, shared, and built upon. These licenses empower users while protecting the rights of data providers, fostering a vibrant ecosystem of reuse.
- Metadata Management and Standards: Beyond mere descriptions, robust metadata management systems ensure the consistency, accuracy, and completeness of metadata across all datasets. Adherence to established standards (e.g., DCAT, ISO 19115) facilitates cross-portal discoverability and aggregation.
- Data Quality Assurance: Maintaining high data quality is paramount. Governance frameworks include processes for data validation, error checking, and user feedback mechanisms to identify and rectify inaccuracies. High-quality data builds user trust and ensures the reliability of insights derived from it.
- Data De-identification and Privacy Principles: Protecting individual privacy is a critical concern, especially when dealing with public sector data. Strict data de-identification techniques (e.g., anonymization, pseudonymization, aggregation) are applied to remove personally identifiable information (PII) before publication, aligning with robust privacy principles and regulations like GDPR.
Primary AI/ML Integration: Fueling Intelligent Systems
Open Data serves as an indispensable resource for the burgeoning fields of Artificial Intelligence and Machine Learning.
- Source of Training Data for AI/ML Models: Public datasets provide a rich and diverse foundation for training AI and ML algorithms. From urban mobility patterns to environmental sensors and demographic statistics, Open Data fuels the development of more accurate and robust predictive models.
- Benchmarking of AI Algorithms: Standardized open datasets allow researchers and developers to compare the performance of different AI algorithms objectively. This transparency fosters innovation by enabling head-to-head evaluations and the identification of state-of-the-art solutions.
- Enabling Open Research and Development in AI: By providing freely accessible data, Open Data lowers the barrier to entry for AI research, fostering collaborative innovation. Academic institutions, startups, and independent developers can experiment and build new AI applications without the prohibitive cost of acquiring proprietary datasets.
- Public Datasets for Natural Language Processing and Computer Vision: Specific domains benefit immensely from open data. Large textual corpora are available for Natural Language Processing (NLP) model training, while extensive image and video datasets drive advancements in computer vision applications, from autonomous vehicles to medical imaging analysis.

Challenges and Barriers to Adoption
Despite its immense potential, the widespread adoption and effective utilization of Open Data face several significant hurdles. These challenges span technical, organizational, and cultural dimensions.
- Data Quality and Consistency: One of the most persistent issues is the variable quality of published data. Inconsistencies in formatting, incomplete records, outdated information, and erroneous entries can undermine the trustworthiness and utility of datasets, requiring significant effort from users for cleaning and validation.
- Lack of Standardization and Interoperability: While efforts are made to use standardized formats, true semantic interoperability across different data providers and domains remains a challenge. Diverse naming conventions, measurement units, and schema structures complicate the aggregation and comparison of data from multiple sources.
- Privacy and Security Concerns: Even with de-identification techniques, the risk of re-identification (linking anonymized data back to individuals) persists, especially when datasets are combined. Balancing the imperative for public access with the critical need to protect privacy is a continuous and complex governance challenge.
- Sustainability of Open Data Portals: Maintaining and updating data portals requires ongoing resources, including funding, technical expertise, and dedicated personnel. Without sustainable models, portals can become neglected, leading to outdated datasets and diminished utility.
- Lack of Data Literacy and Skill Gaps: The ability to effectively find, understand, analyze, and interpret Open Data requires specific skills. A general lack of data literacy among potential users, combined with skill gaps in data science and analytics, can limit the impact of even the highest quality open datasets.
- Organizational and Cultural Resistance: Within public sector organizations, there can be resistance to sharing data due to perceived risks, bureaucratic inertia, lack of clear incentives, or a culture of data hoarding. Overcoming these cultural barriers requires strong leadership and clear policies.
Business Value and Return on Investment (ROI)
The economic and societal benefits derived from Open Data are substantial and quantifiable, offering a compelling return on investment for governments and significant value for businesses and citizens.
- Driving Economic Growth: Open Data fuels entrepreneurs to develop novel services and products, significantly stimulating economic expansion and fostering new employment opportunities across diverse sectors. Studies consistently show that open data generates billions in economic value by enabling innovation and market efficiencies.
- New Business Models and Market Creation: The availability of free, public data acts as a raw material for innovative startups and established companies alike. It allows them to develop entirely new applications, analytics platforms, and consulting services that leverage insights from public information, leading to the creation of new market segments.
- Job Creation: As new businesses emerge and existing ones innovate with Open Data, there is a direct impact on job creation, particularly in data analysis, software development, and specialized services that interpret and apply open datasets.
- Improved Government Transparency and Accountability: These programs build citizen confidence and promote transparency in public sector operations, leading to greater accountability and informed public discourse. When citizens can scrutinize how public funds are spent or how policies are performing, it fosters a more engaged and trusting relationship between government and governed.
- Enhanced Public Services and Citizen Engagement: Open Data enables governments to deliver more efficient and responsive public services. By analyzing open datasets on traffic, health trends, or public complaints, authorities can make evidence-based decisions to optimize resource allocation and improve citizen satisfaction. It also empowers citizens to actively participate in civic life by building their own applications and analyses.
- Informed Decision-Making: Access to a wealth of public data allows organizations across all sectors to make more data-driven decisions, moving away from intuition towards evidence-based strategies, resulting in more effective policies and business outcomes.
Comparative Insight: Open Data vs. Closed Data Ecosystems
To fully appreciate the uniqueness of Open Data, it’s essential to contrast it with alternative data models, specifically proprietary data and closed data ecosystems. While traditional data lakes and data warehouses serve internal organizational needs, the more direct comparison for Open Data lies with models that restrict data access and reuse.
Proprietary data and closed data ecosystems, often managed by commercial entities or private organizations, are characterized by restricted access, stringent licensing agreements (if data is available at all), and often high costs for acquisition and usage. These models prioritize data as a competitive asset or a monetizable product, limiting its spread to protect commercial interests or maintain a competitive edge. Examples include commercial data marketplaces, private data exchanges, and proprietary datasets collected by large corporations for their internal AI/ML development.
In stark contrast, Open Data operates on principles of universal accessibility, transparency, and reusability. Its “competitors” are not direct alternatives offering the same value proposition but rather different paradigms for data management:
- Accessibility: Open Data is free and publicly available, requiring no permission to access or use. Closed ecosystems require contracts, payments, and often impose usage restrictions.
- Innovation Catalyst: Open Data acts as a general-purpose technology, fostering serendipitous innovation across diverse sectors because anyone can access and build upon it. Closed systems limit innovation to those with access or specific contractual agreements.
- Transparency and Accountability: A core benefit of Open Data from government sources is enhanced transparency and accountability, allowing public scrutiny. Proprietary data, by its nature, does not serve this function.
- Community and Collaboration: The open nature encourages communities of practice to emerge, collaborating on data analysis, visualization, and application development. Closed systems typically lack this collaborative spirit beyond specific partnerships.
- Data Governance: While Open Data has robust governance for public benefit (licensing, quality, privacy), closed systems’ governance is driven by proprietary interests, often without the same public accountability.
While commercial data marketplaces can offer highly curated and specialized datasets, their restricted nature inherently limits their potential for widespread societal impact and broad-based innovation that Open Data champions. The fundamental difference lies in the underlying philosophy: Open Data views public information as a common good, whereas proprietary models treat it as an exclusive asset.
World2Data Verdict: The Indispensable Future of Open Data
The journey of Open Data is constantly evolving, presenting new opportunities and demanding continuous adaptation. World2Data.com believes that Open Data is not merely a beneficial initiative but an indispensable pillar for the future digital economy and a vital component for ethical AI development. Its capacity to transform societies by simply making information available underscores a powerful truth: shared knowledge is the ultimate catalyst for progress in an interconnected world. To maximize this potential, governments and organizations must prioritize investment in robust data governance, advanced metadata management, and sustained support for Open Data portals. Furthermore, fostering data literacy and building vibrant communities of users around these datasets will be critical to fully unlock the innovation and societal benefits that Open Data promises. Without a doubt, the future will be shaped by how effectively we liberate and leverage public information.

{kind=link}