


The Indispensable Application of Vector Database in AI Data: Revolutionizing Intelligent Systems
1. Platform Category: Vector Database
2. Core Technology/Architecture: Vector Embeddings, Approximate Nearest Neighbor (ANN) Search
3. Key Data Governance Feature: Role-Based Access Control, Metadata Management
4. Primary AI/ML Integration: Native storage for ML-generated vector embeddings, Retrieval-Augmented Generation (RAG)
5. Main Competitors/Alternatives: Pinecone, Milvus, Chroma, PostgreSQL with pgvector
The Application of Vector Database in AI Data marks a significant evolution in how intelligent systems process and understand information. The growing complexity and sheer volume of unstructured data necessitate a sophisticated approach, and the Vector Database in AI offers precisely that, transforming raw data into meaningful numerical representations. By enabling swift and semantically aware retrieval of information, these databases are becoming a cornerstone for advanced AI applications, from powering natural language understanding to enhancing the accuracy of generative models, fundamentally reshaping the landscape of AI data management.
Introduction: Unlocking New Dimensions in AI Data Management
In the rapidly evolving world of artificial intelligence, data is not merely information; it is the lifeblood that fuels innovation. However, traditional data storage and retrieval systems often fall short when dealing with the vast, complex, and often unstructured nature of AI-generated and AI-consumed data. This is where the Vector Database in AI emerges as a transformative technology, providing a specialized solution for managing and querying data based on its semantic meaning rather than mere keywords or structured attributes.
The objective of this deep dive is to explore the critical role of vector databases in modern AI data pipelines, dissecting their core architecture, diverse applications, and profound impact on various AI disciplines. We will analyze how these innovative systems enable AI models to process and understand information more intuitively, empowering capabilities that were previously challenging to achieve. From enhancing the precision of semantic search to bolstering the factual accuracy of Large Language Models (LLMs) through Retrieval-Augmented Generation (RAG), vector databases are redefining the possibilities of intelligent systems and robust AI data platforms.
Core Breakdown: The Architecture and Power of Vector Databases in AI
Revolutionizing AI Data Management with Vector Databases. Traditional databases often struggle with the unstructured nature of AI data like images, audio, and complex text. Vector databases in AI excel here, converting diverse data types into high-dimensional vectors, enabling efficient storage and retrieval based on semantic similarity. This fundamental shift allows AI models to access and process information far more intuitively.
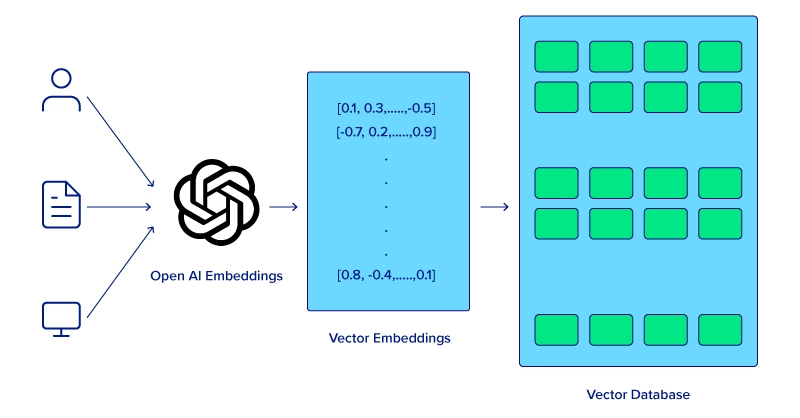
Understanding Vector Embeddings and Approximate Nearest Neighbor (ANN) Search
At the heart of any vector database lies the concept of vector embeddings. These are numerical representations of data, where items with similar meanings or characteristics are mapped to vectors that are close to each other in a multi-dimensional space. This transformation is typically performed by machine learning models (e.g., neural networks) that learn to capture the semantic essence of text, images, audio, or other complex data types. The quality of these embeddings directly impacts the effectiveness of the vector database.
Once data is vectorized, the challenge becomes efficient retrieval. Unlike traditional databases that rely on exact matches or range queries, vector databases need to find “similar” vectors. This is achieved through Approximate Nearest Neighbor (ANN) search algorithms. Exact nearest neighbor search in high-dimensional spaces is computationally prohibitive. ANN algorithms, such as HNSW (Hierarchical Navigable Small Worlds), FAISS (Facebook AI Similarity Search), and ScaNN (Scalable Nearest Neighbors), are designed to quickly find vectors that are “close enough” to a query vector, sacrificing a tiny bit of accuracy for massive gains in speed and scalability. This core capability underpins all the powerful applications of a vector database in AI.
Integration with AI Data Pipelines: Feature Stores and Data Labeling
Vector databases are not standalone components but integral parts of broader AI data platforms and MLOps workflows. They serve as a specialized kind of “feature store” for vector embeddings, storing pre-computed, high-dimensional features that AI models can readily access during inference or training. This streamlines model deployment and ensures consistency of features across different applications. For instance, customer embeddings or product embeddings can be stored and reused by recommendation engines, search systems, and personalization models.
Furthermore, the creation of quality vector embeddings often starts with well-prepared and labeled data. Data labeling, while not directly performed by the vector database itself, is a crucial prerequisite. Labeled datasets are used to train the embedding models that generate the vectors. Ensuring high-quality data labeling directly translates to more accurate and semantically rich embeddings, thereby enhancing the performance of the vector database and the downstream AI applications that rely on it.
Advanced Applications of Vector Databases in AI
- Enhancing Semantic Search and Retrieval: Moving beyond simple keyword matching, vector databases in AI power truly semantic search experiences. Users can query with natural language, and the system understands underlying meaning, returning highly relevant results even if exact word matches are absent. This dramatically improves the accuracy and utility of information retrieval across various AI applications, from enterprise search to customer support chatbots.
- Powering Advanced Recommendation Systems: Personalization is at the heart of modern AI, and vector databases are instrumental in building highly effective recommendation engines. By representing user preferences, item characteristics, and historical interactions as vectors, these systems quickly identify similar items or predict user interests with remarkable precision. This leads to more engaging user experiences and better business outcomes, fostering loyalty and increasing conversions.
- Facilitating Efficient Generative AI Workflows (RAG): Large Language Models (LLMs) and other generative AI systems thrive on rich, relevant context. Vector databases provide this by storing external knowledge bases, documents, or proprietary data as embeddings. During a query, the LLM can retrieve pertinent information from the vector database (via RAG – Retrieval-Augmented Generation) before generating a response. This process significantly reduces “hallucinations” and enhances the factual accuracy, relevance, and currency of AI-generated content, making LLMs far more reliable for mission-critical applications.
Challenges and Barriers to Adoption
Despite their immense potential, the adoption of vector databases in AI is not without its hurdles:
- Data Drift in Embeddings: Just as traditional data can drift, the underlying concepts and relationships represented by vector embeddings can also change over time. As user behavior, language usage, or real-world entities evolve, the embedding models may need retraining, and the vector data itself may require re-embedding to maintain relevance and accuracy. Managing this “embedding drift” is a complex MLOps challenge.
- MLOps Complexity for Vector Data: Integrating vector databases into existing MLOps pipelines requires specialized tools and expertise. This includes managing embedding model versions, handling vector data updates, ensuring data freshness, and monitoring the performance of vector similarity search, all of which add layers of operational complexity.
- Computational Costs and Scalability: Generating and storing high-dimensional vectors, especially for massive datasets, can be computationally intensive and require significant storage. While ANN algorithms optimize search, the indexing process itself can be resource-heavy, and scaling these systems efficiently demands careful architecture and infrastructure planning.
- Choosing the Right Vectorization Model: The performance of a vector database heavily depends on the quality of the embeddings. Selecting, training, and fine-tuning the appropriate embedding model for specific data types and use cases is a crucial and often challenging task that requires deep domain knowledge and machine learning expertise.
Business Value and ROI
The strategic application of a vector database in AI yields significant business value and a compelling return on investment:
- Accelerated AI Development and Deployment: By providing a unified, efficient store for vector features, these databases significantly reduce the time and effort required to develop, test, and deploy AI models that rely on semantic understanding. This accelerates innovation and time-to-market for AI-powered products and services.
- Enhanced Data Quality and Relevance: Vector databases elevate data quality by enabling AI systems to access information based on true semantic relevance, moving beyond superficial keyword matches. This ensures that models are trained on and retrieve the most pertinent information, leading to more accurate and reliable AI outputs.
- Improved User Experiences and Personalization: The ability to power highly accurate recommendation engines and semantic search translates directly into superior user experiences. Personalized content, relevant search results, and context-aware interactions drive higher engagement, customer satisfaction, and loyalty.
- Reduced Hallucinations in LLMs: For generative AI, particularly LLMs, vector databases are instrumental in grounding models with factual, external knowledge. By reducing “hallucinations” and ensuring responses are based on verifiable data, they make LLMs more trustworthy and suitable for critical enterprise applications, mitigating risks associated with inaccurate AI outputs.
.jpg?format=webp)
Comparative Insight: Vector Databases vs. Traditional Data Stores
To fully appreciate the impact of a vector database in AI, it’s crucial to understand its distinction from traditional data storage paradigms like data lakes and data warehouses. While these established systems are highly effective for structured data processing, analytical reporting, and even storing large volumes of raw, unstructured data, they are inherently limited in their ability to understand and query data based on semantic similarity.
Traditional Data Warehouses are optimized for structured, tabular data, enabling complex analytical queries and reporting. They excel at aggregating numerical data, joining tables, and performing OLAP operations. However, asking a data warehouse to find “documents similar in meaning to this paragraph” or “images that convey a feeling of joy” is beyond its native capabilities. They lack the high-dimensional indexing and ANN search algorithms necessary for such tasks.
Data Lakes, on the other hand, are excellent for storing vast quantities of raw, unprocessed data—structured, semi-structured, and unstructured—often in its native format. They offer flexibility for various processing frameworks and are foundational for big data analytics and machine learning. However, a data lake primarily provides storage; the intelligence to find semantically similar items still needs to be built on top, often by creating vector embeddings and then using specialized indexing, which is precisely what a vector database is designed to do efficiently.
In essence, vector databases are not replacements for data lakes or data warehouses but rather specialized, complementary components within a comprehensive AI data platform. They pick up where traditional systems leave off, providing the critical infrastructure for similarity search and contextual retrieval of unstructured data after it has been transformed into embeddings. They enable AI applications to tap into the semantic richness of data that would otherwise remain dormant or cumbersome to access, acting as an intelligent layer on top of, or alongside, existing data infrastructure. This synergy allows organizations to leverage their existing data investments while unlocking new AI capabilities through the power of vector embeddings.
World2Data Verdict: Pioneering the Next Frontier of AI Data
The future of AI data infrastructure will be profoundly shaped by the pervasive integration of vector databases in AI. They are not merely a specialized tool but a foundational component for building the next generation of intelligent applications that demand a deep understanding of content and context. World2Data.com asserts that organizations aiming for competitive advantage in the AI era must prioritize the adoption and strategic deployment of vector databases.
Our recommendation is clear: enterprises should proactively invest in understanding and implementing vector database technologies, especially in areas leveraging Generative AI, personalized customer experiences, and advanced knowledge retrieval. Focus not just on the database itself, but on the entire lifecycle of vector embeddings, from quality data labeling and robust embedding model management (MLOps for vectors) to continuous monitoring for embedding drift. By embracing this innovative technology, businesses can unlock unparalleled capabilities, democratize access to advanced AI, and foster a new era of AI-driven innovation and insight, ensuring their AI data platform is truly future-proof and intelligently empowered.

{kind=link}