


Real-Time Data Feeds: Driving Hyper-Instant Decision-Making and Operational Excellence
Platform Category: Event Streaming Platform
Core Technology/Architecture: Event-driven architecture, distributed streaming, low-latency data ingestion, publish-subscribe model
Key Data Governance Feature: Schema registry, data lineage for streams, topic-based access control
Primary AI/ML Integration: Real-time feature engineering, online model inference, streaming analytics for anomaly detection
Main Competitors/Alternatives: Apache Kafka, Apache Flink, Amazon Kinesis, Google Cloud Pub/Sub, Azure Event Hubs
In today’s hyper-connected world, the ability to react instantly is not just an advantage, it’s a necessity. Real-Time Data Feeds are the engine driving this imperative, providing organizations with continuous streams of information as events unfold, allowing for immediate analysis and strategic action. This immediate access transforms raw data into actionable intelligence, enabling businesses to pivot quickly and efficiently in dynamic markets, ensuring they stay ahead of the curve.
Introduction: The Imperative of Instantaneous Information Flow
The digital age has fundamentally reshaped business expectations. From e-commerce transactions to IoT device telemetry, the volume, velocity, and variety of data generated are escalating at an unprecedented pace. Traditional batch processing, once sufficient, now struggles to keep up with the demands of modern enterprises that require instant insights to remain competitive. This is where Real-Time Data Feeds emerge as a critical enabler, transforming passive data archives into dynamic, actionable intelligence streams. This article delves into the technical underpinnings, strategic advantages, and challenges associated with implementing robust real-time data solutions, offering a deep dive into how these feeds power instantaneous decision-making across diverse industries. We will explore their architecture, key features, and compare them against traditional data management paradigms, ultimately providing a comprehensive World2Data verdict on their indispensable role in the future of data-driven organizations.
Core Breakdown: Architecture, Components, and Capabilities of Real-Time Data Feeds
At its heart, a Real-Time Data Feed system is an Event Streaming Platform built on an event-driven architecture. This paradigm focuses on the production, detection, consumption, and reaction to events, which represent significant changes in state. Unlike request-response models, event-driven systems are decoupled, scalable, and inherently asynchronous, making them ideal for handling high-velocity data streams.
Underlying Technologies and Architecture:
- Event-Driven Architecture: This foundational principle dictates that systems communicate by emitting and reacting to events. Producers publish events (e.g., a customer clicks a product, a sensor registers a temperature change) to a central event broker, and consumers subscribe to relevant event streams to process them immediately. This decoupling ensures robustness and scalability.
- Distributed Streaming Platforms: Technologies like Apache Kafka, Apache Flink, Amazon Kinesis, Google Cloud Pub/Sub, and Azure Event Hubs form the backbone. These platforms are designed to handle massive volumes of data streams, ensuring high throughput, fault tolerance, and durability. They typically employ a distributed log or queue mechanism to store events, allowing multiple consumers to process data concurrently without affecting performance, and providing message replay capabilities.
- Low-Latency Data Ingestion: Specialized connectors and APIs are used to ingest data from diverse sources (databases, IoT devices, web applications, logs) with minimal delay. Optimized protocols and efficient serialization formats (e.g., Avro, Protobuf) are crucial for reducing overhead and ensuring data fidelity as it moves through the pipeline.
- Publish-Subscribe (Pub/Sub) Model: This messaging pattern decouples senders (publishers) of messages from receivers (subscribers). Publishers categorize messages into topics without knowing which subscribers, if any, will receive them. Subscribers express interest in one or more topics and only receive messages published to those topics. This allows for flexible, scalable, and asynchronous communication, promoting loose coupling between system components.
Key Data Governance Features for Streaming Data:
Effective governance is paramount for maintaining data quality, security, and compliance in real-time environments, which are often more dynamic and less structured than traditional batch systems.
- Schema Registry: Crucial for managing the evolution of data schemas in event streams. It ensures that data producers and consumers adhere to agreed-upon data structures, preventing compatibility issues and data corruption. Tools like Confluent Schema Registry provide centralized management and versioning of schemas, allowing for backward and forward compatibility checks.
- Data Lineage for Streams: Tracking the origin, transformations, and destinations of data within real-time pipelines is complex but vital. Tools that provide visibility into the flow of data through various processing stages enable debugging, impact analysis, and compliance auditing, ensuring transparency and accountability for critical data assets.
- Topic-Based Access Control: Granular security controls are applied at the topic level, dictating which users or services can publish to or consume from specific data streams. This ensures data confidentiality and integrity, preventing unauthorized access to sensitive real-time information and supporting regulatory compliance frameworks.
Primary AI/ML Integration:
The true power of Real-Time Data Feeds is unleashed when integrated with AI and Machine Learning, enabling predictive and prescriptive capabilities that drive intelligent automation and smarter decisions.
- Real-Time Feature Engineering: Instead of computing features in batch, real-time feature engineering extracts, transforms, and aggregates features from streaming data on-the-fly. This allows models to make predictions based on the freshest possible data, drastically improving the relevance and accuracy of real-time applications.
- Online Model Inference: Machine learning models can consume real-time features and generate predictions or classifications instantaneously. This is critical for applications like fraud detection, personalized recommendations, or dynamic pricing, where decisions must be made in milliseconds to be effective.
- Streaming Analytics for Anomaly Detection: AI algorithms continuously monitor data streams for deviations from normal patterns. This enables immediate identification of fraudulent transactions, system malfunctions, security breaches, or unusual customer behavior, triggering alerts or automated responses before significant damage occurs.
Challenges and Barriers to Adoption:
While the benefits are clear, implementing and managing robust Real-Time Data Feeds comes with its own set of complexities that organizations must navigate carefully:
- Complexity of Distributed Systems: Designing, deploying, and maintaining highly available and fault-tolerant distributed streaming systems requires specialized expertise in areas like cluster management, network protocols, data partitioning, and consistency models. The operational overhead can be substantial.
- Data Consistency and Exactly-Once Processing: Ensuring data consistency in distributed systems, especially achieving “exactly-once” message delivery and processing semantics, is a significant technical challenge that requires robust transaction management, idempotent operations, and careful consideration of failure scenarios.
- Schema Evolution Management: As data requirements change, managing schema evolution without breaking existing producers or consumers in a continuous data stream is a constant battle. A robust schema registry and backward/forward compatibility strategies are essential to avoid system disruptions.
- Monitoring and Debugging: Diagnosing issues in complex, distributed real-time pipelines can be inherently difficult due to their asynchronous and decoupled nature. Effective monitoring tools, comprehensive logging strategies, and end-to-end tracing are necessary to identify bottlenecks, data loss, or processing errors quickly.
- Cost of Infrastructure: Operating high-throughput, low-latency infrastructure can be expensive, especially when considering the computational resources, persistent storage, and specialized networking required to handle vast amounts of streaming data continuously, often necessitating cloud-native solutions to manage scaling efficiently.
Business Value and ROI:
Despite the challenges, the return on investment for robust Real-Time Data Feeds is substantial, often leading to transformative improvements across the enterprise:
- Faster Model Deployment and Iteration: By providing immediate access to fresh data, real-time feeds drastically reduce the cycle time for training, deploying, and iterating on machine learning models, accelerating time-to-market for data-driven products and services.
- Enhanced Operational Efficiency: Real-time monitoring and anomaly detection minimize downtime, optimize resource utilization (e.g., smart grids, logistics), and prevent critical failures, leading to significant cost savings, improved productivity, and streamlined workflows.
- Superior Customer Experience and Personalization: Instantaneous understanding of customer behavior allows for highly personalized recommendations, targeted offers, and proactive support across all touchpoints, fostering loyalty, increasing engagement, and driving revenue growth.
- Proactive Risk Mitigation: Immediate detection of fraud, security threats, or system failures enables rapid response, significantly reducing potential financial losses, protecting sensitive data, and mitigating reputational damage and operational disruptions.
- Competitive Advantage through Agility: The ability to react instantly to market shifts, competitor actions, or emerging opportunities provides a crucial competitive edge, allowing businesses to adapt, innovate, and capitalize on fleeting moments with unparalleled speed.

Comparative Insight: Real-Time Data Feeds vs. Traditional Data Lakes/Warehouses
Understanding the distinct advantages of Real-Time Data Feeds requires a comparison with the more traditional data management paradigms: Data Lakes and Data Warehouses. While these systems remain indispensable for historical analysis and large-scale batch processing, their architectural design fundamentally differs from that of real-time streaming platforms, primarily in their approach to data ingestion, processing, and timeliness.
Traditional Data Warehouses:
- Purpose: Optimized for analytical queries on structured, historical data. They aggregate data from various sources, clean it, and load it into a predefined schema (schema-on-write), typically on a daily, weekly, or monthly batch schedule. Their strength lies in providing a consistent view of past business performance.
- Data Nature: Primarily structured and semi-structured data, highly curated and often transformed before ingestion (ETL – Extract, Transform, Load). Data quality is usually high due to rigorous cleaning processes.
- Latency: High latency, as data is processed in batches. Insights reflect past states, not the current moment, making them unsuitable for immediate operational decisions.
- Use Cases: Business intelligence reporting, executive dashboards, trend analysis, regulatory compliance reporting, and historical performance analysis.
Traditional Data Lakes:
- Purpose: Store vast amounts of raw, untransformed data (structured, semi-structured, unstructured) at scale, often for future analysis. “Schema-on-read” allows for flexibility in data interpretation and supports exploratory analytics without upfront rigid schema definitions.
- Data Nature: All data types, in their original raw format. This allows for storing data that may not have immediate use but could be valuable later, supporting various analytical needs.
- Latency: Medium to high latency. While data can be ingested more quickly than in a data warehouse, processing for insights still typically involves batch jobs or interactive queries on historical datasets, or lengthy model training cycles.
- Use Cases: Data science exploration, machine learning model training on large historical datasets, big data analytics, long-term data archival, and ad-hoc queries on raw data.
Real-Time Data Feeds (Event Streaming Platforms):
- Purpose: Designed for continuous ingestion, processing, and analysis of data as it is generated, enabling immediate reactions and decisions. The focus is on capturing and acting upon events as they happen, maintaining a constantly updated view of the operational state.
- Data Nature: Unbounded streams of events, often in semi-structured formats (JSON, Avro) with potentially evolving schemas. The emphasis is on the current state and recent events rather than comprehensive historical archives.
- Latency: Ultra-low latency, with processing occurring in milliseconds or seconds. Insights are always up-to-the-second, allowing for instantaneous operational responses and dynamic adjustments.
- Use Cases: Fraud detection, real-time personalization, IoT monitoring and control, algorithmic trading, dynamic pricing, supply chain optimization, online anomaly detection, and real-time customer engagement.
The key differentiator lies in the approach to time and state. Data Warehouses and Data Lakes primarily deal with “data at rest,” reflecting a historical snapshot or a collection of historical records. Real-Time Data Feeds, conversely, deal with “data in motion,” capturing the continuous flow of events that constitute the dynamic present. While they are distinct, they are also highly complementary. Real-time feeds can enrich data lakes with fresh, granular events or provide immediate insights that inform subsequent batch analyses in a data warehouse. Conversely, historical data from lakes and warehouses can be used to train models that are then deployed for real-time inference on streaming data. The most advanced data architectures today leverage a hybrid approach, combining the strengths of all three to achieve both comprehensive historical context and immediate operational responsiveness, creating a robust, multi-faceted data ecosystem.
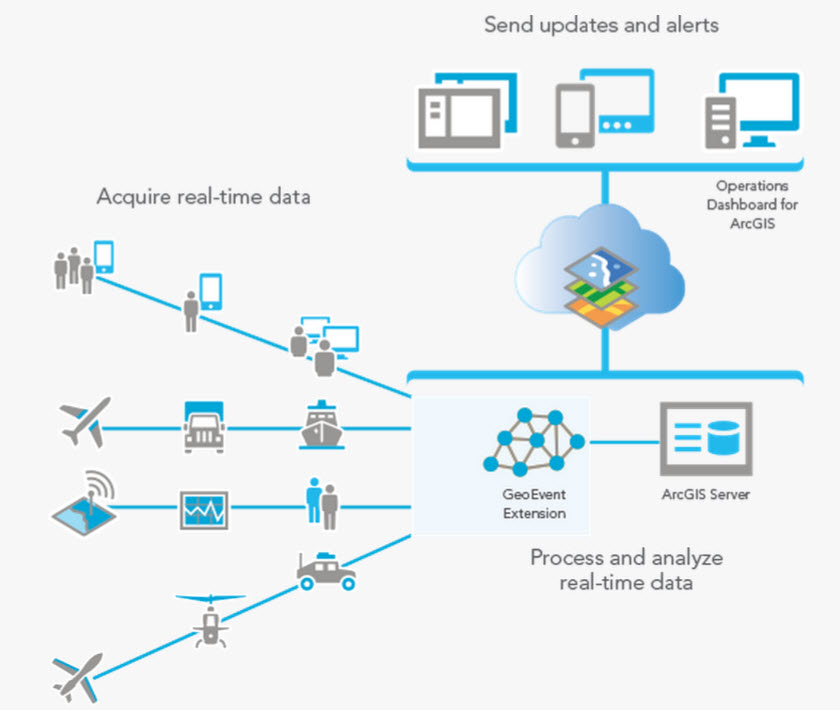
World2Data Verdict: The Indispensable Backbone of Future-Proof Enterprises
Real-Time Data Feeds are no longer a luxury but an absolute necessity for organizations striving for agility, efficiency, and competitive differentiation in the digital economy. World2Data.com views these event streaming platforms as the fundamental backbone for any future-proof enterprise data strategy. The ability to transform raw events into actionable insights in milliseconds empowers businesses to not only react instantly but also to proactively shape their environments, personalize customer experiences at scale, and mitigate risks before they escalate. Organizations that fail to invest in robust real-time capabilities risk being outmaneuvered by competitors who leverage immediate intelligence for strategic advantage. Our recommendation is clear: prioritize the development and adoption of a comprehensive event-driven architecture, focusing on scalable streaming platforms, robust data governance for streams, and seamless integration with AI/ML pipelines. This strategic investment in Real-Time Data Feeds will unlock unparalleled operational efficiency, drive innovative customer engagement, and cultivate a truly data-powered culture ready for the demands of tomorrow.

{kind=link}