


Ingestion Layer: The Crucial Gateway to Your Data Pipeline’s Success
The Ingestion Layer is the foundational first step in any robust Data Pipeline, dictating how raw information initially enters your platform. It acts as the primary access point, orchestrating the collection and entry of diverse datasets from countless sources into your system. This critical component ensures that your analytical and AI initiatives are built upon a bedrock of timely, reliable, and comprehensive data, making it paramount for effective data utilization and the overall health of your data ecosystem.
Introduction: Unpacking the Ingestion Layer’s Vital Role
In the expansive landscape of modern data architecture, the Ingestion Layer stands as the undisputed gateway, serving as a critical Data Integration Component. Its purpose extends far beyond mere data transfer; it is the strategic point where raw data, irrespective of its origin or format, begins its journey towards transformation, analysis, and actionable insight within a sophisticated Data Pipeline. Without a meticulously designed and efficiently managed ingestion layer, even the most advanced analytics engines or machine learning models would be starved of the high-quality input they require. This article will deep dive into the technical intricacies, architectural considerations, and profound business value of the Ingestion Layer, underscoring its indispensable role in empowering data-driven enterprises.
Core Breakdown: Architecture and Technicalities of Data Ingestion
The Ingestion Layer is a complex interplay of technologies and processes designed to collect, validate, and prepare data for subsequent stages of a Data Pipeline. Its effectiveness hinges on its ability to handle the sheer volume, rapid velocity, and vast variety of data encountered in today’s digital world.
Initial Collection and Entry Points: The Gateway to Your Data Platform
This layer acts as the primary access point, pulling data from countless sources into your system. Whether it’s transactional records from an OLTP database, sensor readings from IoT devices, clickstream data from web applications, or user interactions from mobile apps, the ingestion process is responsible for capturing this diverse information. A well-designed ingestion layer ensures that no valuable data is missed, establishing the very beginning of its lifecycle within your infrastructure. It needs to be versatile enough to connect to a myriad of external systems, from legacy databases to modern APIs and streaming platforms.
Core Technology & Architecture: Powering Diverse Data Flows
Modern ingestion layers leverage a mix of techniques to accommodate different data requirements:
- Batch Processing: For large volumes of data that can be collected and processed periodically, batch ingestion is ideal. This includes bulk loading from data warehouses, nightly ETL jobs from operational databases, or processing large CSV/Parquet files. Technologies like Apache Spark, Hadoop MapReduce, or traditional ETL tools fall into this category.
- Stream Processing: For real-time data flows where immediate action or analysis is required, stream processing is critical. This enables the continuous ingestion of data from sources like IoT devices, application logs, or financial transactions. Platforms such as Apache Kafka, AWS Kinesis, Google Cloud Pub/Sub, and Apache Flink are key players here, offering low-latency data capture and processing.
- API Integration: Many SaaS applications and third-party services expose data via APIs. The ingestion layer uses dedicated connectors or custom-built integrations to fetch data programmatically from these endpoints, often involving authentication, rate limiting, and robust error handling.
- Change Data Capture (CDC): CDC mechanisms are crucial for capturing changes made to source databases in near real-time. Instead of full data dumps, CDC tracks inserts, updates, and deletes, providing a lightweight and efficient way to synchronize data without impacting source system performance. Tools like Debezium or proprietary CDC features offered by database vendors are instrumental here.
Key Data Governance Features: Ensuring Trustworthy Data
The Ingestion Layer is where essential data governance practices begin, ensuring that data quality and lineage are maintained from the very first step:
- Data Quality Validation: As data enters the system, it undergoes initial checks for format, completeness, consistency, and validity. This can include schema validation, type checking, range validation, and detecting missing values. Early validation prevents propagation of erroneous data downstream.
- Metadata Capture: Comprehensive metadata — data about the data — is captured during ingestion. This includes source system information, ingestion timestamp, data format, schema details, and any applied transformations. This metadata is vital for understanding data context and for data discovery.
- Data Lineage Tracking: The ingestion layer plays a foundational role in establishing data lineage. It meticulously records the origin of data, the path it takes, and any initial operations performed on it. This traceability is crucial for auditing, compliance, debugging, and understanding the impact of data changes.
Primary AI/ML Integration: Smart Ingestion for Intelligent Systems
The modern Ingestion Layer is increasingly intelligent, integrating AI/ML capabilities to enhance its efficiency and reliability:
- Automated Data Schema Inference: For unstructured or semi-structured data, AI/ML models can automatically infer schemas, saving significant manual effort and adapting to evolving data formats. This makes it easier to onboard new data sources quickly.
- Anomaly Detection in Ingestion Flows: Machine learning algorithms can monitor ingestion patterns, identifying unusual spikes in volume, unexpected drops in data velocity, or sudden shifts in data types. Early detection of such anomalies allows teams to address issues before they impact downstream analytics or applications.
Challenges and Barriers to Adoption
Despite its importance, implementing and maintaining a robust Ingestion Layer presents several hurdles:
- The “3 Vs”: Volume, Velocity, Variety: Scaling the ingestion infrastructure to handle ever-growing data volumes, processing data in near real-time, and accommodating an increasing diversity of data formats and sources is a constant engineering challenge.
- Schema Evolution and Data Drift: Source systems often change their data schemas without warning, leading to data drift and breaking downstream processes. Designing flexible and resilient ingestion pipelines that can automatically adapt or gracefully handle schema changes is complex.
- Ensuring Data Quality and Reliability at Scale: Implementing robust data validation, error handling, and reprocessing mechanisms across hundreds or thousands of ingestion pipelines without becoming an operational nightmare requires significant effort and sophisticated tooling.
- Security and Compliance during Data Transfer: Ensuring data is encrypted in transit, access controls are enforced, and regulatory compliance (e.g., GDPR, CCPA) is met during the initial transfer of data from various sources is paramount and can be technically demanding.
- Complexity of Managing Diverse Connectors: Building and maintaining connectors for every potential data source is resource-intensive. Keeping them updated with API changes and new data formats adds to the operational overhead.
Business Value and ROI: Fueling Data-Driven Success
A well-architected Ingestion Layer delivers tangible business value and a significant return on investment:
- Reliable Foundation for Analytics and Business Intelligence: By ensuring a continuous flow of clean, timely, and complete data, it provides a trustworthy basis for accurate reports, dashboards, and operational analytics, leading to better decision-making.
- Enabling Real-time Decision Making: With effective stream ingestion, businesses can react to events as they happen, personalizing customer experiences, detecting fraud, or optimizing supply chains in real time.
- Improved Data Quality for AI/ML Models: High-quality data ingested effectively reduces the “garbage in, garbage out” problem for machine learning models, leading to more accurate predictions and better model performance.
- Reduced Operational Costs through Automation: Automated data ingestion pipelines minimize manual effort, reduce errors, and free up data engineers to focus on more strategic tasks.
- Faster Time-to-Insight: By streamlining data acquisition, the Ingestion Layer significantly reduces the latency from data generation to data analysis, accelerating the pace of innovation and competitive response.
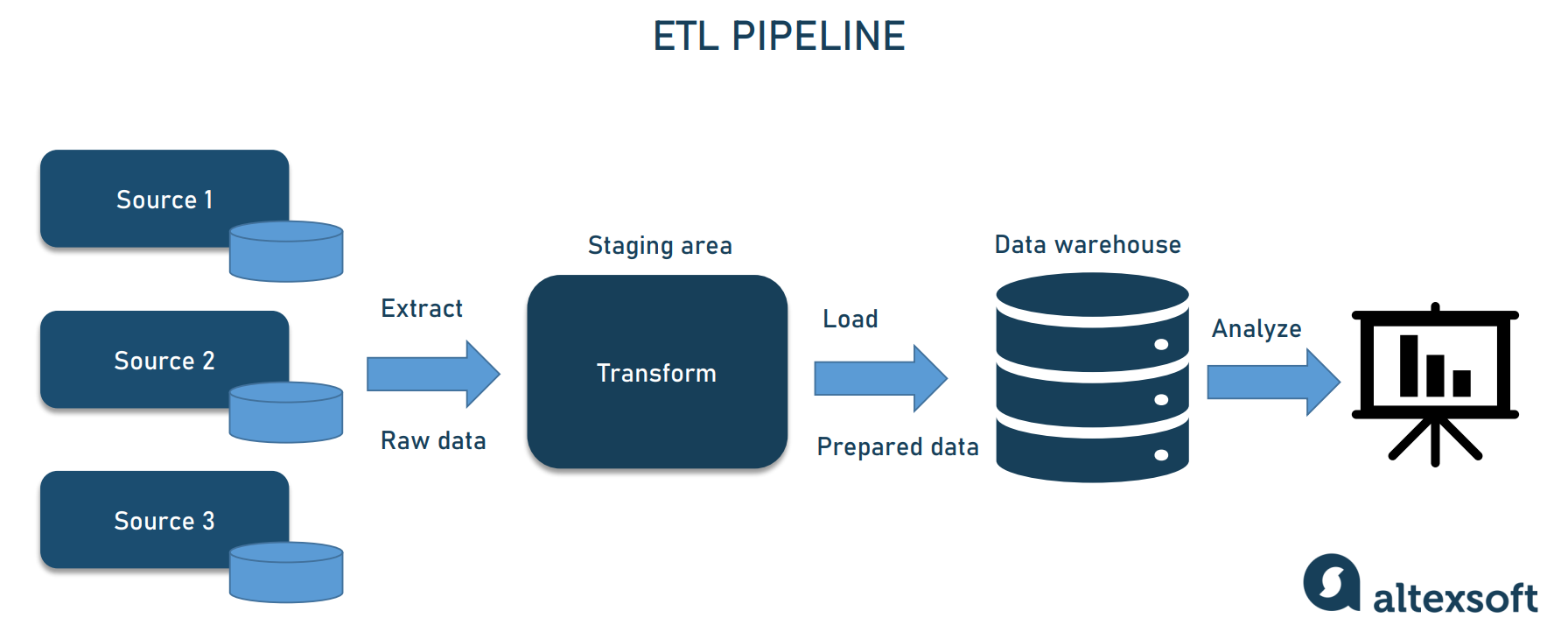
Comparative Insight: Ingestion Layer vs. Traditional Data Architectures
While the concept of bringing data into a system is not new, the modern Ingestion Layer distinguishes itself significantly from older paradigms like simple ETL (Extract, Transform, Load) processes or the basic data loading mechanisms of traditional data warehouses. Historically, data ingestion was often tightly coupled with transformation and loading, primarily focused on structured data and batch processing. A traditional data warehouse might have a nightly batch ETL job pulling data from an operational database, with predefined schemas and transformations.
The contemporary Ingestion Layer, as a dedicated Data Integration Component, operates differently. It prioritizes the efficient and resilient capture of data, often deferring complex transformations to later stages (ELT – Extract, Load, Transform). This approach aligns perfectly with the data lake philosophy, where raw, untransformed data is stored first, providing maximum flexibility for future use cases. The Ingestion Layer’s key differentiators include:
- Decoupled Architecture: It separates the concerns of data acquisition from data storage, processing, and analysis. This modularity allows for independent scaling and evolution of each component within the overall Data Pipeline.
- Support for Diverse Data Types: Unlike traditional systems focused on relational databases, modern ingestion handles structured, semi-structured (JSON, XML), and unstructured (text, images, audio) data with equal facility, often delivering it to schema-on-read data lakes.
- Real-time Capabilities: The emphasis on stream processing (Apache Kafka, AWS Kinesis, Google Cloud Pub/Sub) enables immediate data capture, a capability largely absent in traditional batch-oriented ingestion.
- Cloud-Native Scalability: Leveraging cloud services allows for elastic scaling to handle unpredictable data bursts, a stark contrast to the fixed capacities of on-premise traditional systems.
Furthermore, the competitive landscape for ingestion technologies highlights this evolution. Tools like Apache Kafka and AWS Kinesis are stream-first platforms, excellent for high-throughput, low-latency ingestion. Fivetran and Stitch specialize in automated, managed API integrations and CDC for hundreds of SaaS applications and databases, simplifying the extraction process significantly. Airbyte offers a similar open-source approach, providing extensive connectors. These modern alternatives move beyond generic scripts or proprietary ETL tools, offering specialized, scalable, and often managed services designed for the complexities of today’s data ecosystems. They embody the shift towards making the initial entry point of data into the platform as seamless, robust, and governed as possible.
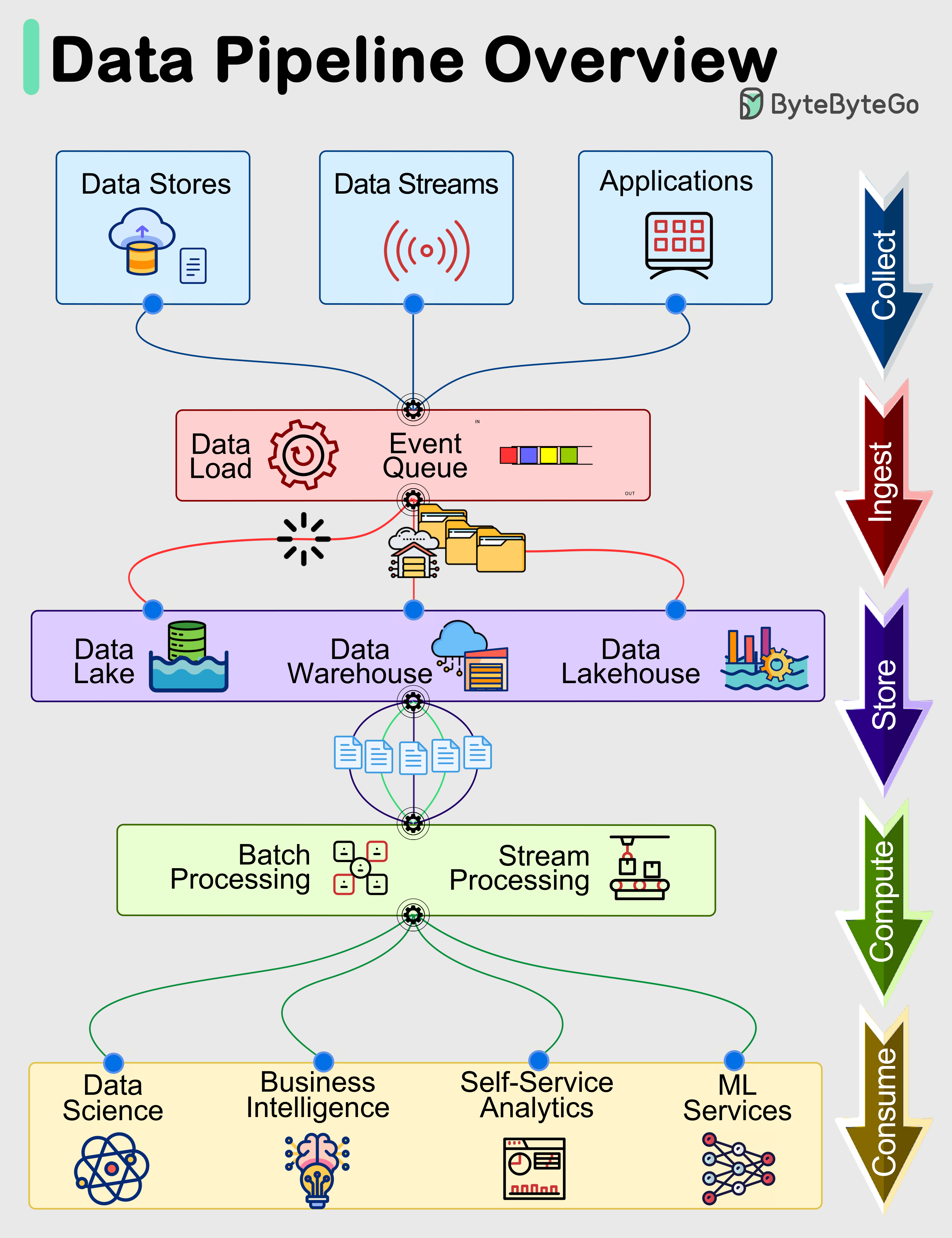
World2Data Verdict: The Unseen Architect of Data Success
The Ingestion Layer, often operating discreetly behind the scenes, is undeniably the unseen architect of modern data success. Its strategic importance will only amplify as businesses continue to grapple with escalating data volumes, increasing demand for real-time insights, and the intricate needs of AI/ML applications. World2Data.com believes that organizations must invest strategically in building resilient, scalable, and intelligent ingestion capabilities, moving beyond rudimentary data transfer to a comprehensive system that embeds data quality validation, metadata capture, and schema adaptability at its core. Future innovations in the Ingestion Layer will likely focus on even greater automation, leveraging advanced AI for predictive anomaly detection and self-healing pipelines, ensuring that every Data Pipeline starts strong and remains reliable. Prioritizing this foundational element is not merely a technical choice; it is a critical business imperative for any enterprise striving for true data mastery.

{kind=link}