


Storage Engine: How Databases Manage and Retrieve Data
Every time you save information, retrieve a record, or update a database entry, a Storage Engine is working behind the scenes. This crucial component dictates how your data is actually stored on disk, how it’s accessed, and how efficiently these operations are performed. Understanding the Storage Engine is key to appreciating the invisible architecture supporting our data-driven world, defining a fundamental concept for anyone interacting with data. It ensures data integrity, optimizes retrieval, and underpins the reliability of virtually all data systems, including those powering modern AI/ML applications.
Introduction: The Unseen Powerhouse of Databases
In the vast landscape of data management, the Storage Engine stands as a foundational yet often overlooked component. It serves as the critical interface between the high-level database system (responsible for parsing queries and managing schemas) and the underlying physical storage hardware. Its primary objective is to manage the intricate details of how data is physically laid out on disk, how it is indexed for rapid access, and how efficiently read and write operations are executed. Without a robust and well-optimized Storage Engine, databases would be slow, unreliable, and highly prone to data corruption, rendering modern applications and analytical systems virtually unusable. This deep dive will unravel the complexities of different Storage Engine architectures, exploring their core functions, the challenges associated with their implementation, and the immense business value they deliver, particularly in an era driven by AI and machine learning.
Core Breakdown: Dissecting the Heart of Data Persistence
The essence of any database’s performance, reliability, and scalability lies within its Storage Engine. It’s not just about putting data onto a disk; it’s about doing so intelligently, ensuring durability, managing concurrent access, and optimizing for diverse workloads. From the transactional integrity required by online banking to the high-throughput reads demanded by real-time analytics, the choice and design of a Storage Engine are paramount.
Key Architectures and Mechanisms
- B-tree Indexing: The Backbone of Fast Lookups
Many relational Storage Engines rely heavily on B-tree indexes for efficient data retrieval. A B-tree is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. This structure is particularly effective for disk-based systems because it minimizes the number of disk I/O operations required to find a record, making it ideal for transactional workloads where precise record access is frequent. The key characteristic of a B-tree is that its nodes can have a variable number of children within a predefined range, which ensures optimal use of disk blocks. - LSM-tree Architecture: Optimized for Writes
Log-Structured Merge-tree (LSM-tree) architectures, exemplified by Storage Engines like RocksDB and Apache Cassandra, take a fundamentally different approach. They are optimized for write-heavy workloads, minimizing random disk writes by buffering writes in memory and then sequentially writing them to disk in immutable segments. Reads, however, can be more complex as they might need to consult multiple sorted structures (memory and disk files) to find the latest version of a record. Periodic merge operations consolidate these segments, improving read performance over time and reclaiming space. This design is crucial for NoSQL databases that handle massive ingest rates. - Row-Oriented vs. Column-Oriented Storage: Workload Specialization
The physical layout of data significantly impacts performance.- Row-Oriented Storage (e.g., InnoDB, MyISAM): In this model, all data for a single row is stored contiguously. This is highly efficient for transactional processing (OLTP) where applications typically need to retrieve or update entire records. For example, fetching a customer’s entire profile (name, address, order history) from a relational database is fast because all related data is physically close on disk.
- Column-Oriented Storage (e.g., Apache Kudu, Parquet): Here, data for each column is stored contiguously. This approach excels in analytical workloads (OLAP) where queries often involve aggregating data across a few columns for many rows. For instance, calculating the average sales for a particular product across millions of transactions is much faster in a column-oriented store because only the ‘sales_amount’ column needs to be read, ignoring other irrelevant columns like ‘customer_name’ or ‘address’. This significantly reduces I/O and improves compression ratios.
- Multi-Version Concurrency Control (MVCC): The Art of Isolation
To allow multiple transactions to read and write data concurrently without blocking each other or seeing inconsistent states, many advanced Storage Engines employ Multi-Version Concurrency Control (MVCC). Instead of using explicit locks that can lead to contention, MVCC maintains multiple versions of a row. When a transaction modifies a row, a new version is created. Readers see the version of the data that was committed before their transaction started, providing snapshot isolation and greatly enhancing concurrency. InnoDB and PostgreSQL are prime examples of databases leveraging MVCC.
Essential Functions Beyond Simple Storage
Beyond the fundamental act of storing data, a Storage Engine is responsible for a suite of critical functions:
- Data Persistence & Durability: Ensuring that once data is written, it survives system crashes, power outages, and other failures. This often involves write-ahead logging (WAL) and robust recovery mechanisms.
- Transaction Management & ACID Properties: Guaranteeing Atomicity, Consistency, Isolation, and Durability (ACID) for transactions. This is foundational for maintaining data integrity and reliability, especially in transactional systems.
- Concurrency Control: Managing simultaneous access to data by multiple users or applications, preventing conflicts and maintaining data consistency through mechanisms like locking (row-level, page-level) or MVCC.
- Indexing & Query Optimization: Creating and maintaining indexes to speed up data retrieval and helping the database query optimizer choose the most efficient execution plan.
- Crash Recovery: Providing mechanisms to restore the database to a consistent state after an unexpected shutdown, often using logs and checkpoints.
Challenges and Barriers to Adoption
While integral, Storage Engines come with their own set of complexities and challenges:
- Complexity of Choice: With a myriad of engines (e.g., InnoDB, MyISAM, RocksDB, WiredTiger, Apache Kudu), selecting the optimal one for a specific application workload can be daunting. A wrong choice can lead to significant performance bottlenecks or data integrity issues down the line.
- Performance Tuning: Each Storage Engine has numerous configuration parameters that need careful tuning to match the underlying hardware and workload characteristics. Misconfiguration can severely degrade performance or even lead to system instability.
- Data Migration: Switching between different Storage Engines, even within the same database system (like MySQL’s InnoDB to MyISAM), can be complex, often requiring data dumps, reloads, and downtime, especially for large datasets.
- Resource Management: Storage Engines are heavy users of system resources (I/O, CPU, memory). Inefficient use can starve other applications or lead to overall system slowdowns. Managing caches, buffer pools, and write buffers effectively is crucial.
- Learning Curve: Understanding the internal workings of a specific Storage Engine to effectively troubleshoot, optimize, and maintain it requires specialized knowledge and experience.
- Evolution and Maintenance: Keeping up with new versions, patches, and features of Storage Engines, especially in rapidly evolving open-source ecosystems, adds to operational overhead.
Business Value and ROI
Despite the challenges, the right Storage Engine delivers substantial business value and return on investment:
- Enhanced Performance: Faster data retrieval and processing directly translate to more responsive applications, quicker analytics, and reduced latency for critical business operations. This directly impacts user experience and operational efficiency.
- Data Integrity & Reliability: By ensuring ACID compliance and robust recovery, Storage Engines provide a trustworthy foundation for all business data. This minimizes the risk of costly errors, compliance issues, and enables confident decision-making based on accurate information.
- Reduced Operational Costs: Efficient storage and indexing minimize the need for expensive hardware upgrades. Automated concurrency control and recovery features reduce manual intervention, lowering administrative overhead.
- Scalability: Engines designed for high concurrency and large data volumes allow applications to grow without requiring complete architectural overhauls, supporting business expansion and increasing user bases.
- Foundation for AI/ML: For AI and machine learning initiatives, the Storage Engine is critical. It enables efficient data retrieval for model training, supports optimized indexing for vector databases (essential for similarity search in AI applications), and ensures the high data quality necessary for effective model performance.
- Improved User Experience: A fast, reliable database powered by an optimized Storage Engine contributes directly to a seamless and satisfying user experience, which is crucial for customer retention and engagement in today’s digital landscape.
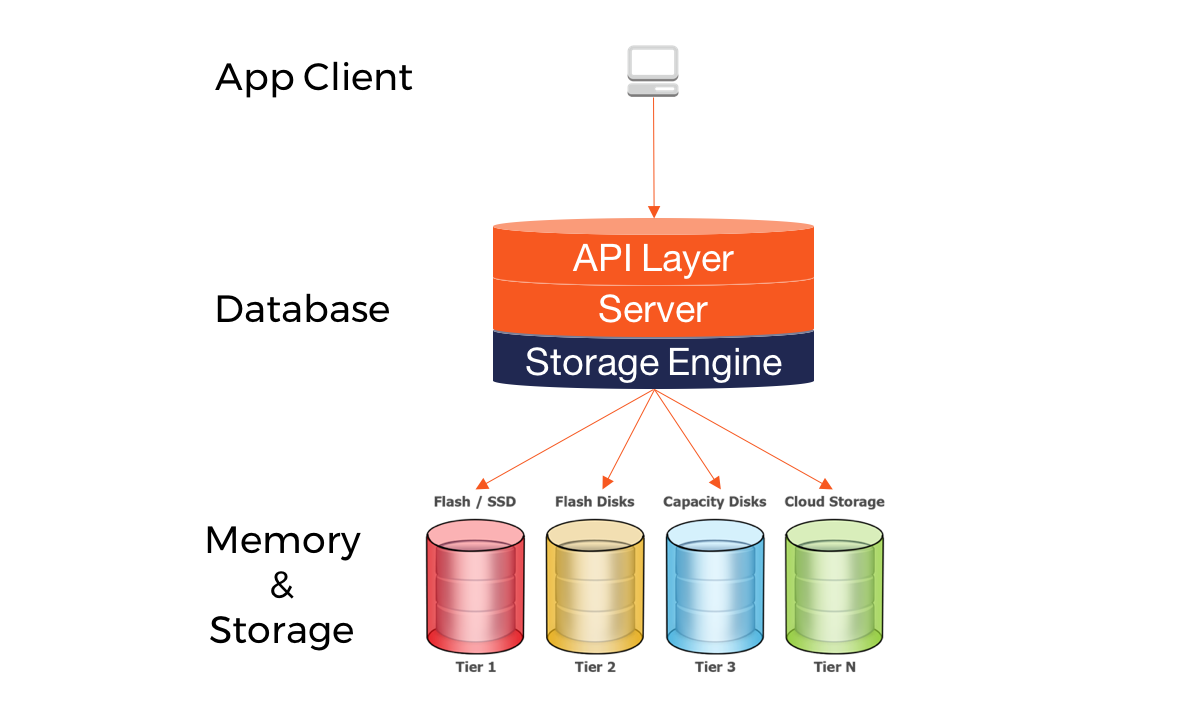
Comparative Insight: Storage Engines in the Broader Data Landscape
The role of the Storage Engine is not isolated; it operates within larger data architectures, influencing and being influenced by database types, analytics platforms, and emerging technologies like AI/ML. Understanding how different Storage Engines fit into and compare within this broader context is vital for strategic data planning.
Traditional RDBMS Engines vs. Modern NoSQL Architectures
- ACID-Compliant Powerhouses (e.g., InnoDB, WiredTiger): Traditional relational database management systems (RDBMS) heavily rely on Storage Engines like InnoDB (for MySQL) and WiredTiger (for MongoDB, also used in other contexts). These engines are engineered to strictly adhere to ACID properties, making them ideal for mission-critical transactional applications where data consistency and integrity are paramount. They often employ B-trees for indexing and MVCC for concurrency, providing strong guarantees but sometimes at the cost of horizontal scalability for extreme write volumes.
- Scalability and Flexibility (e.g., RocksDB, Apache Kudu): In the NoSQL world, Storage Engines often prioritize horizontal scalability, high write throughput, and flexible data models over strict ACID compliance. RocksDB, an embeddable key-value store, utilizes an LSM-tree architecture, making it highly efficient for write-heavy workloads and suitable for applications requiring immense scale and low latency writes. Apache Kudu, designed for fast analytics on fast data, uniquely combines the best aspects of row-oriented and column-oriented storage, providing transactional updates and efficient analytical queries over large datasets, bridging the gap between OLTP and OLAP in the Hadoop ecosystem. These engines often embrace BASE (Basically Available, Soft state, Eventually consistent) principles, offering different trade-offs in distributed environments.
How Storage Engines Enable Data Lakes and Data Warehouses
It’s important to clarify that Storage Engines are not alternatives to data lakes or data warehouses, but rather fundamental components that power them, influencing their capabilities and performance. The choice of underlying storage mechanism, often an aspect managed by the Storage Engine, directly impacts how these larger systems function:
- For Data Warehouses: Traditional data warehouses, optimized for analytical queries, often leverage database systems whose Storage Engines are either column-oriented (like those found in dedicated analytical databases or extensions like Apache Kudu) or highly optimized row-oriented engines with advanced indexing and query optimization capabilities. The ability of the Storage Engine to efficiently process large scans and aggregations is paramount here, enabling complex business intelligence reports and dashboards.
- For Data Lakes: Data lakes typically store vast amounts of raw, unstructured, and semi-structured data. While the “lake” itself might be composed of files in formats like Parquet or ORC on HDFS or object storage, specific processing frameworks (e.g., Spark, Hive) interacting with this data often employ their own internal “engines” or leverage external Storage Engines for certain operations. For instance, a data lake might feed into a system using RocksDB for real-time lookups or Apache Kudu for hybrid transactional/analytical processing on subsets of the lake’s data, allowing for more structured and performant access to specific datasets.
- Emerging AI/ML Integration and Vector Databases: The rise of AI and machine learning has introduced new demands on Storage Engines. Vector databases, crucial for AI applications like similarity search and recommendation systems, rely on highly specialized Storage Engines capable of efficiently storing and indexing high-dimensional vectors. These engines often incorporate novel indexing techniques (e’g., approximate nearest neighbor algorithms) and optimized data structures that go beyond traditional B-trees or LSM-trees, demonstrating the continuous evolution of Storage Engine technology to meet cutting-edge application needs.
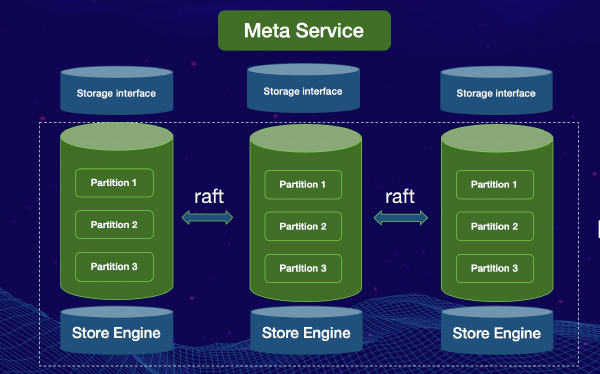
World2Data Verdict: The Unsung Hero’s Future
The Storage Engine, though often hidden beneath layers of application logic and database interfaces, is the unequivocal unsung hero of data management. Its architectural decisions – from the choice between B-trees and LSM-trees to row-oriented versus column-oriented designs – fundamentally determine the performance, reliability, and scalability of any data-driven system. As data volumes explode and AI/ML demands ever more sophisticated data handling, the evolution of Storage Engine technology will only accelerate. We foresee a future marked by increasing specialization, with engines becoming even more tailored for specific workloads (e.g., real-time analytics, graph processing, vector embeddings) and tighter integration with hardware innovations like NVMe and persistent memory. For businesses aiming to build truly performant, resilient, and future-proof data infrastructures, World2Data.com emphasizes that overlooking the foundational role of the Storage Engine is a critical misstep. Its careful selection, informed configuration, and continuous optimization are paramount, acting as the bedrock upon which modern, intelligent applications thrive. Understanding and mastering the capabilities of your chosen Storage Engine is not just good practice; it’s a strategic imperative for competitive advantage in the data-centric economy.

{kind=link}